
Yours Ever, Data Chronicles
[kaggle] Bike Sharing Demand: ML 성능 개선 3편 (머신러닝 결측치 처리) 본문
[kaggle] Bike Sharing Demand: ML 성능 개선 3편 (머신러닝 결측치 처리)
Everly. 2022. 7. 3. 08:10이번 포스팅은 캐글 Bike Sharing Demand(자전거 수요예측) 프로젝트의 마지막 포스팅이다.
저번 포스팅에서는 타겟을 count로 바꾸고, season과 month 중 더 유의미한 변수를 선택하는 등의 성능 개선을 통해 0.379까지 스코어를 올렸다!
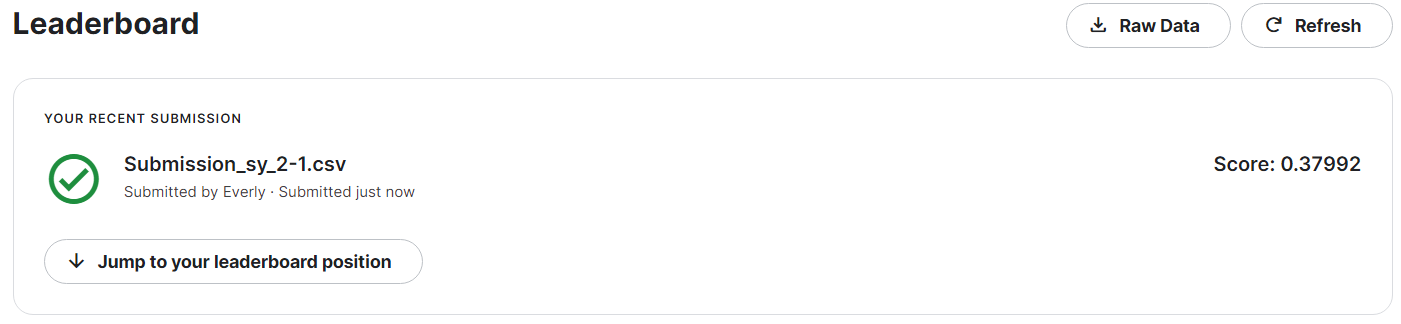
이번 포스팅에서는 좀 더 스코어를 올리기 위해, windspeed 변수를 건드려볼 것이다.
이번에는 이 변수를 아예 제거하거나 0을 처리해주었을 때 스코어가 어떻게 변하는지를 알아보자!
NOTE: 앞의 포스팅과 중복되는 코드가 많아 필요한 코드만 포스팅하였습니다. 전체 코드는 이 깃허브의 v.4, v.5 참고하세요!
✔Table of Contents
ver.4 windspeed 변수 drop
이전 포스팅 결과에 따라, target은 count를, 변수들 중에선 month를 제거하고 머신러닝을 진행한다.
처음에 했던 EDA 포스팅을 참고하면, windspeed(풍향) 변수가 count와 약한 정비례 관계를 보이고 있었으며 0도 너무 많았다.
머신러닝 모델은 의미 없는 변수를 포함해 모델링을 하면 성능이 좋지 않으므로, 이번에는 windspeed 변수를 아예 삭제해버리고 모델링을 진행해보자.
#불필요한 열 삭제
del train['windspeed']
앞에서 했던 것과 데이터 전처리 및 모델링 과정은 똑같으니 생략한다.
모델링으로는 LGBM 모델의 성능이 가장 좋았다.
X_df = train.drop(['count'], axis = 1)
y_df = train['count']
#하이퍼 파라미터 튜닝
pipeline = Pipeline([('scaler', MinMaxScaler()), ('lgbm',LGBMRegressor(objective='regression', learning_rate = 0.1, subsample = 0.5))])
params={'lgbm__max_depth': [10, 15],
'lgbm__reg_lambda':[0.1, 1],
'lgbm__n_estimators': [200, 300]}
grid_model = GridSearchCV(pipeline, param_grid=params, scoring='neg_mean_squared_error', cv=5, n_jobs = 5, verbose=True)
grid_model.fit(X_df, y_df)
print("MSLE: {0:.3f}".format( -1*grid_model.best_score_))
print('optimal hyperparameter: ', grid_model.best_params_)
하이퍼파라미터 튜닝까지 마친 뒤 train MSLE는 0.177이다.
이제 test data에 대해 예측하자. 여기서도 windspeed 변수를 제거해준다.
del test['windspeed']
마찬가지로 스케일링, 모델 학습 등을 거쳐 count 를 예측하였다.

최종 결과는 0.38364로, 앞에서 season 변수만 제거했던 스코어 0.37992 보다 더 성능이 안좋아졌다.
windspeed가 약한 정비례 관계를 보이긴 하지만, 그래도 아예 없애버리는 것보다는 사용하는 것이 더 좋다는 결론이다.
ver.5 windspeed 변수 보완 (머신러닝 결측치 처리)
이번에는 windspeed를 그대로 사용하되, 많은 0을 어떻게 처리할지를 고민해보았다.
먼저 train data와 test data에서 windspeed 변수가 0인 비율이 어느 정도인지를 구해보자.
print('train data에서 windspeed 0의 비율:' , round((len(train.loc[train['windspeed']==0]) / len(train))*100 , 2), '%')
print('test data에서 windspeed 0의 비율:' , round((len(test.loc[test['windspeed']==0]) / len(test))*100 , 2), '%')
무려 0의 비율은 train data는 12%, test data는 13%였다.
이번에는 train data에서 windspeed 변수는 어떤 값들을 갖고 있는지를 알아보았다.
train.groupby('windspeed')['windspeed'].count()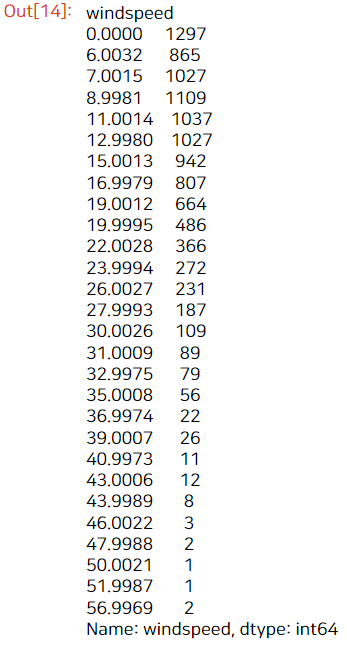
신기하게도, 값 자체는 소수점까지 있어서 연속형 데이터일 것 같지만 같은 값이 여러 개 존재하는 범주형(순서형) 데이터로 봐야 했다.
위의 결과를 시각화해보자. 범주형 데이터이므로 seaborn의 countplot을 사용했다.
fig, axs = plt.subplots(2,1, figsize = (15, 11))
ax1, ax2 = axs.flatten()
sns.countplot(train['windspeed'], ax = ax1)
ax1.tick_params('x', rotation=30)
sns.countplot(test['windspeed'], ax = ax2)
ax2.tick_params('x', rotation=30)
ax1.set_xlabel('Train set')
ax2.set_xlabel('Test set')
plt.show()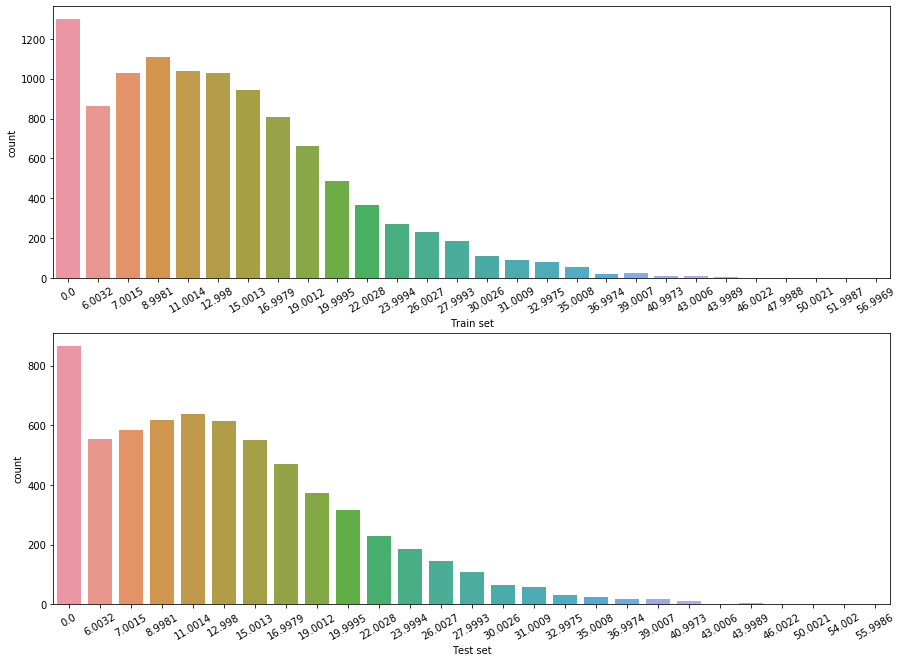
위는 train, test set에서 windspeed의 분포이다. 0의 값이 가장 많은 것이 눈에 띈다.
참고로 코드에 대해 설명하자면, tick_params 메서드를 사용해 rotation(각도)만큼 x축의 눈금 라벨을 회전시킬 수 있다. 소수점까지 있어서 회전하지 않으면 x축의 라벨들끼리 엄청 겹쳐 보이기 때문에 30도 회전하였다.
머신러닝 결측치 처리 (Classification imputation)
여기서 0의 값이 너무 많다는 것이 좀 이상했다. 진짜로 풍향이 0일 수도 있지만, 너무 값이 많다.
혹시 집계가 불가능한 경우 전부 0으로 처리한 것이 아닐까? 그렇게 되면 0을 결측치로 볼 수 있다.
이전에 파이썬에서 결측치를 처리하는 방법을 포스팅하였는데, 범주형 데이터이므로 0의 값을 보간법 처리할 수는 없었다. 또한 0인 행을 모두 drop해버리면 12%의 데이터가 삭제되기 때문에 그럴 수도 없었다.
그래서 이번에는 머신러닝을 활용해 결측치를 처리해보기로 했다.
※ 머신러닝 결측치 처리란?
이 방법은 결측치를 처리할 때, 데이터셋을 결측치인 부분과 결측치가 아닌 데이터 2개로 쪼갠 후
결측치가 없는 데이터셋으로 머신러닝 모델 학습을 시킨 뒤, 결측치에 대한 예측을 수행하는 것이다.
이는 데이터 내의 다른 변수를 기반으로 결측치를 예측하는 것이므로 변수 간 관계는 보존 가능하나, 예측치 간 variablity는 보존하지 못한다는 단점이 있다.
→ 이를 활용하여, windspeed가 0인 것을 결측치로 간주한다.
그래서 windspeed가 0이 아닌 데이터만 뽑아(df_nonzero), 이 데이터로 먼저 학습을 시킨다. (target: windspeed)
이렇게 만들어진 모델로 windspeed가 0인 데이터(df_zero)의 windspeed에 대해 예측한다.
이를 이미지로 나타내보면 다음과 같다.

이러한 방법을 쓰면 train data의 windspeed에 있는 모든 0이 사라진다는 문제가 있다.
test data의 windspeed도 13%의 0이 있으므로, 모든 0을 없앤 상태에선 제대로 예측을 하지 못한다는 문제가 있다.
그래서 나는 train data의 모든 windspeed가 0인 것이 아닌, 절만의 0만 대체시키기로 했다.
즉 12%가 0이므로, 6%의 0 값만 랜덤하게 뽑아서 사용할 것이다. 이제부터는 코드로 알아보자.
df = train.copy()
df_zero = df[df['windspeed'] == 0]
print(len(df_zero))
# 이 중에서 644개 정도는 그냥 0으로 둔다. sample 함수 사용
df_zero_keep = df_zero.sample(round(len(train)*0.06), random_state = 99)
print(len(df_zero_keep))
먼저 train을 카피하여 df 라는 새로운 데이터프레임을 만든다.
windspeed가 0인 것을 'df_zero' 라는 데이터프레임으로 한다. 얘는 1297개이다.
여기서 랜덤하게 6% 개수(644개)만큼 파이썬 sample 함수를 사용해 뽑는다. (random_state를 설정해야 실행 시마다 같은 인덱스가 뽑힘)
이렇게 뽑힌 'df_zero_keep(644개)' 은 예측에 사용하지 않고 그대로 0으로 둘 것이다.
# 나머지만 예측에 필요한 것으로 가져오기
df_zero1 = df_zero.reset_index()
df_zero_keep1 = df_zero_keep.reset_index()
df_zero_use = df_zero1.loc[~df_zero1['index'].isin(df_zero_keep1['index'].tolist())]
df_zero_use.set_index(['index'], inplace = True)
print(len(df_zero_use))
display(df_zero_use.head(3))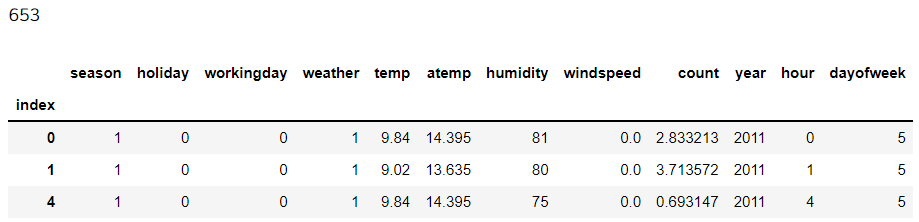
다음으로는 예측에 사용할 나머지 데이터를 df_zero에서 뽑는다.
df_zero에서 df_zero_keep의 인덱스에 해당하지 않는 데이터만 뽑아 'df_zero_use'로 만든 것이다.
위 코드를 실행하면 df_zero_use는 인덱스가 없어서, index 열을 인덱스로 설정해주었다.
이제 df_zero_use(653개)는 예측에 사용한다.
# 학습할 데이터셋
df_nonzero = df[df['windspeed'] != 0]
print(len(df_nonzero))
df_nonzero.dtypes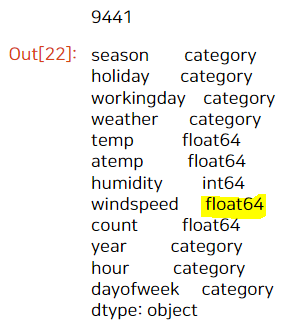
그리고 windspeed가 0이 아닌 데이터 'df_nonzero' (9441개)는 학습에 사용한다.
컬럼별 type을 dtypes로 뽑으면, windspeed가 float로 되어 있다.
그러나 windspeed는 앞에서도 설명했지만 수치형 데이터가 아닌 범주형 데이터이다. 그러므로 str 형태로 바꾸자.
# 분류로 봐야하므로 df_nonzero의 windspeed 스트링으로 변경
df_nonzero['windspeed'] = df_nonzero['windspeed'].astype('str')
df_nonzero.dtypes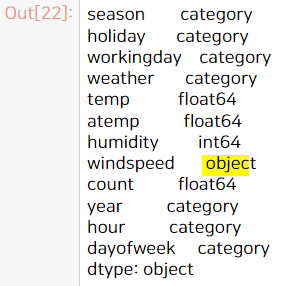
예측 모델로는 랜덤포레스트 분류기(RandomForestClassifier)를 사용하였다.
파라미터를 사용하지 않고 그냥 디폴트로만 사용하고, 예측에 사용할 변수는 그냥 직관적으로 풍향에 관련이 있을 만한 season, weather, temp, atemp, humidity, year 변수를 사용했다.
- 학습에 사용: df_nonzero
- 예측에 사용: df_zero_use → windspeed 값 예측
- df_zero_keep은 windspeed를 0으로 유지
from sklearn.ensemble import RandomForestClassifier
# 모델
rf_wind = RandomForestClassifier()
# 학습
rf_wind.fit(df_nonzero[['season', 'weather', 'temp', 'atemp', 'humidity', 'year']], df_nonzero['windspeed'])
# 예측
pred = rf_wind.predict(df_zero_use[['season', 'weather', 'temp', 'atemp', 'humidity', 'year']])
이렇게 하여 windspeed 예측값이 pred 변수에 저장되었다.
이제 df_zero_use의 windspeed 값이 얼마가 나왔는지 알아보자.
# 새로운 데이터프레임 생성
df_zero_new = df_zero_use.copy()
df_zero_new['windspeed'] = pred
df_zero_new.head()
원래는 0이었는데 새로운 값들로 잘 채워졌다.
그럼 이제 모든 데이터셋 3개를 합친다.
# 3개 데이터셋 합치고 다시 train으로 저장
train = pd.concat([df_zero_new, df_zero_keep, df_nonzero], ignore_index = True)
print('train data에서 windspeed 0의 비율:' , round((len(train.loc[train['windspeed']==0]) / len(train))*100 , 2), '%')
display(train.head())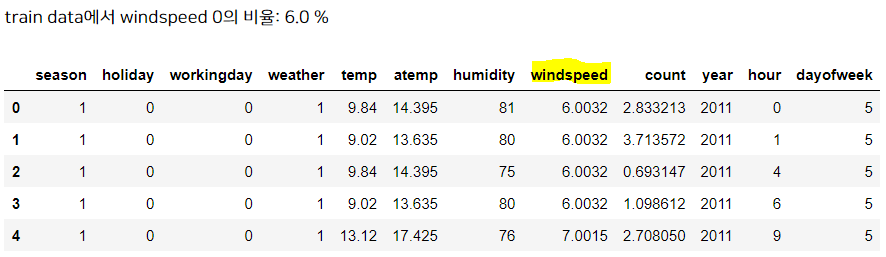
새로운 train 데이터가 만들어졌으며, 아까는 0의 비율이 약 12%였는데 지금은 6%로 줄어들었다.
마지막으로 windspeed의 값은 원래 float형이었으므로 바꿔준다.
# 다시 windspeed 값을 float로 변경
train['windspeed'] = train['windspeed'].astype('float')
train.dtypes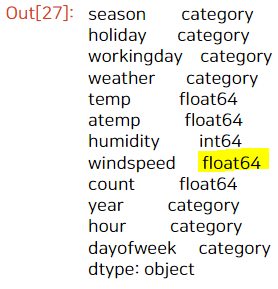
이제 모두 완료되었으니 다시 train의 windspeed를 시각화하면?
plt.figure(figsize = (15, 6))
sns.countplot(train['windspeed'])
plt.xticks(rotation=30)
plt.xlabel('Train set')
plt.show()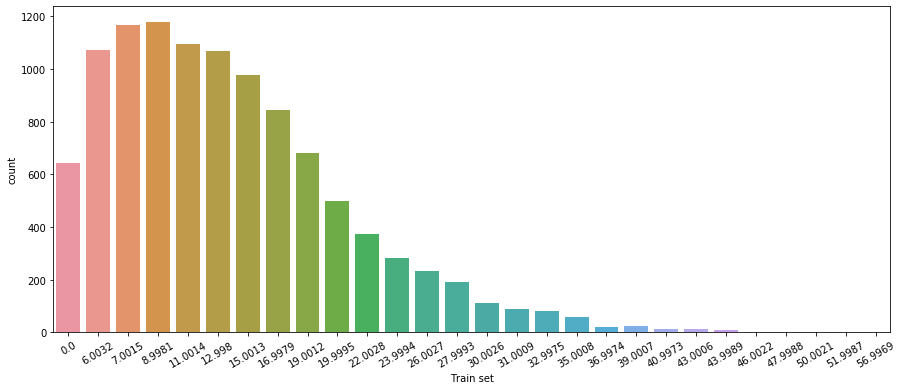
이렇게 0의 값이 꽤 줄어든 것을 확인하였다 :)
이렇게 train data의 windspeed 값을 보완해주었다.
전처리와 모델링 부분은 앞의 포스팅과 똑같으니 설명은 생략한다.
모델은 LGBM을 사용하였다.
#하이퍼 파라미터 튜닝
pipeline = Pipeline([('scaler', MinMaxScaler()), ('lgbm',LGBMRegressor(objective='regression', learning_rate = 0.1, subsample = 0.5))])
params={'lgbm__max_depth': [5, 7],
'lgbm__reg_lambda':[0.1, 1],
'lgbm__n_estimators': [200, 300]}
grid_model = GridSearchCV(pipeline, param_grid=params, scoring='neg_mean_squared_error', cv=5, n_jobs = 5, verbose=True)
grid_model.fit(X_df, y_df)
print("MSLE: {0:.3f}".format( -1*grid_model.best_score_))
print('optimal hyperparameter: ', grid_model.best_params_)
LGBM 모델 하이퍼 파라미터 튜닝을 하면, train MSLE는 0.111로 지금까지 사용한 모든 모델 중에서 train MSLE가 가장 작다.
과연 test (R)MSLE 값도 가장 작게 나올까?
test data에 대해 전처리하고 최종 파라미터 튜닝된 모델을 사용한다. (앞 포스팅에서 했던 것과 똑같은 과정이므로 설명 생략)
그리고 최종 제출해보았다!
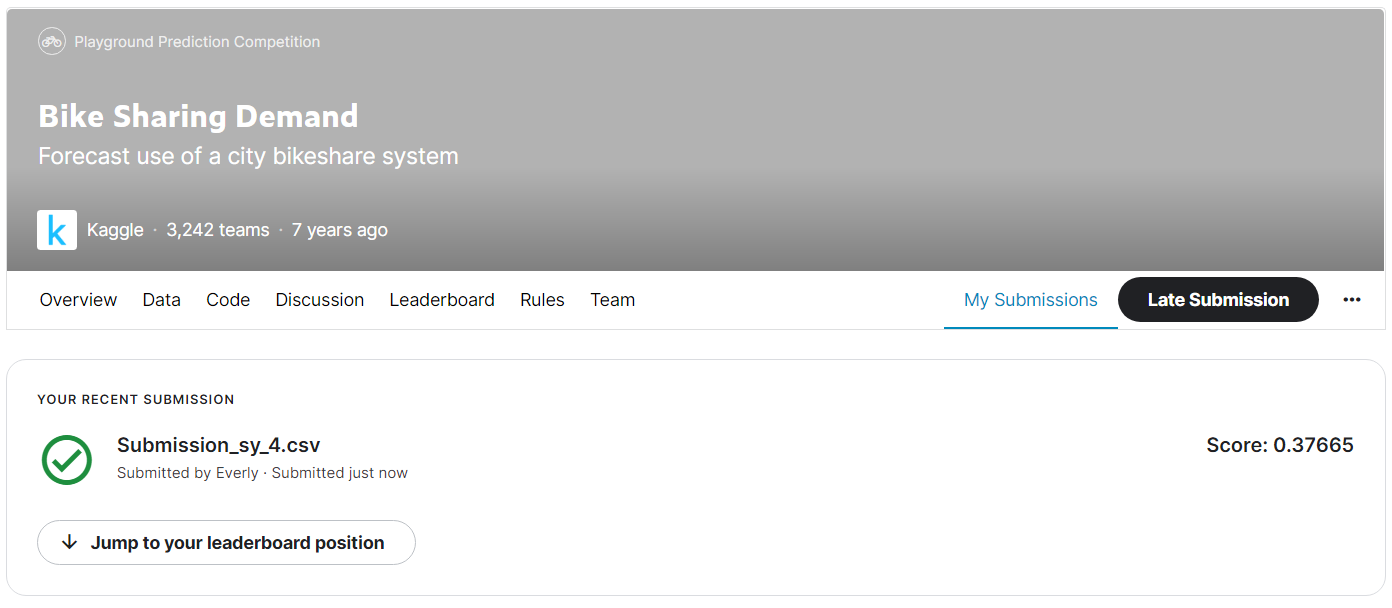
결과는 지금까지 나온 test score 중 가장 좋은 점수였다! 👏
0.376으로, 이 점수면 참여한 3천여 개의 팀 중에서 100등 안에 드는 점수이다. (참고로 1등의 점수는 0.337)
이렇게 해서 <Bike Sharing Demand: 자전거 수요 예측> 프로젝트를 마친다.
처음 도전해본 캐글 프로젝트였는데, 많은 것을 배울 수 있었던 프로젝트였던 것 같다 :)
결과적으로 windspeed의 0의 값을 보완함으로써, 스코어 0.379 → 0.376으로 보완할 수 있었다.
전체 코드는 저의 깃허브를 참고하시길 바라며, 궁금한 점이 있거나 틀린 부분이 있다면 언제든 댓글 환영합니다 :)
감사합니다 !
참고 링크
'Data Science > Kaggle' 카테고리의 다른 글
| [kaggle] 범주형 데이터 분석 프로젝트 - EDA 2편 (0) | 2022.07.15 |
|---|---|
| [kaggle] 범주형 데이터 분석 프로젝트 - EDA 1편 (2) | 2022.07.14 |
| [kaggle] Bike Sharing Demand: ML 성능 개선 2편 (변수 선택) (0) | 2022.07.02 |
| [kaggle] Bike Sharing Demand: ML 성능 개선 1편 (Ridge, Random Forest, LGBM) (0) | 2022.07.01 |
| [kaggle] Bike Sharing Demand: Baseline Model 2편 (pipeline, k-fold, scaling) (0) | 2022.06.30 |



