
Yours Ever, Data Chronicles
[kaggle] Bike Sharing Demand: Baseline Model 2편 (pipeline, k-fold, scaling) 본문
[kaggle] Bike Sharing Demand: Baseline Model 2편 (pipeline, k-fold, scaling)
Everly. 2022. 6. 30. 19:21저번 포스팅에선 모델링을 위한 데이터 전처리를 진행하였다. 이번 포스팅에선 직접 Baseline 모델을 만들어보자.
✔Table of Contents
3. Modeling
모델링을 하기 전에는 스코어를 집계하는 metric, 즉 지표로는 무엇을 사용하는지를 반드시 알아야 한다.
캐글에서 확인하면, 이 대회에서는 RMSLE를 사용한다고 되어 있다.

사이킷런(scikit-learn)을 활용하면 지표를 구하는 metric이 이미 구현되어 있다. MSE를 구하는 metric인데, RMSE 또한 MSE에 루트를 씌운 값이므로 MSE를 구한 후 np.sqrt로 루트만 씌워주면 된다.

sklearn.metrics.mean_squared_error
Examples using sklearn.metrics.mean_squared_error: Gradient Boosting regression Gradient Boosting regression, Prediction Intervals for Gradient Boosting Regression Prediction Intervals for Gradient...
scikit-learn.org
참고로 MSE 구하는 것은 metrics.mean_squared_error를 사용하면 된다.
그러나 MSLE를 구해주는 metric은 없다. 그래서 직접 함수를 만들어 MSLE를 계산하는 방법도 있지만,
어차피 앞에서 target에 np.log1p를 적용하여 로그변환을 시켜주었다.(이 함수는 log(x)가 아닌, log(x+1)을 반환함) 그래서 이 상태에서는 그냥 MSE를 구하면 이것이 MSLE가 된다고 봐도 무방하다.
캐글에서 제시한 지표는 RMSLE이므로 MSLE를 구한 값에 np.sqrt로 루트를 씌워주면 된다.
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.linear_model import LinearRegression, Ridge
from xgboost import XGBRegressor
from sklearn.ensemble import RandomForestRegressor
from lightgbm import LGBMRegressor
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import cross_validate
from sklearn.model_selection import GridSearchCV
from sklearn.pipeline import Pipeline, make_pipeline3-1. casual 예측 모델
casual 예측 모델엔 앞에서 만들었던 train_c 데이터를 사용한다.
먼저 변수들과 target 값을 나눠 각각 X_c, y_c 데이터를 만든다.
# X, y 나누기
X_c = train_c.drop(['casual'], axis = 1)
y_c = train_c['casual']
그리고 모델링으로 넘어가기 전에, 수치형 변수인 temp, atemp, humidity, windspeed 에 스케일링(Scaling)을 하는 방법을 알아보자.
앞에서 이런 수치형 변수들에는 아무런 전처리도 하지 않았었다. 스케일링을 해주지 않으면 변수들 간에 값의 범위가 많이 차이가 나는 경우 (예를 들어 어떤 변수는 0~1의 값을 갖는데, 어떤 변수는 10~100의 값을 갖는 경우) 두 변수의 범위가 다른 것일 뿐인데도 더 값이 큰 변수를 중요하게 인식할 수 있다.
스케일러의 종류는 여러 가지가 있는데, 그 중 가장 대표적인 것들은 Standard Scaler(표준화), MinMax Scaler(정규화) 등이 있으며, 사이킷런에서 관련 스케일러를 제공하고 있다.
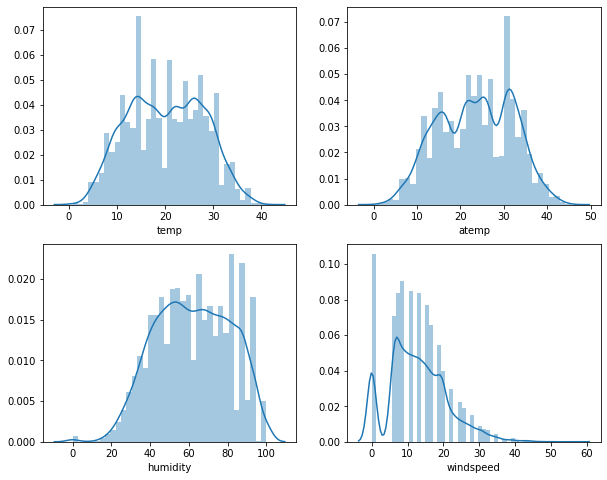
기존의 수치형 변수들 4개는 위와 같은 분포를 갖고 있다. 값 범위가 비교적 비슷한 편이지만,
평균을 0, 분산을 1로 갖는 정규분포로 만들기 위한 표준화를 시켜주었다고 해보자. StandardScaler를 사용하였다.
# 예를 들어 StandardScaler를 사용한다면
train_cons = train[['temp', 'atemp', 'humidity', 'windspeed']]
from sklearn.preprocessing import StandardScaler
ss= StandardScaler()
t_scaled = ss.fit_transform(train_cons) #array형태
t_scaled = pd.DataFrame(t_scaled)
# 스케일링 후 연속형 변수 분포
fig, axs = plt.subplots(2,2, figsize = (10,8))
ax1, ax2, ax3, ax4 = axs.flatten()
sns.distplot(t_scaled[0], ax = ax1)
sns.distplot(t_scaled[1], ax = ax2)
sns.distplot(t_scaled[2], ax = ax3)
sns.distplot(t_scaled[3], ax = ax4)
결과를 보면 분포 자체는 크게 달라진 점이 없으나, x축을 살펴보면 이 값의 범위가 달라졌음을 확인할 수 있다.
사실 반드시 이런 스케일링을 시켜줘야 할 필요는 없다. 이 데이터셋의 경우에는 범위가 원래 큰 차이가 나지 않았기 때문에 굳이 시켜주지 않아도 무방하다.
하지만 학습의 목적으로! 여러 가지 스케일러를 써보기로 하였다. 여기선 3개 정도의 스케일러를 사용했다.
- StandardScaler() : 특성들의 평균을 0, 분산을 1로 스케일링함. 표준화라고 하며, 특성들을 정규분포로 만듦.
- 평균 0, 분산 1으로 만들 뿐, 최댓값과 최솟값의 크기는 제한하지 않는다.
- 그래서 이상치에 매우 민감하며, 회귀보단 분류에 자주 사용
- MinMaxScaler() : 특성들의 범위를 모두 0과 1 사이값으로 만듦. 정규화라고 한다.
- 이상치에 매우 민감하며, 분류보다 회귀에 자주 사용
- RobustScaler() : 평균,분산 대신 중간값과 사분위값을 사용하는 스케일러.
- 이상치가 많은 경우 유용하게 사용할 수 있음.
전처리를 했을 때 이상치를 제거하기도 했고, 위의 분포를 봤을때 이상치가 많진 않으므로 Standard 또는 MinMax를 쓰는 게 적합해 보인다.
그리고 회귀 예측모형을 만들고 있으므로 MinMax가 가장 적합할 듯.
모델링: k-fold와 스케일링을 한번에
여기서는 기본 모델로 가장 기본적인 선형 회귀(Linear Regression)을 사용하였다.
#선형회귀 모델
lr_reg = LinearRegression()
그리고 학습할 데이터로는 앞서 만든 X_c와 y_c를 만드는데, 이것을 전부 학습에 사용해버리면 모델의 성능이 어떤지를 알 수가 없다.
train data가 1만여개 정도이므로, train_test_split을 하여 학습에 사용할 train set / 검증에 사용할 validation set으로 나눌 수도 있지만, 나는 좀 더 학습에 많은 데이터를 할당하고자 k-fold를 사용하였다.
하지만 k-fold를 할 때는 주의점이 있다. 바로 검증셋(validation set)이 전처리(스케일링) 단계에서 누설되면 안 된다는 것이다.
이게 무슨 말일까?
k-fold라는 것은 폴드를 k개만큼 나누어 학습과 검증을 반복한다는 뜻이다.
예를 들어 k가 5개인 경우, 폴드 1을 검증셋 - 나머지는 학습셋, 폴드 2를 검증셋 - 나머지는 학습셋, .... , 폴드 5를 검증셋 - 나머지는 학습셋 이렇게 사용한다. 밑의 그림으로 보면 더 이해가 쉬울 것이다.
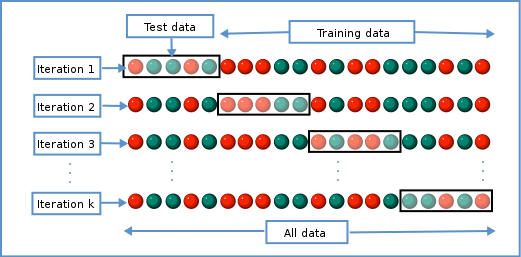
그런데 우리는 스케일링도 같이 하려고 하고 있다. 예를 들어 표준화 스케일링을 한다고 하면, 전체 데이터의 평균치와 표준편차 값을 구해 각 데이터에 빼주고 나눠줘야 한다. (참고로 스케일링을 한다는 것은 학습셋의 분포값을 학습하고(fit), 이 학습된 스케일러를 학습셋과 검증셋에 적용(transform)한다. 검증셋의 분포는 학습되면 안 된다. 검증셋은 테스트용이니까!)
만일 train_test_split으로 학습셋과 검증셋이 이분화되어 있다면 전체 학습셋의 평균과 표준편차를 구하고, 이를 검증셋에 적용해 표준화를 해주면 될 것이다.
하지만 k-fold를 할 때엔 이렇게 할 수가 없다. train data 전체에 학습셋과 검증셋이 같이 들어있고, 폴드별로 어떤 때는 학습셋이 되었다가 어떤 때는 검증셋이 되기 때문이다.
이런 상황에서 전체 train data를 스케일링해버리면 검증셋의 분포가 스케일러에 녹아들어가게 된다.
→ 이럴 때 사용해주는 것이 바로 파이프라인(pipeline) 객체이다.
이 객체는 전처리 단계와 모델 클래스를 하나로 연결해주며, 검증셋 분포가 스케일링 전처리를 할 때 누설되지 않도록 해주는 역할을 한다.
그래서 스케일러와 모델을 make_pipeline으로 연결하고,
cross_validate를 사용하여 train data에 대해 k-fold를 사용하면 검증셋이 누설되지 않게 스케일링과 k-fold를 동시에 할 수 있다.
글로 설명하면 헷갈리니 코드로 구현해보자.
from sklearn.preprocessing import StandardScaler
#선형회귀 모델
lr_reg = LinearRegression()
#피처에 대해 표준화 진행과 k-fold를 함께 함
pipe = make_pipeline(StandardScaler(), lr_reg)
scores = cross_validate(pipe, X_c, y_c, cv=5, scoring='neg_mean_squared_error',return_train_score=True)
5-fold를 수행하였으며, scoring을 'neg_mean_squared_error'로 준 것은 MSE를 구하는 것이다.
target 값을 로그변환해서 구한 것이므로 MSLE를 구한 것이라고 볼 수 있다.
아무튼 사이킷런의 cross_validate를 활용해서 구한 scores는 각 폴드별로 MSE를 구하므로, 총 5개의 값이 나온다.
최종 MS(L)E를 구하기 위해선 이 5개 값의 평균을 구해주면 된다.
print("MSLE: {0:.3f}".format(np.mean(-scores['test_score'])))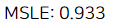
이렇게 하여 최종 MSLE는 0.933이 나왔다. 이 컴퍼티션에서 사용하는 지표는 RMSLE 이므로 np.sqrt를 씌워주면
np.sqrt(0.933)
약 0.96의 값이 나온다.
RMSLE는 오차를 의미하므로 작으면 작을수록 좋다. 0.96의 값이면 작은 편은 아니므로 좀 더 성능 개선을 할 필요성이 있다. (어차피 베이스라인 모델이니까, 다른 모델을 쓰면 더 성능이 좋아질 것이다!)
이번에는 표준화 스케일러가 아닌, MinMax 를 써보자.
from sklearn.preprocessing import MinMaxScaler
#선형회귀 모델
lr_reg = LinearRegression()
#피처에 대해 표준화 진행과 k-fold를 함께 함
pipe = make_pipeline(MinMaxScaler(), lr_reg)
scores = cross_validate(pipe, X_c, y_c, cv=5, scoring='neg_mean_squared_error',return_train_score=True)
print("RMSLE: {0:.3f}".format(np.sqrt(np.mean(-scores['test_score']))))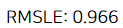
앞서 표준화 스케일러를 썼을 때와 같은 값이다. 하지만 선형회귀가 아닌 다른 모델에 대해 구해보면 값은 얼마든지 다르게 나올 수 있다.
3-2. registered 예측 모델
같은 방식으로 수행하면 된다. 이번에는 데이터셋으로 X_r, y_r을 사용했다.
# X, y 나누기
X_r = train_re.drop(['registered'], axis = 1)
y_r = train_re['registered']
MinMax 스케일러를 사용해 k-fold를 수행해보자.
from sklearn.preprocessing import MinMaxScaler
#선형회귀 모델
lr_reg = LinearRegression()
#피처에 대해 표준화 진행과 k-fold를 함께 함
pipe = make_pipeline(MinMaxScaler(), lr_reg)
scores = cross_validate(pipe, X_r, y_r, cv=5, scoring='neg_mean_squared_error',return_train_score=True)
print("RMSLE: {0:.3f}".format(np.sqrt(np.mean(-scores['test_score']))))
RMSLE는 1.031로 역시 그렇게 좋은 편은 아니다.
기본적인 선형회귀 모델은 딱히 성능이 좋진 않은 것 같다.(사실 당연하다)
다음 편에서는 모델을 바꿔가며 성능이 어떻게 달라지는지를 확인해보자.
'Data Science > Kaggle' 카테고리의 다른 글
| [kaggle] Bike Sharing Demand: ML 성능 개선 2편 (변수 선택) (0) | 2022.07.02 |
|---|---|
| [kaggle] Bike Sharing Demand: ML 성능 개선 1편 (Ridge, Random Forest, LGBM) (0) | 2022.07.01 |
| [kaggle] Bike Sharing Demand: Baseline Model 1편 (데이터 전처리) (2) | 2022.06.30 |
| [kaggle] Bike Sharing Demand: EDA 2편 (0) | 2022.06.25 |
| [kaggle] Bike Sharing Demand: EDA 1편 (6) | 2022.06.24 |



