
Yours Ever, Data Chronicles
[kaggle] Bike Sharing Demand: Baseline Model 1편 (데이터 전처리) 본문
[kaggle] Bike Sharing Demand: Baseline Model 1편 (데이터 전처리)
Everly. 2022. 6. 30. 14:24저번 포스팅에서 EDA를 통해, Bike Sharing Demand 프로젝트에 사용된 데이터가 어떻게 되어 있고, 변수 간에 어떤 관계가 있었으며, 어떤 변수를 머신러닝에 사용할 것인지에 대해 검토하였다.
저번 포스팅에서 발견한 정보들을 간략히 정리해보면 다음과 같다.
- 수치형 변수
- 온도(temp, atemp), 습도(humidity), 풍향(windspeed): 각각 대여량(target)과 정비례, 반비례, 정비례 관계
- 특히 hour별로 봤을 때, casual일 때 대여량과 상관성이 높았다.
- 카테고리 변수
- 시간 변수로는 연도(year), 월(month), 시간(hour), 요일(dayofweek)이 유의미했다.
- 분기(season), 날씨(weather), 평일(workingday), 공휴일(holiday): 각각 늦봄에서 초가을(2, 3사분기)일 때와 날씨가 화창(1일 때)할 때 대여량이 높아지는 경향.
- 특히 hour 변수는 다른 변수들과의 관계를 설명해주는 강력한 변수였다.
- 대여량의 대부분은 registered였으며, register : casual 비중은 8:2
이번 포스팅은 이러한 변수들을 가지고 가장 기본적인 Baseline Model을 만드는 데 목표를 두었다.
그리고 이 성능값을 기반으로, 조금씩 전처리나 변수선택을 통해 성능 개선을 시킬 것이다.
이번 포스팅의 목표가 Baseline 모델을 만드는 것이니만큼, 꼭 필요한 전처리만 하고, 그 다음 포스팅부터 성능이 어떻게 개선되는지 순차적으로 살펴보자.
NOTE: 전체 코드를 포함하면 포스팅이 길어져, 가독성을 위해 필요한 코드만 넣었습니다.
전체 코드는 깃허브(클릭)에서 다운받으실 수 있습니다 (이번 포스팅은 v.1 입니다!)
✔Table of Contents
1. Load the data
EDA 편에서 확인한 결과, 중복이나 결측치는 없었으므로 데이터만 불러온다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
#train data : target은 count
train = pd.read_csv('data/train.csv', parse_dates=['datetime'])
print(train.shape)
train.head()
# test data
test = pd.read_csv('data/test.csv', parse_dates=['datetime'])
print(test.shape)
test.head()

2. Preprocessing(데이터 전처리)
우리가 예측해야 하는 것은 바로 test data의 'count'(대여량) 열이다.
하지만 EDA를 통해, casual과 registered의 합계가 count라는 것을 알았고, casual일 때와 registered일 때의 데이터 현황의 양상이 달라지는 것으로 보아, 두개를 따로 분리하여 2개의 모델을 만들어보기로 했다.
그래서 최종 제출은 casual 예측값과 registered 예측값 두개를 합하여 count 예측값을 도출하는 방법을 사용했다.
데이터 전처리는 다음의 과정을 수행했다. 저번 EDA 편에서 발견한 것들은 길게 설명하지 않고 넘어가므로, 궁금하신 분들은 저번 포스팅을 참고하시길! :)
# train data 전처리 순서
1) datetime으로부터 필요한 열 생성: year, month, hour, dayofweek
2) weather이 4인 값을 제거 (아웃라이어)
3) count 열의 아웃라이어 제거: 3시그마를 초과하는 경우
4) 타겟인 casual, registered 열 각각에 대해 로그변환
5) 카테고리 변수 타입(type) 변경
6) 2개 데이터로 분할
1) 필요한 컬럼 생성
train['year'] = train['datetime'].dt.year
train['month'] = train['datetime'].dt.month
train['hour'] = train['datetime'].dt.hour
train['dayofweek'] = train['datetime'].dt.dayofweek
#불필요한 열 삭제
del train['datetime']
train.head(3)
2) weather이 4인 값(아웃라이어) 제거
print('제거 전 ', len(train))
train = train.loc[train['weather'] !=4]
print('제거 후: ', len(train))
3) count의 아웃라이어 제거
3시그마 값을 초과하는 경우 아웃라이어(이상치)로 간주하고 제거하였다.
train = train[train['count'] - train['count'].mean() < 3*train['count'].std()]
train.reset_index(inplace =True, drop = True)
print(train.shape)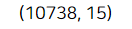
10,885개에서 10,738개로 많이 줄었다.
4) target인 casual, registered 열 로그변환
보통 머신러닝을 할 때는 target 값에 로그변환을 많이 시켜준다. 그 이유는 대부분의 target 분포가 정규분포를 따르지 않는데, 로그변환을 시키면 정규분포를 따르는 형태가 되는 경우가 많기 때문이다.
여기서는 예측할 타겟이 casual, registered 열이었으므로, 두 개 열의 분포를 먼저 확인하고 로그변환을 시킬지 결정하자.
# casual & registered 의 분포 파악
figure, (ax1, ax2) = plt.subplots(1,2, figsize = (10,5))
sns.distplot(train['casual'], ax = ax1)
sns.distplot(train['registered'], ax = ax2)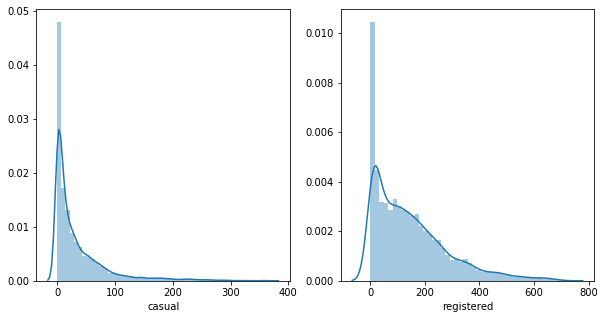
기존의 분포이다. 두 그래프 모두 왼쪽으로 치우친 형태를 보이므로, 로그변환을 하는 것이 좋겠다고 판단하였다.
로그변환은 numpy(넘파이)의 np.log1p를 사용하면 간단하게 만들 수 있으며, 주의할 점은 단위가 바뀌므로 나중에 test data에 대해 target을 예측한 후에 이 로그변환 값을 풀어줘야 한다는 것이다. 뒤에서 다시 설명하겠다.
# 로그변환 후
figure, (ax1, ax2) = plt.subplots(1,2, figsize = (10,5))
sns.distplot(np.log1p(train['casual']), ax = ax1)
sns.distplot(np.log1p(train['registered']), ax = ax2)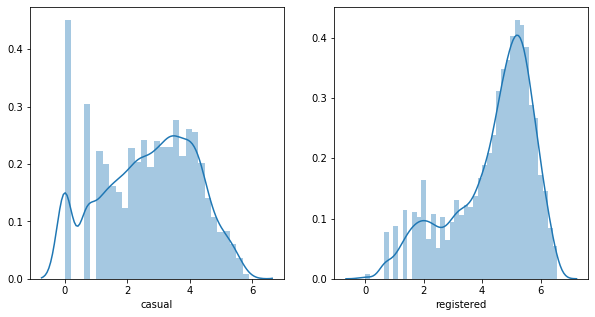
완벽한 정규분포의 형태는 아니지만, 정규분포에 좀 더 가까워졌다고 볼 수 있으므로 로그변환을 사용하기로 결정!
train['casual'] = np.log1p(train['casual'])
train['registered'] = np.log1p(train['registered'])
display(train.head())
# skew(왜도) 확인 : +- 2 범위 안에 들어가므로 치우침이 없다고 볼 수 있음
print(train['casual'].skew())
print(train['registered'].skew())
다음은 왜도(skew)를 확인하였다. 왜도의 값은 ±2 사이의 값을 가지면 치우침이 없다고 볼 수 있는데, 로그변환을 하고 난 후에 이 범위 안의 값에 들어가므로 현재 target 값은 치우침이 없다고 해석 가능하다.
5) 범주형 변수의 타입 변환
이 포스팅의 맨 앞에서 범주형 변수들(season, weather 등)에 대해 언급하였다. 이런 범주형(카테고리) 변수는 그냥 사용할 경우, 문자로 된 경우엔 머신러닝 모델이 인식을 못하고, 1,2,3,4 처럼 순서를 가진 숫자로 된 경우엔 숫자에 따라 값을 갖는 수치형 변수라고 머신러닝 모델이 인식하기 때문에 반드시 변환이 필요하다.
처음에는 더미 변수(dummy variable)로 만들어서 사용했다가, 너무 성능이 안 좋고 열 개수도 지나치게 많아진다는 단점이 있어서 타입을 category 형으로 변환하는 방법을 사용했다. 이렇게 타입을 변환하려면 astype 함수를 사용하면 된다.
cate_name = ['weather', 'season', 'year', 'month', 'hour', 'dayofweek']
for c in cate_name:
train[c] = train[c].astype('category')
train.dtypes
참고로, holiday와 workingday도 범주형 변수인데 왜 변환을 안 해주나요? 라고 묻는다면.. 그렇게 해도 되고 안 해도 된다.
그 이유는 이미 이 변수들은 0과 1로만 이루어진 더미변수 형태이기 때문!
실제로 두개를 category로 변환한 경우와 변환하지 않은 경우 모두 테스트해봤는데, 두 경우 모두 성능이 일치했다.
그리고 count 열은 지금 모델링에선 필요하지 않으므로 drop하였다.
#불필요 컬럼 삭제
train.drop(['count'], axis = 1,inplace =True)
6) 2개 데이터로 분할하기
마지막으로는 casual을 예측하는 모델 하나, registered를 예측하는 모델 하나 이렇게 만들 것이므로 데이터를 2개로 분할하였다.
train_c = train.drop(['registered'], axis = 1)
train_re = train.drop(['casual'], axis = 1)
print(train_c.shape, train_re.shape)
display(train_c.head(3), train_re.head(3))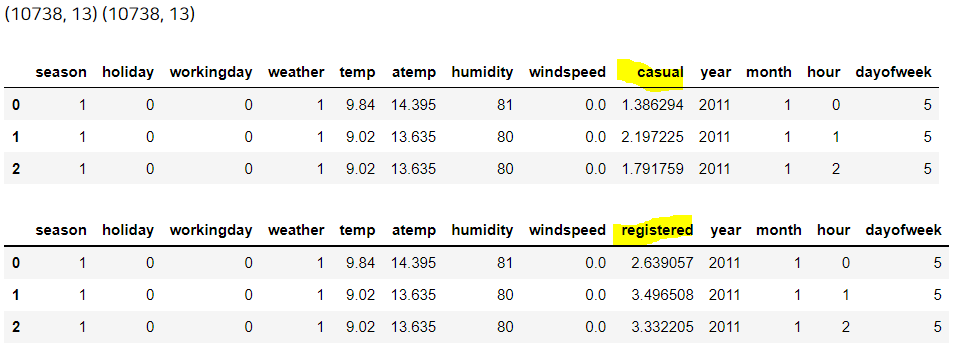
앞으로 casual을 예측하는 것에는 train_c 데이터를,
registered를 예측하는 것에는 train_re 데이터를 사용해 모델을 만들 것이다.
이렇게 하여 train data 전처리를 마무리하였다.
사실 데이터 전처리를 하는 과정에는 정답이 없다. 모든 데이터에 위와 같은 전처리 과정을 사용해야 하는 것은 아니며, 위에 내가 한 전처리와 다른 방법을 사용해서 더 성능을 좋게 만들 수도 있다.
어떤 데이터를 사용하느냐에 따라 전처리 방법은 무궁무진하게 달라지므로 여러 시행착오를 거칠 수밖에 없는 것 같다.
Baseline 모델을 만들 때는 가장 최소한의 전처리만 해보고(아웃라이어 제거, target 로그변환 등) 그 다음 성능 개선을 시킬 때 여러 전처리를 실험적으로 적용해보고, 최종 결과물을 제출해보면서 성능이 얼마나 나오는지를 파악하는 것을 추천한다.
포스팅이 길어지는 관계로, 직접 모델링을 하는 부분부터는 바로 다음 포스팅으로 이어진다.
casual에 대해 예측하는 모델 1개, registered에 대해 예측하는 모델 1개를 각각 만들고, 만들어진 예측값을 더해 최종 예측 결과까지 만들고 결과를 확인해보자!
'Data Science > Kaggle' 카테고리의 다른 글
| [kaggle] Bike Sharing Demand: ML 성능 개선 1편 (Ridge, Random Forest, LGBM) (0) | 2022.07.01 |
|---|---|
| [kaggle] Bike Sharing Demand: Baseline Model 2편 (pipeline, k-fold, scaling) (0) | 2022.06.30 |
| [kaggle] Bike Sharing Demand: EDA 2편 (0) | 2022.06.25 |
| [kaggle] Bike Sharing Demand: EDA 1편 (6) | 2022.06.24 |
| Kaggle 프로젝트를 시작하며 (feat. 깃허브) (0) | 2022.06.24 |



