
목록파이썬 (49)
Yours Ever, Data Chronicles
 [Python Crawling] 네이버 쇼핑 검색결과 크롤링하기 (2) - Selenium, BeautifulSoup
[Python Crawling] 네이버 쇼핑 검색결과 크롤링하기 (2) - Selenium, BeautifulSoup
저번 포스팅에서는 Python selenium, beautifulsoup를 활용하여 네이버 쇼핑에서 '샤인머스캣'을 검색한 결과 중 제목을 뽑아오는 데에 성공했다. 이번 포스팅에서는 판매자, 가격, 등록일, 상품 URL 정보를 뽑아보자! 이번에 사용하는 방법도 아까 전에 사용한 방법과 크게 다르지 않다. 크롬 개발자모드로 들어가 html을 보면서 beautifulsoup(bs) 를 활용해 값을 하나씩 쏙쏙 뽑아오면 된다. 먼저 전체 상품 40개(1페이지에 있는 상품이 40개이므로)에 대한 정보를 담은 'goods_list'를 만든다. 이는 이전 포스팅에서도 나왔지만 전체상품 정보가 있는 html 클래스 이름이 li.basicList_item__0T9JD 이므로 사용해주었다. soup = Beautiful..
 [Python Crawling] 네이버 쇼핑 검색결과 크롤링하기 (1) - Selenium, BeautifulSoup
[Python Crawling] 네이버 쇼핑 검색결과 크롤링하기 (1) - Selenium, BeautifulSoup
최근 파이썬으로 크롤링할 일이 생겼는데, 여러 방법을 동원하며 얻은 새로운 정보들이 있어서 이를 정리할 겸, 공유 목적으로 포스팅해보고자 한다 :) 내가 크롤링한 페이지는 네이버 쇼핑 검색 결과 페이지인데, 얻고자 한 결과물은 다음과 같은 엑셀 파일이었다. 네이버 쇼핑 페이지에 '샤인머스캣'을 치고, "리뷰 많은순"으로 정렬해서 나온 값을 뽑았다. 내가 원하는 정보는 이런 값들이었다. 상품명 판매처에서 올린 이미지 판매처 판매처 판매가 상품 URL 그리고 다음과 같은 시행착오를 거쳤다. 먼저 파이썬 Selenium, BeautifulSoup를 활용하여 자동화된 크롬 창을 띄워놓고 긁어오는 방식을 사용 장점: 가장 간단하고 많이 알려진 방식 단점: 정보가 중간에 안 긁어지는 케이스가 있다. (그 이유는 포..
 [kaggle] 범주형 데이터 분석 프로젝트 - EDA 2편
[kaggle] 범주형 데이터 분석 프로젝트 - EDA 2편
저번 포스팅에 이어, 이번에는 나머지 범주형 변수들에 대해 EDA를 진행한다. ✔Table of Contents 4. nom_* 변수 EDA (feat. 통계의 함정) 이 변수는 명목형 변수로, 저번 포스팅에서 봤던 bin_* 변수는 고유값이 단 2개였지만 이 변수는 고유값이 여러개이다. 먼저 nom_* 변수를 담은 list2를 만들고, 각 변수별 고유값을 살펴보자. list2 = list() for i in range(0, 10): list2.append('nom_{0}'.format(i)) for ind, col in enumerate(train[list2]): print(col, '의 고유값은: ', train[col].unique()) 결과를 보면 굉장히 스크롤 압박이 심하다. nom_0 ~ no..
 [kaggle] 범주형 데이터 분석 프로젝트 - EDA 1편
[kaggle] 범주형 데이터 분석 프로젝트 - EDA 1편
두번째로 해본 캐글 프로젝트는 범주형 데이터를 분석하는 프로젝트, Categorical Feature Encoding Challenge이다. 링크를 클릭하면 캐글에서 데이터셋을 다운받을 수 있다. 이 프로젝트에서 사용되는 데이터는 전부 범주형 데이터셋이다. 학습에 사용되는 피처들뿐만 아니라 target 변수까지 모두 범주형 데이터로 되어 있다. 그래서 이번 프로젝트 (특히 EDA 편)에서는 범주형 데이터를 어떻게 분석하는지를 자세히 다룰 것이다. (여담인데, 이 프로젝트 캐글 페이지에 고양이가 있는 이유는 범주형 데이터 분석(Categorical Data)를 줄여 cat-in-the-dat 이라고 이름을 만들었기 때문! 귀엽당...) 또한 이 프로젝트와 포스팅에서 사용된 코드는 나의 깃허브에서 다운받을 ..
 [시각화] 파이썬 이중 Y축 그래프 그리기 (ax.twinx)
[시각화] 파이썬 이중 Y축 그래프 그리기 (ax.twinx)
파이썬 그래프를 그릴 때, 한 그래프에 더 많은 정보를 담고자 한다면 이중 축을 활용한다. 예를 들어 밑의 예시처럼, (좌측) 특정 변수의 countplot 및 비율만 그릴 수도 있겠지만 (우측) 오른쪽에 이중 축을 하나 더 만들어 또다른 변수의 값이 1인 비율도 나타낼 수 있다. 이렇게 이중 축을 만들고자 할 때, seaborn의 ax.twinx() 를 활용하는 방법을 알아보자. NOTE: 코드는 저의 깃허브에서 내려받을 수 있습니다! 먼저, 좌측 그래프는 앞의 포스팅에서 이미 그렸다. 이번 포스팅에서는 앞에서 그린 비율 countplot에 하나의 이중축을 더 만들어볼 것이다. 이중축은 'nom_1' 변수의 각 고유값들이 target = 1로 갖고 있는 비율을 나타내보자! import pandas as..
 [pandas] 순서가 있는 범주형 데이터에 순서 지정하기 - CategoricalDtype
[pandas] 순서가 있는 범주형 데이터에 순서 지정하기 - CategoricalDtype
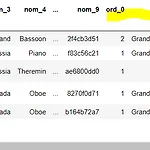
이전에 쓴 시각화 포스팅의 첫머리에서 데이터의 종류에 대해 설명하였다. 그 때 데이터는 사칙연산이 가능한 '수치형 데이터'(numerical data)와 '범주형 데이터'(categorical data)로 나눌 수 있으며, 범주형 데이터 중에서 순서(순위)가 있는 데이터를 순서형 데이터(ordinal data)라고 하였다. 이런 순서형 데이터가 있는 데이터를 받은 경우, 순위를 꼭 지켜줘야 한다. 그 이유는 순서형 데이터는 순위대로 중요도가 달라지기 때문이다. 대표적인 순서형 데이터인 '학점'의 경우 A+이라는 값과 F 라는 값은 큰 차이가 있듯이! 하지만 데이터셋에 순위가 지정되어 있지 않은 경우가 많다. 이럴 때 판다스의 CategoricalDtype 함수를 사용하면 내가 순위를 지정한 대로 순서가 ..
 [pandas] 범주형 데이터 2개를 비교하는 교차분석표(crosstab, 크로스탭) 알아보기
[pandas] 범주형 데이터 2개를 비교하는 교차분석표(crosstab, 크로스탭) 알아보기
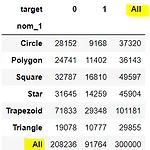
파이썬 판다스(pandas)에서 범주형 데이터 2개를 비교분석할 때 유용한 표, 교차분석표(crosstab)에 대해 알아보자. 이러한 교차분석표는 각 범주형 데이터의 개수를 행과 열로 cross해놓은 표를 의미한다. 다음은 pandas crosstab 공식 문서를 참고하였다. pd.crosstab(index, columns, values=None, rownames=None, colnames=None, aggfunc=None, margins=False, margins_name='All', dropna=True, normalize=False) 필수 input index: 행으로 그룹화할 값 (array, series, list) columns: 열로 그룹화할 값 (array, series, list) Opt..
 [시각화] 파이썬 그래프 위에 글자 쓰기 (ax.patches, ax.text)
[시각화] 파이썬 그래프 위에 글자 쓰기 (ax.patches, ax.text)
파이썬 그래프를 그렸는데, 바로 밑의 그림처럼 그래프 위에 비율까지 쓰고 싶은 경우가 있을 것이다. 이럴 때 사용하면 유용한 파이썬 seaborn에서 제공하는 ax.patches, ax.text 메서드를 활용하면 손쉽게 그릴 수 있다. 먼저 데이터셋은 캐글 Categorical Feature Encoding Challenge 에서 제공하는 'train.csv' 파일을 활용하였다. NOTE: 코드는 저의 깃허브에서 내려받을 수 있습니다! import pandas as pd import matplotlib.pyplot as plt %matplotlib inline import seaborn as sns df = pd.read_csv('train.csv', index_col = 'id') df.head() 먼..
 python sample 함수 사용법과 예제
python sample 함수 사용법과 예제
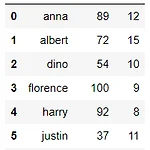
sample 함수는 파이썬의 내장 함수이다. 보통 어떠한 데이터프레임에서 랜덤하게 n개의 데이터(인덱스)를 뽑아야 할 때 사용한다. DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None, ignore_index=False) n: 추출할 개수 frac: 추출할 비율, 1보다 작은 값으로 설정 (ex. 절반을 뽑는다면 0.5) n과 frac은 동시에 사용 불가능 replace: 중복 추출 허용 여부, True로 지정 시 중복을 허용하여 추출 weights: 가중치로, 레이블별 추출될 확률 지정 가능 random_state: 시드(seed)로, 원하는 숫자 지정 시 항상 같은 결과 출력 axis:..
 [pandas] Series & DataFrame에서 자주 사용하는 유용한 메서드 (1)
[pandas] Series & DataFrame에서 자주 사용하는 유용한 메서드 (1)
이번 포스팅과 다음 포스팅은 파이썬 판다스의 Series(시리즈)와 DataFrame(데이터프레임)을 사용할 때, 자주 사용하는 유용한 메서드들을 정리해보려고 한다. 먼저 시리즈와 데이터프레임이 무엇인지, 어떻게 만드는지를 알아보고 이 두가지를 다룰 때 어떤 메서드를 자주 사용하는지 알아보자! 이번 편은 시리즈와 데이터프레임이 무엇인지를 알아보자. 포스팅에서 사용한 코드는 이 깃허브에서 다운로드하시면 됩니다 :) ✔Table of Contents 1. 시리즈 & 데이터프레임 만들기 시리즈(series)와 데이터프레임(dataframe)은 데이터를 다루는 데 특화된 형태라고 할 수 있다. 먼저, 우리가 자주 보게 되는 데이터프레임(df)은 행과 열의 2차원 형태로 구성되어 있다. df에서는 열을 컬럼(co..