
Yours Ever, Data Chronicles
[kaggle] 범주형 데이터 분석 프로젝트 - EDA 1편 본문
두번째로 해본 캐글 프로젝트는 범주형 데이터를 분석하는 프로젝트, Categorical Feature Encoding Challenge이다. 링크를 클릭하면 캐글에서 데이터셋을 다운받을 수 있다.

이 프로젝트에서 사용되는 데이터는 전부 범주형 데이터셋이다. 학습에 사용되는 피처들뿐만 아니라 target 변수까지 모두 범주형 데이터로 되어 있다. 그래서 이번 프로젝트 (특히 EDA 편)에서는 범주형 데이터를 어떻게 분석하는지를 자세히 다룰 것이다.
(여담인데, 이 프로젝트 캐글 페이지에 고양이가 있는 이유는 범주형 데이터 분석(Categorical Data)를 줄여 cat-in-the-dat 이라고 이름을 만들었기 때문! 귀엽당...)
또한 이 프로젝트와 포스팅에서 사용된 코드는 나의 깃허브에서 다운받을 수 있다.
먼저 데이터부터 살펴보자.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
train = pd.read_csv('train.csv', index_col = 'id')
test = pd.read_csv('test.csv', index_col = 'id')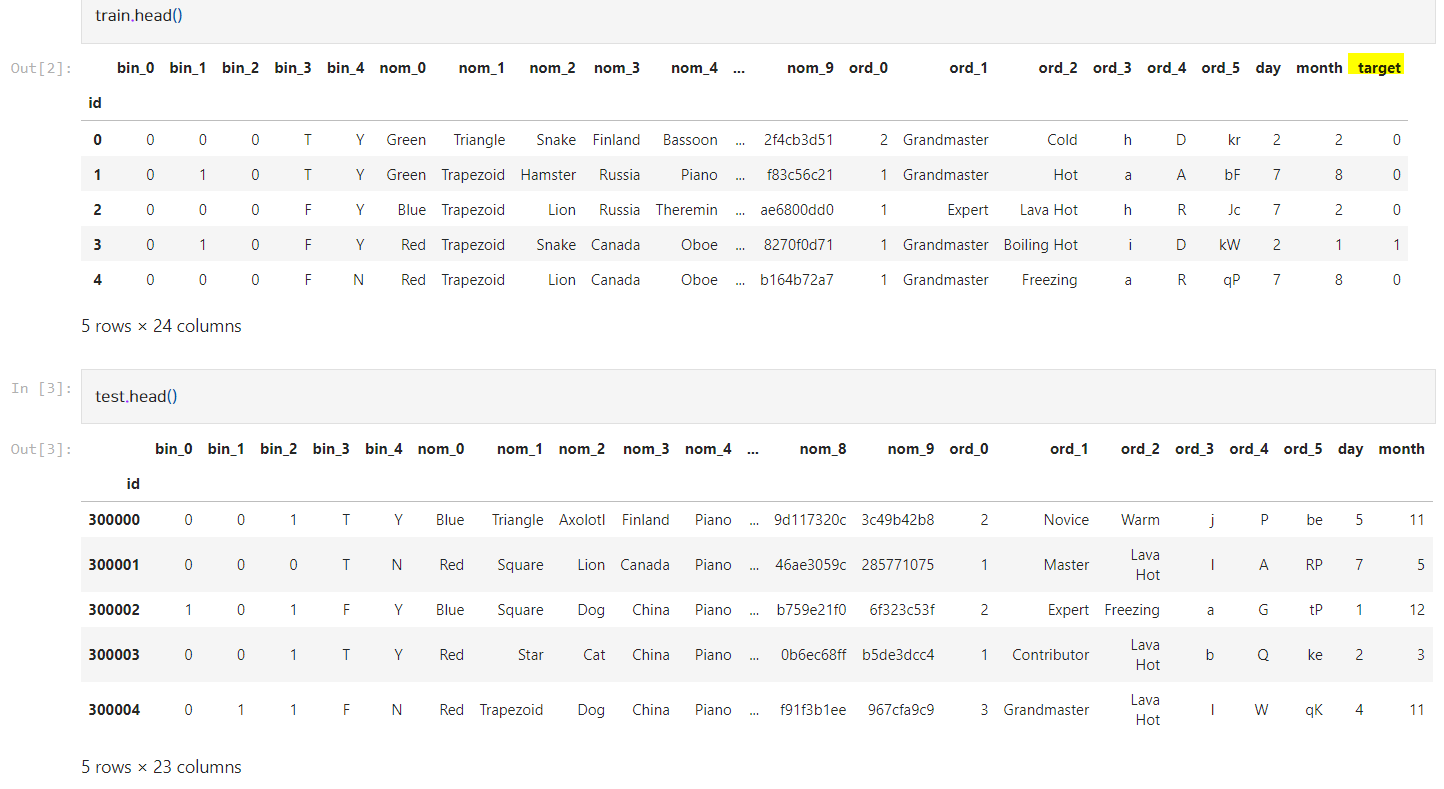
train, test 데이터셋이다. 딱 보면 알겠지만 모든 변수가 범주형 데이터이며, 숫자로 된 것도 있고 문자로 된 것도 있다.
이 프로젝트는 나머지 변수들을 활용해 "target" 변수를 예측하는 것이며, target 변수는 0과 1로 되어 있는 이진 변수(binary variable) 이다. 그러므로 Classification(분류) 의 문제이다.
print(train.shape, test.shape)
train, test는 각각 30만 개, 20만 개가 있고 train의 컬럼 수가 1개 더 많은 이유는 target 때문이다.
target을 제외한 변수가 23개나 된다. 그래서 head로 뽑으면 위처럼 중간에 변수가 잘려서 나온다.
이런 경우에는 데이터를 전치시켜 보면 좋다.
train.head().T
데이터를 전치시키면 열이 행(인덱스)로 가고, head를 뽑았으므로 첫 5개 행만 나오므로 컬럼이 0~4로 바뀐다.
인덱스를 보면 알겠지만 아주 많은 열이 있다!(24개)
캐글의 데이터 페이지에서 데이터 설명(description)을 참고하면 변수들은 다음과 같이 정리할 수 있다.

그럼 본격적으로 EDA를 시작해보자!
✔Table of Contents
1. EDA 전, 데이터 점검
데이터를 받으면 처음 해야 할 것이 바로 이 점검이다. 간단하게 중복과 결측치가 있는지를 살펴본다.
# 중복 데이터가 있는가?
train.duplicated().sum()
# 결측치가 있는가?
train.info()
train data에 대해 확인해본 결과 중복도, 결측치도 없었다.
사실 이번 프로젝트의 데이터들은 인공적으로 만들어진 데이터이기 때문에 일부러 중복과 결측치가 없게 만든 것 같다.
test data에 대해서도 중복과 결측치를 확인하고 없는 것을 확인했다. 이제 EDA로 넘어가자.
※ EDA에 들어가기 전에
원래 앞의 Bike Sharing Demand 프로젝트를 했을 때도 말했지만 EDA는 데이터의 현황을 분석하는 것이므로 궁금한 점을 만들어내고 이에 대해 답을 내는 식으로 분석하면 좋다고 했었다.
하지만 이 데이터의 경우엔 인공적으로 만들어진 데이터이기도 하고, 이전 프로젝트와는 달리 변수가 어떤 의미를 담고 있지 않아 궁금한 점을 만들어내기 쉽지 않다.
그래서 이번 EDA에서는 각 변수들을 bin 변수 / nom 변수 / ord 변수 / day & month 변수로 나누어서,
- 각 변수들이 갖고 있는 고유한 값(카테고리)은 무엇이 있는지
- 각 변수들과 target 간 관계는 무엇인지
를 중심으로 EDA를 진행할 것이다.
대부분 프로젝트에선 수치형 변수가 많은데, only 범주형 변수만 분석해보는 것은 좋은 경험이라고 생각한다 :)
2. target의 분포
먼저 가장 중요한 target 변수의 분포부터 확인해보자. 아까 target은 0, 1의 값을 갖는 이진 변수라고 했는데 과연 이 값이 고르게 분포하고 있을까?
ax = sns.countplot(x = 'target', data = train)
plt.show()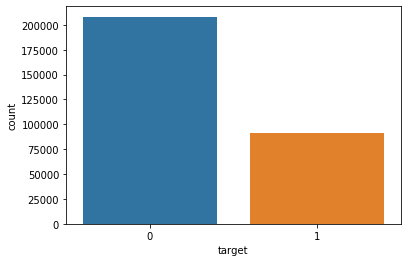
y축은 개수이다. 이를 참고하면 0은 약 20만 개, 1은 약 10만 개가 있음을 알 수 있다.
이렇게 보면 0이 1보다 훨씬 많다는 건 알겠는데 더 정확히 알기 위해서 비율을 표시하였다.
ax = sns.countplot(x = 'target', data = train)
for patch in ax.patches:
# 2개의 patch 값을 가짐
ax.text(x = patch.get_x() + patch.get_width()/2,
y = patch.get_height() + len(train)*0.001,
s = f'{(patch.get_height()/len(train))*100: 1.1f}%',
ha = 'center')
plt.rc('font', size = 13)
plt.show()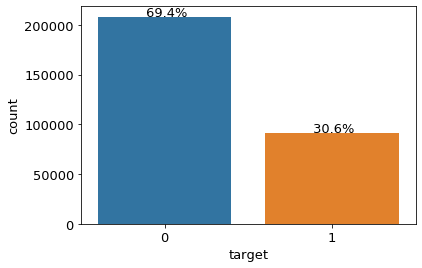
이렇게 비율로 나타내니 보기가 훨씬 편하다.
(참고로 이렇게 비율을 나타내는 데에는 ax의 patches라는 메서드와 text 메서드를 사용하였다. 어떻게 저 코드를 만들었는지 궁금하다면 이 포스팅에서 설명하였다!)
아무튼 target의 0과 1의 비율은 약 7:3이라는 것이 눈에 확 들어온다.
1의 개수가 0에 비해 좀 적은 편이다.
이렇게 그래프 위에 비율을 적어 반환하는 것은 나중에 다른 변수들에서도 또 쓸 것이므로 함수로 저장한다.
# 나중에도 쓸 것이므로 함수로 저장
def write_text(ax, total_size):
for patch in ax.patches:
ax.text(x = patch.get_x() + patch.get_width()/2,
y = patch.get_height() + total_size*0.001,
s = f'{(patch.get_height()/total_size)*100: 1.1f}%', #소수점 1자리까지
ha = 'center')
3. bin_* 변수 EDA
이번엔 이진 변수에 대해 EDA한다.
이 데이터에서 이진 변수는 모두 변수 이름이 "bin_"으로 시작하고, 순서대로 숫자가 부여된다.
bin_* 변수는 총 5개가 있으므로 이렇게 만들 수 있다.
# 열 이름이 모두 bin 어쩌구니까 이런 식으로 만들어도 된다!
list1 = list()
for i in range(0, 5):
list1.append('bin_{0}'.format(i))
list1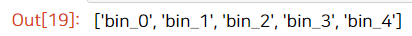
train[list1]
이렇게 만들어진 bin_* 리스트로 train 데이터에 대해 인덱싱하면 이진 변수들만 뽑을 수 있다.
각 이진 변수들이 갖고 있는 고유한 값은 무엇이 있는지 unique 함수로 뽑아보았다.
for ind, col in enumerate(list1):
print(col, '의 고유한 값은' ,train[col].unique())
전부 이진변수이므로 2개의 값을 갖고 있다.
bin_0 ~ bin_2는 0, 1을 갖고 있으나 bin_3은 T/F, bin_4는 Y/N으로 돼있으니 나중에 1과 0으로 변환이 필요하다.
(그 이유는 머신러닝 모델은 문자는 인식하지 못하기 때문)
고유값이 어떤 게 있는지 파악했으니, 앞에서 target 변수에 했던 것처럼 bin_* 변수들이 0과 1의 값을 각각 얼마나 갖고 있는지를 시각화하자.
앞에서 사용한 비율을 써주는 함수를 사용해, 그래프 위에 비율을 나타낼 것이다.
plt.subplots와 gridspec을 활용하여 bin_* 변수들 5개를 한 그래프로 나타낸다.
# 각 피처별 고유값의 비율 시각화
## gridspec을 활용하면 몇 행 몇 열의 그래프를 지정해줄 수 있다. grid를 인덱싱해서!
import matplotlib.gridspec as gridspec
plt.figure(figsize = (18, 10))
plt.subplots_adjust(wspace = 0.4, hspace = 0.3) #각 ax별 간격 (w: 좌우, h: 상하 여백)
grid = gridspec.GridSpec(2, 3)
for ind, col in enumerate(list1):
# 특정 ax에 그래프를 그림
ax = plt.subplot(grid[ind])
sns.countplot(x = col, data = train, ax = ax)
#text는 앞에서 만든 함수 활용
write_text(ax, len(train))
# 각 ax에 제목 달아주기
ax.set_title(f'Countplot of {col}')
plt.rc('font', size = 12)
plt.show()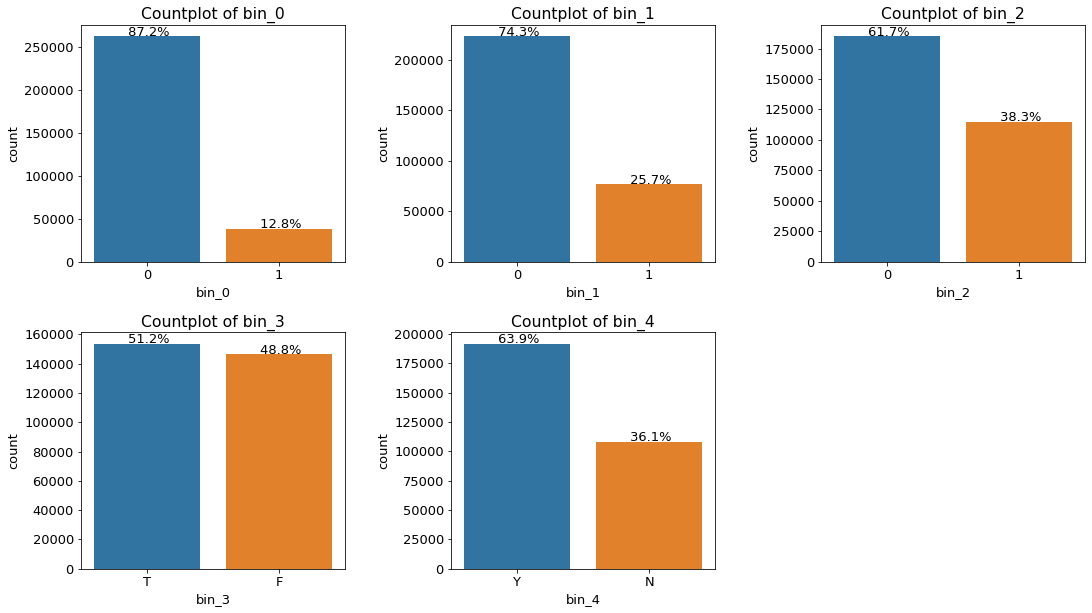
2행 3열의 subplots 안에 bin_0부터 bin_4까지 5개의 변수 차례로 countplot을 그려보았다.
gridspec을 사용하면 2행 3열의 subplot들로 그리드를 나눈다고 생각하면 된다.
결과를 보면 bin_0, bin_1, bin_2는 0이 압도적으로 많으며,
bin_3는 T, F의 개수가 비슷한 편이고,
bin_4는 Y가 좀 더 많다.
이렇게 하여 bin_* 변수가 어떤 고유값을 몇 %의 비율로 갖고 있는지를 알아보았다.
이제는 좀 더 중요한, bin_* 변수와 target 간의 관계를 파악해보자.
수치형 변수는 target과 관계를 파악하기가 쉽다. 산점도를 그려볼수도 있고, 상관계수를 구해볼 수도 있다.
하지만 범주형 변수라면 target과 어떻게 관계를 파악해야 할까?
나는 target이 0, 1의 값을 갖고 있고, 이 값을(특히 1의 값을) 예측해야 하므로
bin_* 변수의 어떤 고유값이 target이 1인 것을 더 많이 갖고 있을까?(더 잘 설명해줄까?) 를 봐야한다고 생각했다.
그래서 target이 0인 것과 1인 것으로 데이터를 나눠 bin_*와 target 간 countplot을 여러개 그려보았다.
target0 = train_b.loc[train_b['target']==0]
target1 = train_b.loc[train_b['target']==1]
# bin_*별, 왼쪽은 target =0, 오른쪽은 target = 1 그래프
plt.rc('font', size = 11)
# bin_* 의 * 숫자값을 i로 둔다
for i in range(0,5):
fig,ax = plt.subplots(1, 2, figsize = (10, 3))
plt.subplots_adjust(wspace=0.5) #두 plot 간 사이 거리
ax[0] = sns.countplot(x = 'bin_{0}'.format(i), data = target0, ax = ax[0]).set_title('bin_{0} Countplot when target = 0'.format(i))
ax[1] = sns.countplot(x = 'bin_{0}'.format(i), data = target1, ax = ax[1]).set_title('bin_{0} Countplot when target = 1'.format(i))
plt.show()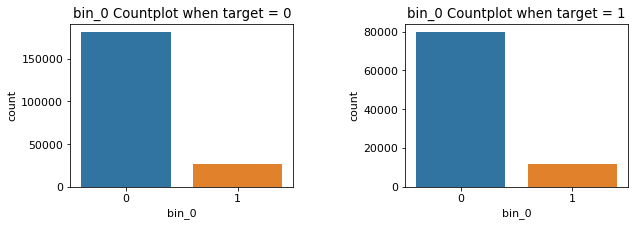
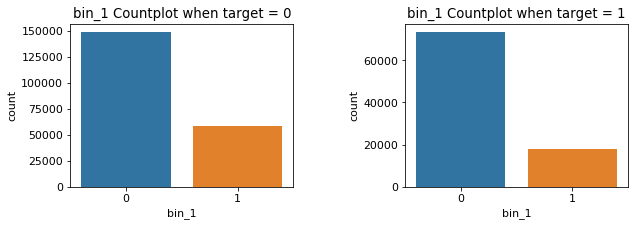

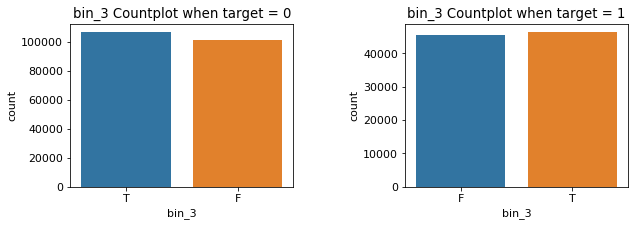

위의 그림이 나쁘진 않지만, 너무 그래프가 길기도 하고 왼쪽과 오른쪽 그래프가 별로 차이가 나지 않아 보인다.
그래서 target을 0 / 1인 것으로 나눠서 2개의 그래프로 그리지 말고, 1개 그래프에 압축시켜 그려보았다.
이를 위해서는 아까 2행 3열로 subplots 그렸던 코드에서, sns.countplot의 hue에 target 설정만 추가하면 된다.
# 각 열별/target별 고유값의 비율 시각화 -> 총 5개 그래프
plt.figure(figsize = (18, 10))
plt.subplots_adjust(wspace = 0.4, hspace = 0.3) #각 ax별 간격 (w: 좌우, h: 상하 여백)
grid = gridspec.GridSpec(2, 3)
for ind, col in enumerate(list1):
# 특정 ax에 그래프를 그림
ax = plt.subplot(grid[ind])
sns.countplot(x = col, data = train, hue = 'target', ax = ax)
#text는 앞에서 만든 함수 활용
write_text(ax, len(train))
# 각 ax에 제목 달아주기
ax.set_title(f'Countplot of {col} by target')
plt.rc('font', size = 12)
plt.show()
좀 더 한눈에 잘 들어오지 않은가? :)
다만 해석할 때 그래프 위에 계산된 비율값에 주의해야 한다.
예를 들어 bin_0에서는 총 4개의 Bar가 있는데, 각 Bar가 차지하는 비율을 전부 더한 것이 100% 가 된다.
하지만 bin_0가 1인 값만 떼서 target이 0인 것과 1인 것의 비율을 구하면 69.1%와 30%이며,
bin_0가 0인 값만 떼서 target이 0인 것과 1인 것의 비율을 구하면 69.4%와 30%가 된다.
즉 집계 대상을 어디에 두느냐에 따라 저 비율값은 달라지게 된다.
여기서는 bin_*가 이진변수라 고유값이 적다보니 그냥 위의 그래프로만 봐도 이해가 어렵지 않다.
하지만 고유값이 늘어나면 해석이 어려워질 수 있다. 이는 다음에 보는 변수에서 한번 더 설명하겠다.
이렇게 해서 오늘 포스팅은 여기에서 마친다.
나머지 변수인 nom_*, ord_*, day, month EDA는 다음 포스팅에서 이어진다 🙌
'Data Science > Kaggle' 카테고리의 다른 글
| [kaggle] 범주형 데이터 분석 - 변수 인코딩 & Baseline model (0) | 2022.08.04 |
|---|---|
| [kaggle] 범주형 데이터 분석 프로젝트 - EDA 2편 (0) | 2022.07.15 |
| [kaggle] Bike Sharing Demand: ML 성능 개선 3편 (머신러닝 결측치 처리) (2) | 2022.07.03 |
| [kaggle] Bike Sharing Demand: ML 성능 개선 2편 (변수 선택) (0) | 2022.07.02 |
| [kaggle] Bike Sharing Demand: ML 성능 개선 1편 (Ridge, Random Forest, LGBM) (0) | 2022.07.01 |



