
Yours Ever, Data Chronicles
[kaggle] 범주형 데이터 분석 프로젝트 - EDA 2편 본문
저번 포스팅에 이어, 이번에는 나머지 범주형 변수들에 대해 EDA를 진행한다.
✔Table of Contents
4. nom_* 변수 EDA (feat. 통계의 함정)
이 변수는 명목형 변수로, 저번 포스팅에서 봤던 bin_* 변수는 고유값이 단 2개였지만 이 변수는 고유값이 여러개이다.
먼저 nom_* 변수를 담은 list2를 만들고, 각 변수별 고유값을 살펴보자.
list2 = list()
for i in range(0, 10):
list2.append('nom_{0}'.format(i))
for ind, col in enumerate(train[list2]):
print(col, '의 고유값은: ', train[col].unique())
결과를 보면 굉장히 스크롤 압박이 심하다.
nom_0 ~ nom_4까지는 그나마 고유값이 엄청 많진 않지만, nom_5부터는 고유값이 엄청나게 많으며, 영어와 숫자가 섞인 외계어로 무엇을 가리키는지도 알 수 없다.
그래서 고유값보다는 고유값의 개수를 뽑아보자.
# nom_* 변수는 고유값의 수가 많으므로 개수만 출력해보자
for ind, col in enumerate(train[list2]):
print(col, '의 고유값 개수는: ', train[col].nunique())
이렇게 nom_0 ~ nom_4까지만 고유값의 개수가 적당한 편이므로, 이 변수들에 대해서만 시각화를 진행한다.
각 변수별 고유값의 비율을 그래프로 그려보자.
# 각 피처별 고유값의 비율 시각화 (앞에서 쓴 코드 활용)
## gridspec을 활용하면 몇 행 몇 열의 그래프를 지정해줄 수 있다. grid를 인덱싱해서!
import matplotlib.gridspec as gridspec
# nom_0~nom_4까지만 리스트
nom_list = [f'nom_{i}' for i in range(5)]
plt.figure(figsize = (15, 15))
plt.subplots_adjust(wspace = 0.4, hspace = 0.3) #각 ax별 간격 (w: 좌우, h: 상하 여백)
grid = gridspec.GridSpec(3, 2)
for ind, col in enumerate(nom_list):
# 특정 ax에 그래프를 그림
ax = plt.subplot(grid[ind])
sns.countplot(x = col, data = train, ax = ax, color = 'skyblue')
#text는 앞에서 만든 함수 활용
write_text(ax, len(train))
# 각 ax에 제목 달아주기
ax.set_title(f'Countplot of {col}')
plt.rc('font', size = 10)
plt.show()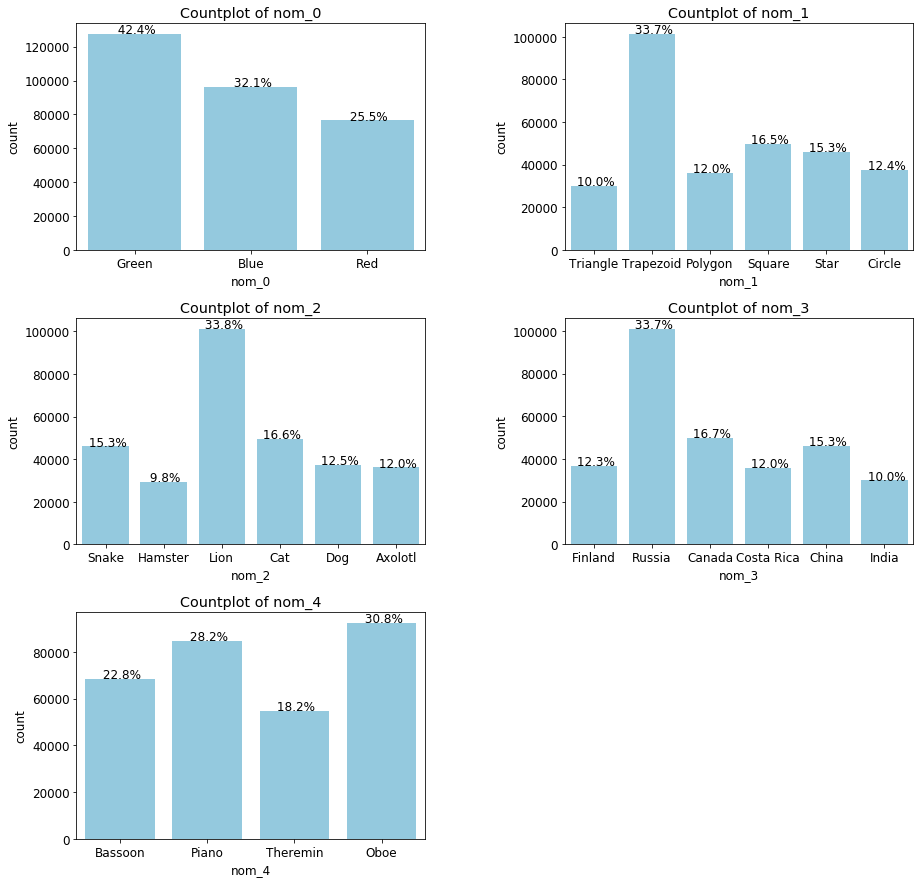
저번 포스팅에서 사용한 코드를 거의 그대로 사용했다.
각 변수별 고유값 비율을 살펴보면 다음과 같다.

이렇게 각 변수별로 가장 많은 고유값이 무엇인지를 알아보았다.
앞선 포스팅에서도 말했지만, 이렇게 그냥 변수별 특징만 살펴보는 게 아니라 변수와 target 간의 관계를 살펴보는 것이 중요하다.
그래서 countplot에 hue = 'target'으로 하여 결과를 살펴보았다. (코드 생략)
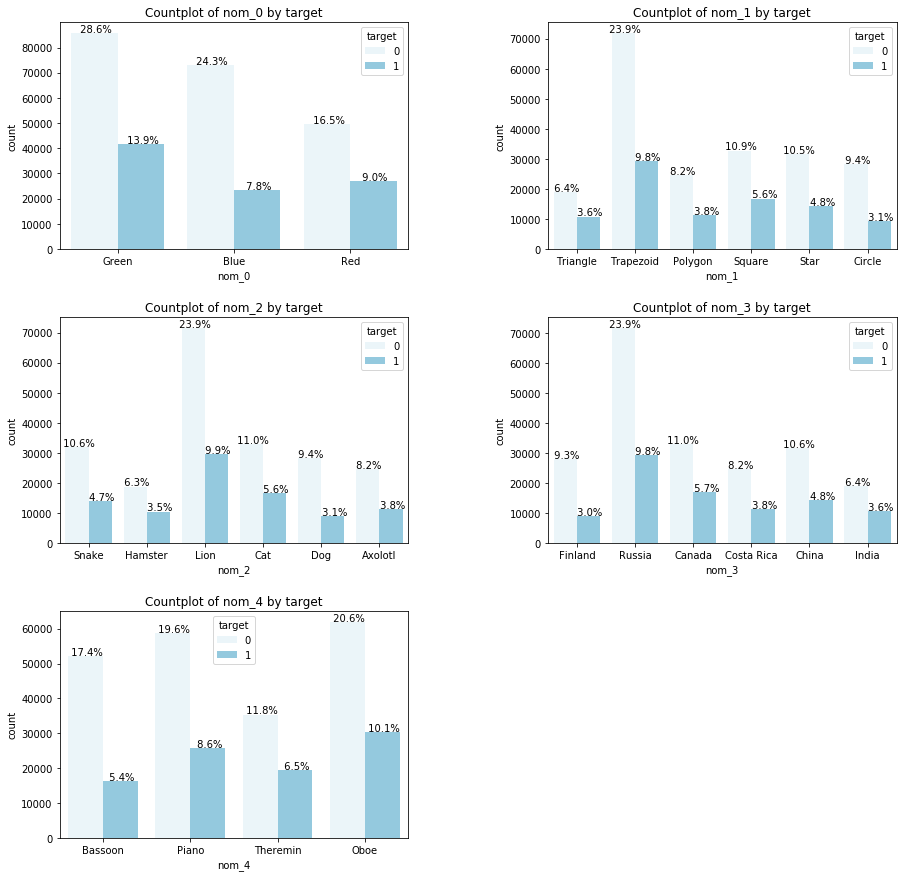
위 그래프를 보면 어떤 생각이 드는가?
예를 들어 nom_0 그래프(가장 첫번째 그래프)를 보면 Green이 가장 많은 비율을 차지하고 있으며 target = 1의 비율도 Green이 가장 많이 갖고 있는 것처럼 보인다.
나머지 변수들도 마찬가지다. 가장 비율이 큰 고유값이 target = 1의 비율도 가장 크다.
여기서 통계의 함정을 살펴볼 수 있다.
앞의 포스팅에서도 살짝 언급했지만, 여기서 그래프에 표시되는 비율 값은 모두 합하면 100%가 되게 만들었다.
그래서 이 방식으로 본다면 비율이 월등하게 큰 고유값들(ex. nom_0의 Green, nom_1의 Trapezoid, nom_3의 Russia)이 절대적인 개수가 많기 때문에, target = 1인 비율도 더 크게 나온다.
하지만 특정 고유값만 따로 뽑아서 target = 1의 비율만 따로 구해보면 다른 고유값이 target = 1을 갖고있는 비율이 더 클 수도 있다.
그래서 "어떤 것을 집계 기준으로 설정할 것인가?"가 중요한 것이다.
조금 더 풀어서 설명을 해보자면, 'nom_1' 변수에서 가장 많은 비율을 차지하는 Trapezoid와 가장 적은 비율을 차지하는 Triangle을 예시로 들어 설명하겠다.
Trapezoid만 따로 뽑아 얘가 갖고있는 target의 비율은 다음과 같다.
print(train.loc[train['nom_1'] == 'Trapezoid']['target'].value_counts() / len(train.loc[train['nom_1'] == 'Trapezoid']))
Triangle만 따로 뽑아 얘가 갖고있는 target의 비율은 다음과 같다.
print(train.loc[train['nom_1'] == 'Triangle']['target'].value_counts() / len(train.loc[train['nom_1'] == 'Triangle']))
결과를 정리하면,

어! 앞의 그래프에선 Trapezoid가 target = 1 비율이 가장 높다고 나왔었는데? 이렇게 나오는 이유가 뭘까?
그 이유는 nom_1 변수에서 Trapezoid의 수가 너무 많기 때문이다.
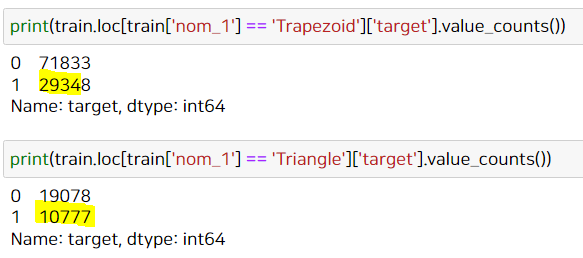
위의 결과를 보자. 이처럼 Trapezoid의 개수는 총 약 10만개이고 Triangle 개수는 총 약 3만개이다.
- 개수: Trapezoid 내의 target==1인 것은 3만개, Triangle 내 target==1인 것은 1만개이므로 전체 plot에선 Trapezoid가 target 1을 갖고있는 비율이 더 크다고 나온 것(실제로 3만개를 갖고있으니 1만개보다 많으니까!)
- 비율: 하지만 개수가 아닌 비율로 본다면, Trapezoid들 중에서 1인 것은 29%, Triangle 중에서 1인 것은 36%이므로 target == 1을 더 잘 예측할 수 있는 고유값은 Triangle인 것이다.
그러니 이번에는 nom_0 ~ nom_4 변수들에 대해, 이런 식으로 고유값별 target이 1인 비율을 구해보자.
여기에는 판다스(pandas)의 교차분석표(crosstab)을 사용하였다. (참고: crosstab이란?)
pd.crosstab(train['nom_1'], train['target'], normalize = 'index')*100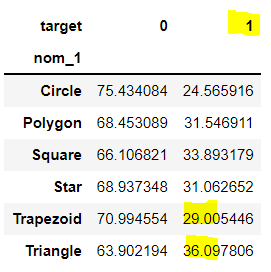
교차분석표로 nom_1 변수와 target 간 비율을 계산하였다.
index를 기준으로 하였으므로, nom_1를 기준으로 비율을 계산하였다. 즉, 각 행별 합이 100%가 된다.
결과를 보면 우리가 아까 전에 계산한 비율이 그대로 들어가 있는 것을 확인할 수 있다.
우리는 이 교차분석표의 '1' 열(target = 1인 비율)을 활용할 것이다.
앞으로 이 교차분석표는 다른 변수에 대해서도 사용할 것이므로, 교차분석표를 생성하는 함수로 만들었다.
# 계속 크로스탭 생성할 것이므로 함수화
def get_crosstab(df, feature):
cross = pd.crosstab(df[feature], df['target'], normalize = 'index')*100
cross.reset_index(inplace = True)
return cross
이제 교차분석표를 활용해서 새로운 그래프를 그려보자. (참고: 파이썬 이중 축 생성하는 방법)
앞에서 변수별 고유값의 비율을 countplot으로 그린 그래프에,
이중 축을 생성하여 각 고유값별 target = 1에 대해 갖는 비율을 pointplot으로 그려보자.
#---------------- 시각화 그래프 함수 생성 ---------------
def draw_two_ratio_plot(fea_list, df, row_num, col_num, size = (15, 18)):
import matplotlib.gridspec as gridspec
plt.figure(figsize = size)
plt.subplots_adjust(wspace = 0.4, hspace = 0.3) #각 ax별 간격
grid = gridspec.GridSpec(row_num, col_num)
#------------------------ 왼쪽 축
for ind, col in enumerate(fea_list):
# 크로스탭 생성
ct = get_crosstab(df, col)
# 특정 ax에 그래프를 그림
ax = plt.subplot(grid[ind])
sns.countplot(x = col, data = df, ax = ax, color = 'skyblue', order = ct[col].values)
#text는 앞에서 만든 함수 활용
write_text(ax, len(df))
# 각 ax에 제목 달아주기
ax.set_title(f'Distribution of {col}')
#----------------------- 오른쪽 축
# 이중 축 생성후 pointplot을 그림
ax2 = ax.twinx()
ax2 = sns.pointplot(x = ct[col], y = ct[1], color = 'black', order = ct[col].values) # ct[1] 은 target =1 의 비율
# y축 범위 설정 - 좀 넉넉하게 잡아줌
ax2.set_ylim(ct[1].min()-5, ct[1].max()*1.1)
# y축 이름 달아주기
ax2.set_ylabel('Target = 1 Ratio')
plt.rc('font', size = 10)
plt.show()
# 그래프 그리기
draw_two_ratio_plot(nom_list, train, 3, 2)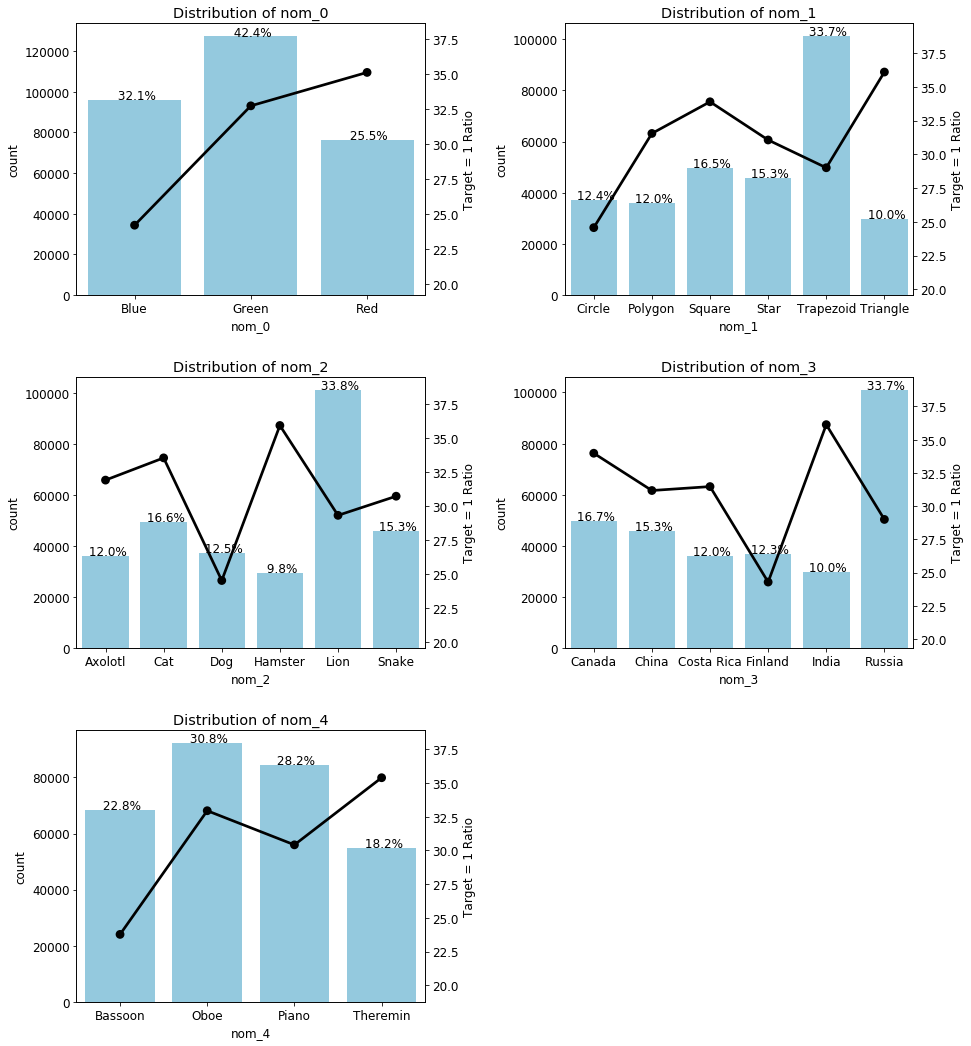
그래프를 살펴보면, 변수별 가장 다수를 차지하고 있는 고유값이 target = 1을 갖고 있는 비율은 가장 낮았다.
(예를 들어 nom_1에서 Trapezoid가 가장 많은 고유값이지만 target = 1은 Triangle이 가장 많음)
이렇게 target = 1의 비율이 고유값별로 다르게 나타난다는 것은 target에 대한 설명력이 있는 변수라고 해석할 수 있으므로, 모델링을 할 때 꼭 포함시켜야 할 좋은 변수들이다.
5. ord_* 변수 EDA
ord_* 변수는 순서형 변수이다. 그래서 각 변수별 고유값이 서로 순서(순위)를 가지며, 이 순위를 꼭 지켜줘야 한다.
먼저 어떤 고유값이 있는지 살펴보자.
ord_col = train.columns[train.columns.str.contains('ord')]
# 고유값 추출 -> 다행히 ord_5를 제외하면 엄청 많진 않군
for ind, col in enumerate(ord_col):
print(col, '의 고유값의 수는: ', train[col].nunique())
print(col, '의 고유값은: ', train[col].unique())
print()
ord_0는 숫자, ord_3~ord_5는 알파벳으로 되어 있다.
그리고 ord_1은 캐글의 등급, ord_2는 날씨로 되어 있다.
알파벳이나 숫자는 순서가 정해져 있지만, ord_1과 ord_2는 순서가 지정되어 있지 않으므로 우리가 일부러 순서를 맞춰놓아야 한다. 판다스의 CategoricalDtype을 사용해 맞춰주자.
# ord 변수들 순서 지정하기 - ord1, ord2만 (나머지는 숫자랑 알파벳이라서)
from pandas.api.types import CategoricalDtype
ord1 = ['Novice', 'Contributor', 'Expert', 'Master', 'Grandmaster']
ord2 = ['Freezing', 'Cold', 'Warm', 'Hot', 'Boiling Hot', 'Lava Hot']
ord1_d = CategoricalDtype(categories = ord1, ordered = True)
ord2_d = CategoricalDtype(categories = ord2, ordered = True)
# 실제로 변경: astype으로 타입 변경
train['ord_1'] = train['ord_1'].astype(ord1_d)
train['ord_2'] = train['ord_2'].astype(ord2_d)
# 그래프 그리기
ord0to3 = ['ord_0', 'ord_1', 'ord_2', 'ord_3']
draw_two_ratio_plot(ord0to3, train, 2, 2, size = (15, 10))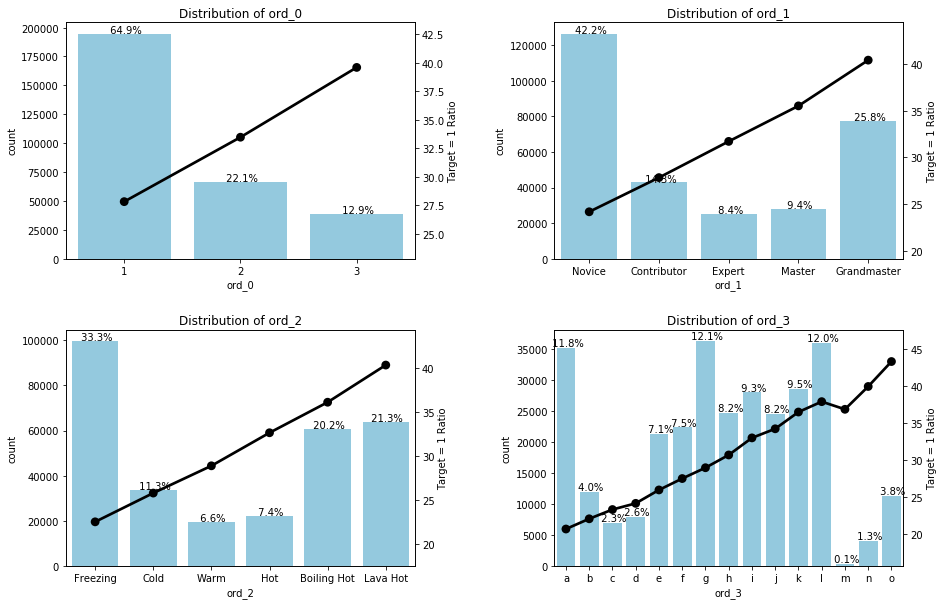
그래프는 앞에서 만들어둔 함수 draw_two_ratio_plot을 적용하면 된다.
ord_1, ord_2의 x축을 보면, 우리가 원하는 순서대로 고유값들이 정렬된 것을 확인할 수 있다.
그래프를 보면 앞의 nom_* 변수들과 똑같이, 변수 내에서 개수가 많은 고유값과 target = 1을 많이 가진 고유값에 큰 차이가 있었으며
(예를 들어 ord_1에서 `Novice`가 전체의 42%로 가장 다수를 차지하지만 target=1은 `Grandmaster`에서 약 40%로 가장 많았다)
ord_* 변수들은 순위가 뒤로 갈수록 target = 1 의 비율이 상승하는 경향성을 보였다.
# ord_4 ~ ord_5 그래프 적용
ord4to5 = ['ord_4', 'ord_5']
draw_two_ratio_plot(ord4to5, train, 2, 1, size = (15, 10))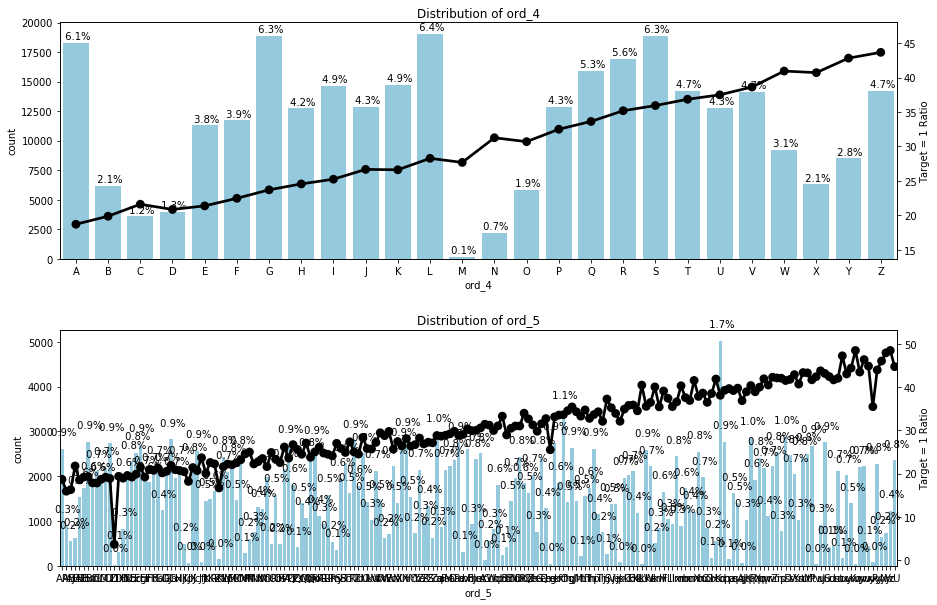
ord_4, ord_5는 너무 고유값이 많아서 따로 그렸다.
역시 이 변수들도 순위가 뒤로 갈수록 target = 1의 비율이 높아지는 경향을 보이므로, ord_* 변수들도 아주 중요한 피처!
6. day & month 변수 EDA
day와 month는 날짜 변수로, 각각 요일 번호와 월을 나타낸다.
# 고유값 추출
daynmth = ['day', 'month']
for ind, col in enumerate(daynmth):
print(col, '의 고유값은: ', sorted(train[col].unique()))
앞에서 그래프 그리는 함수를 만들어놨으므로 손쉽게 그래프를 그려보면,
# 그래프 함수 적용
draw_two_ratio_plot(daynmth, train, 1, 2, size = (15, 5))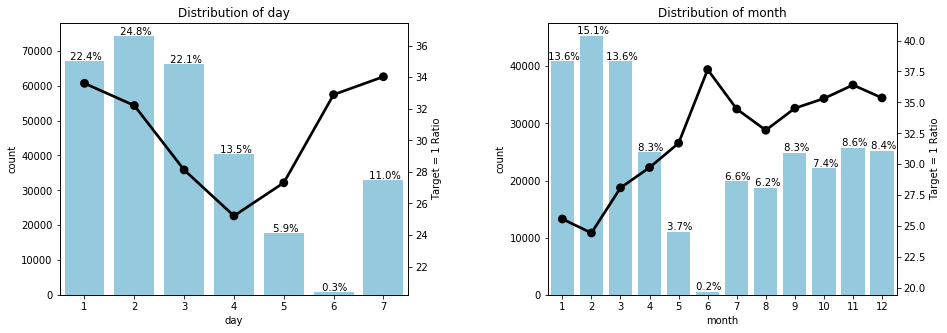
역시 앞의 ord_* 변수들과 마찬가지로, 절대적인 개수가 많은 고유값과 target = 1 비율이 높은 고유값이 일치하지 않았다.
그러므로 day와 month도 의미 있는 변수이다.
Summary
이렇게 해서 범주형 변수들을 모두 살펴보았다. EDA 결과, 모델링에 사용할 변수들을 정리하자면 다음과 같다.
| 변수 | EDA 결과 판단 |
| 이진변수 (bin_0 ~ bin_4) | 모든 변수 ok |
| 명목변수 (nom_0 ~ nom_9) | 모든 변수 ok (단, nom_5 ~ nom_9는 고유값이 너무 많기 때문에 모델링에 포함 or 제거하면서 성능을 판단할 필요가 있다) |
| 순서변수 (ord_0 ~ ord_5) | 모든 변수 ok |
| 날짜변수 (day, month) | 모든 변수 ok |
그럼 다음 포스팅에선 직접 머신러닝(ML) 모델을 만들어보면서, test data에 대한 성능이 어떻게 변할지 알아보자!
시각화 참고 도서: 머신러닝·딥러닝 문제 해결 전략
'Data Science > Kaggle' 카테고리의 다른 글
| [kaggle] 범주형 데이터 분석 - 머신러닝 1편 (변수 선택) (0) | 2022.08.05 |
|---|---|
| [kaggle] 범주형 데이터 분석 - 변수 인코딩 & Baseline model (0) | 2022.08.04 |
| [kaggle] 범주형 데이터 분석 프로젝트 - EDA 1편 (2) | 2022.07.14 |
| [kaggle] Bike Sharing Demand: ML 성능 개선 3편 (머신러닝 결측치 처리) (2) | 2022.07.03 |
| [kaggle] Bike Sharing Demand: ML 성능 개선 2편 (변수 선택) (0) | 2022.07.02 |



