
Yours Ever, Data Chronicles
[kaggle] 범주형 데이터 분석 - 머신러닝 1편 (변수 선택) 본문
이전 포스팅에서는 범주형 변수를 전처리하기 위한 인코딩을 하고, 기본적인 베이스라인 모델을 만들어 제출까지 해보았다.
이번 포스팅부터는 성능을 개선하기 위한 여러 방법들을 시도해보자!
내가 시도해본 방법은 다음과 같다.
- 1) 명목형 변수인 nom_*의 변수 개수 조정 (nom_5~ nom_9번 변수는 의미있는 변수인지 모르니까)
- 2) 로지스틱 회귀의 하이퍼 파라미터 튜닝
이번 포스팅에선 1번을 해본다. 참고로 전체 코드는 나의 깃허브에서 다운받을 수 있다 :)
✔Table of Contents
1. 데이터 불러오기
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings("ignore")
train = pd.read_csv('train.csv', index_col = 'id')
test = pd.read_csv('test.csv', index_col = 'id')
# 인코딩은 train과 test에 모두 해줄 것이므로 먼저 두개를 이어붙인다. target은 따로 빼서 저장
all_data = pd.concat([train, test], ignore_index = True)
all_data.drop(columns = 'target', axis = 1, inplace = True)
all_data.head(3)
데이터가 어떻게 생겼는지는 앞의 포스팅에서도 많이 다루었으므로 별다른 설명 없이 넘어간다.
데이터 인코딩을 위해 주어진 train data, test data를 모두 합쳐 'all_data'로 만들었다.
그리고 train data에 있는 target 변수는 따로 빼서 'train_target' 이라는 이름으로 저장하였다.
# target
train_target = train['target']2. 인코딩 & 머신러닝 부분 함수화 (nom_* 변수 개수 조정)
이번 포스팅에서는 명목형 변수인 nom_* 에서 어떤 값을 포함시키고, 어떤 값을 뺄 것인지가 가장 중요한 부분이다.
특히 nom_* 변수들 중에서 nom_0 부터 nom_4까지는 EDA를 통해 중요한 변수라는 것을 알았지만,
nom_5부터 nom_9까지는 갖고 있는 카테고리의 개수가 너무 많아 EDA를 할 수 없었다.
그래서 직접 nom_5부터 nom_9 까지의 변수를 포함 or 제거해서 스코어가 어떻게 나오는지를 알아보았다.
즉, nom_9만 빼보고 스코어를 구해보고,
nom_8과 nom_9 두개를 빼서 스코어를 구해보고,
nom_7, 8, 9 세개를 빼서 스코어를 구해보고, ... 이런 식으로 구해본다는 것이다.
근데 이걸 위해 계속 같은 인코딩 과정을 거쳐야 하는 점이 매우 귀찮게 느껴졌다.(필요한 건 몇번째 nom 변수를 제거할까? 만 알면 되는데!)
그래서 인코딩 부분을 다음과 같이 함수화했다.
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder
from scipy import sparse
### 범주형 데이터 전처리 함수
def cat_preprocessing(df, n_nom):
# df: 전처리할 데이터
# n_nom: 원하는 nom_* 변수의 개수 (만일 10을 넣으면 nom_0 ~ nom_9까지 포함하므로 베이스라인 모델과 동일함)
# 반환되는 값은 train_sprs, test_sprs
print('nom_* 변수는 nom_0 부터 nom_{0} 까지 사용되었습니다'.format(n_nom-1))
print(' ')
# bin_* 변수 전처리
bin_cols = [f'bin_{i}' for i in range(0, 5)]
bin_data = df[bin_cols]
bin_data['bin_3'] = bin_data['bin_3'].apply(lambda x: 1 if x == 'T' else 0)
bin_data['bin_4'] = bin_data['bin_4'].apply(lambda x: 1 if x == 'Y' else 0)
# ord_* 변수 전처리
ord_cols = [f'ord_{i}' for i in range(0, 6)]
ord_data = df[ord_cols]
ord1_enc = {'Novice': 0, 'Contributor': 1, 'Expert': 2, 'Master': 3, 'Grandmaster': 4}
ord2_enc = {'Freezing': 0 , 'Cold': 1, 'Warm': 2, 'Hot': 3, 'Boiling Hot': 4, 'Lava Hot': 5}
ord_data.loc[:, 'ord_1'] = ord_data.loc[:, 'ord_1'].map(ord1_enc)
ord_data.loc[:, 'ord_2'] = ord_data.loc[:, 'ord_2'].map(ord2_enc)
## 숫자 순위 부여
encoder = LabelEncoder()
ord_data['ord_3'] = encoder.fit_transform(ord_data['ord_3'].values)
ord_data['ord_4'] = encoder.fit_transform(ord_data['ord_4'].values)
ord_data['ord_5'] = encoder.fit_transform(ord_data['ord_5'].values)
## 숫자 스케일링
scaler = StandardScaler()
ord_data_scaled = scaler.fit_transform(ord_data)
# 앞에서 만든 bin_data & ord_data 합침
df2 = pd.concat([bin_data, pd.DataFrame(ord_data_scaled, columns = ord_data.columns)], axis = 1)
#--------------- nom_* 변수에서 어떤 변수를 포함할지 선택------------------
nom_cols = [f'nom_{i}' for i in range(0, n_nom)] # 변수 개수 조정
nm_list = ['day', 'month']
nom_cols.extend(nm_list)
nom_data = df[nom_cols]
encoder = OneHotEncoder()
nom_data_enc = encoder.fit_transform(nom_data)
# df2와 nom_data_enc를 결합
all_sprs = sparse.hstack([sparse.csr_matrix(df2), nom_data_enc], format = 'csr')
# all_sprs는 앞 부분은 train / 뒷 부분은 test 데이터이므로 분할
train_sprs = all_sprs[:len(train), :]
test_sprs = all_sprs[len(train):, :]
print('train data의 shape: ', train_sprs.shape)
print('test data의 shape: ', test_sprs.shape)
return train_sprs, test_sprs
위처럼 'cat_preprocessing' 함수를 만들어 보았다.
input으로는 전처리할 데이터 df와, 명목형 변수 몇 개를 포함할 것인지를 의미하는 n_nom 값이다.
예를 들어 n_nom = 10을 넣으면 nom_0부터 nom_9까지를 포함하게 되고, n_nom = 9를 넣으면 nom_0부터 nom_8 까지만 포함하게 된다.
이렇게 해서 반환되는 output은 집어넣은 df를 인코딩까지 완료해서 반환하는 train_sprs, test_sprs 이렇게 2개이다.
인코딩 함수를 만들고 나니, train_sprs와 test_sprs를 넣어서 또 로지스틱 회귀로 모델링 하는 부분도 중복되는 과정이라... 이것도 함수로 만들어 보았다!
### train, val set을 나눈 후에 기본 로지스틱 회귀 모델로 모델링 후, val set의 AUC score 출력 함수
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score
def logistic_train(train_sprs, y, tsize = 0.2, n_iter = 100):
# train, val set split
X_train, X_val, y_train, y_val = train_test_split(train_sprs, y, stratify = y, random_state = 99, test_size = tsize)
print('X_train의 shape: ', X_train.shape)
print('X_val의 shape: ', X_val.shape)
# 기본 모델링
model = LogisticRegression(random_state = 99, max_iter = n_iter)
model.fit(X_train, y_train)
y_pred = model.predict_proba(X_val)[:, 1]
# 성능 (AUC) 출력
print(' ')
print("val set's AUC score : {:.4f}".format(roc_auc_score(y_val, y_pred)))
이렇게 위의 logistic_train 함수를 사용하면 집어넣은 train data에 대해 로지스틱 회귀 모델링을 하고 AUC score를 출력해준다.
3. nom_* 변수에 따른 스코어 변화
이제 nom_* 변수를 어디까지 넣을 것인가에 따라 값을 뽑아보았다.
1) 베이스라인 모델과 동일한 경우
# baseline model과 동일
train_sprs, test_sprs = cat_preprocessing(all_data, 10)
logistic_train(train_sprs, train_target)
AUC score는 약 0.80으로 저번 포스팅에서 나온 값 0.799와 거의 같다.
2) nom_9 변수를 제외한 경우
# nom_9 제외
train_sprs, test_sprs = cat_preprocessing(all_data, 9)
logistic_train(train_sprs, train_target)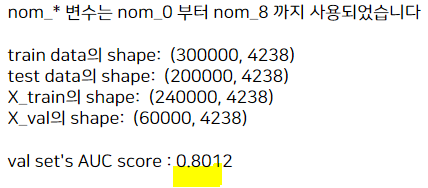
3) nom_8, nom_9 변수를 제외한 경우
# nom_8과 9 제외
train_sprs, test_sprs = cat_preprocessing(all_data, 8)
logistic_train(train_sprs, train_target)
nom_9 하나만 제거했을 때가 0.801로 가장 높아졌고, 더 많이 뺄수록 스코어가 점점 낮아지고 있다.
4) nom_7, nom_8, nom_9 변수를 제외한 경우
# nom_7, 8, 9 제외
train_sprs, test_sprs = cat_preprocessing(all_data, 7)
logistic_train(train_sprs, train_target)
이렇게 해서 변수를 더 많이 뺄수록 스코어가 계속 낮아지고 있어서, 여기서 중단하고 nom_9 변수 하나만 빼기로 했다.
이번에는 logistic_train 함수의 옵션을 좀 수정해서 성능을 더 높여보았다.
1) test_size를 줄여 학습에 사용되는 데이터를 늘리기
# nom_9 제외, test_size 좀 더 줄여보기
train_sprs, test_sprs = cat_preprocessing(all_data, 9)
logistic_train(train_sprs, train_target, tsize = 0.15)
# nom_9 제외, test_size 좀 더 줄여보기
train_sprs, test_sprs = cat_preprocessing(all_data, 9)
logistic_train(train_sprs, train_target, tsize = 0.1)
이렇게 test_size를 0.1로 줄였을 때, AUC 값이 0.805로 가장 높아졌다.
test_size를 더 줄이면 학습에 사용하는 데이터가 많아져 더 스코어가 높아질 수도 있겠지만, 과적합이 될 가능성도 높아지기 때문에 여기서 중단했다.
2) n_iter(max_iter) 값을 늘려 모델 고도화하기
# nom_9 제외, test_size = 0.1, n_iter 값 늘리기
train_sprs, test_sprs = cat_preprocessing(all_data, 9)
logistic_train(train_sprs, train_target, tsize = 0.1, n_iter = 200)
원래 디폴트는 n_iter = 100 이다.
여기서 n_iter는 로지스틱 회귀의 max_iter 값을 의미하는데, 이는 Gradient Descent 방식을 반복해서 몇 번 수행할 것인가? 를 의미한다. 그래서 max_iter 값이 커질수록 더 모델 성능을 높일 수 있는데, 대신 그만큼 반복해서 수행하므로 시간이 더 오래 걸린다.
이 데이터에선 특이하게도 이 값을 200으로 늘렸더니 0.804로 성능이 더 떨어졌다. 한 번만 더 해보자.
train_sprs, test_sprs = cat_preprocessing(all_data, 9)
logistic_train(train_sprs, train_target, tsize = 0.1, n_iter = 300)
300으로 늘렸을 때에도 여전히 성능이 좋아지지 않았다. 그래서 max_iter 값은 디폴트인 100을 유지하는 걸로!
4. 최종 제출 결과
최종적으로 nom_9 변수를 제외하고, max_iters는 100을 사용하기로 했다.
이제 train data 전체를 다 사용하여 모델을 만들어보자.
앞에서 validation set에 대한 AUC 성능은 0.805였으므로 성능이 얼마까지 향상할 수 있을지 기대해보자!
# 전체 데이터로 학습
model = LogisticRegression(random_state = 99, max_iter = 100)
model.fit(train_sprs, train_target)
# test data에 대해 예측
y_pred = model.predict_proba(test_sprs)
sub = pd.read_csv('sample_submission.csv')
del sub['target']
sub['target'] = y_pred[:, 1]
sub.to_csv('sub_sy_nom.csv', index = False)
[Test Score]
- public: 0.80421 / private: 0.79823
- 이전 포스팅에서 베이스라인 모델에 대한 public 성능이 0.802였음을 감안하면 → 0.804로 꽤 성능 향상을 보였다!
이전 포스팅에서도 봤었지만 train AUC 값과 test AUC 값이 큰 차이를 보이지 않는다는 점도 주목할 만 하다. 보통은 train 스코어에 비해 test 스코어가 더 낮아지는 것이 일반적이기 때문.. (인공적으로 만든 데이터이기 때문인가?!)
이번에는 nom_9 라는 변수를 하나 제거하는 것만으로 0.002의 성능 향상을 이뤄냈다.
다음 포스팅에선 로지스틱 회귀 모델을 튜닝하여 더 성능 향상을 기대해보자 :)
'Data Science > Kaggle' 카테고리의 다른 글
| [kaggle] 범주형 데이터 분석 - 머신러닝 2편 (로지스틱 회귀 하이퍼파라미터 튜닝) (2) | 2022.08.06 |
|---|---|
| [kaggle] 범주형 데이터 분석 - 변수 인코딩 & Baseline model (0) | 2022.08.04 |
| [kaggle] 범주형 데이터 분석 프로젝트 - EDA 2편 (0) | 2022.07.15 |
| [kaggle] 범주형 데이터 분석 프로젝트 - EDA 1편 (2) | 2022.07.14 |
| [kaggle] Bike Sharing Demand: ML 성능 개선 3편 (머신러닝 결측치 처리) (2) | 2022.07.03 |



