
Yours Ever, Data Chronicles
[kaggle] 범주형 데이터 분석 - 머신러닝 2편 (로지스틱 회귀 하이퍼파라미터 튜닝) 본문
저번 포스팅에서는 명목형 변수 중에서 nom_9 변수를 제거하여 0.804의 성능으로 향상시켰다.
이번 포스팅에서는, 사용했던 모델인 '로지스틱 회귀' 모델을 하이퍼 파라미터 튜닝하여 좀 더 성능을 향상시켜 보자!
데이터를 불러오는 과정은 앞의 포스팅과 똑같으므로 생략하고,
범주형 변수 인코딩 하는 부분과 모델 하이퍼 파라미터 튜닝하는 부분은 함수로 만들어서 좀 더 코드를 간결하게 만들어보았다.
참고로 하이퍼 파라미터 튜닝은 시간이 꽤 오래 걸리니 코드 실행 시 주의하자! (적으면 10분, 많으면 40분까지도 걸린다)
전체 코드는 이 깃허브에서 다운받을 수 있다 :)
✔Table of Contents
1. nom_9 변수 제외 & 하이퍼 파라미터 튜닝 함수화
먼저 데이터를 불러오고, 데이터 인코딩 하는 부분은 저번 포스팅에서 한 것과 완전히 동일하므로 생략한다.
저번 포스팅에서 만든 cat_preprocessing 함수를 적용하여 인코딩 완료된 데이터셋을 가져온다.
train_sprs, test_sprs = cat_preprocessing(all_data, 9)
위 코드를 실행하면 nom_9 변수는 제외하고, 인코딩이 완료되어 train, test 데이터셋으로 train_sprs, test_sprs가 만들어지게 된다.
이번엔 로지스틱 회귀의 하이퍼 파라미터 튜닝을 해보자.
로지스틱 회귀의 경우, 하이퍼 파라미터로 여러 가지가 있지만 나는 그중에서 3개를 튜닝해볼 것이다.
- penalty: 어떤 규제를 적용할 것인지를 선택. L1 규제의 경우 'l1', L2 규제는 'l2' 로 입력 (디폴트는 l2)
- C: 대표적인 로지스틱 회귀의 하이퍼파라미터로, Cost Function의 Cost를 의미하며 값이 크면 훈련을 더 복잡하게 하므로 규제가 약해진다. 반대로 Cost 값이 작으면 강한 규제가 적용됨. (디폴트는 1)
- max_iter: 로지스틱 회귀의 Gradient Descent 방식을 몇 번 반복해서 수행할 것인지를 의미함 (디폴트는 100)
하이퍼 파라미터 튜닝으로는 사이킷런의 그리드 서치(GridSearchCV)를 사용하였다.
하이퍼 파라미터 튜닝용 함수 'logistic_tuning'을 이렇게 만들었다.
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
## 하이퍼파라미터 튜닝용 함수
def logistic_tuning(train_sprs, y, params):
model = LogisticRegression(random_state = 99)
# 파라미터 튜닝(train data 전체를 넣어서 5-fold cv)
grid = GridSearchCV(model, params, scoring = 'roc_auc', cv = 5)
grid.fit(train_sprs, y)
print(grid.best_params_)
print(grid.best_score_)
return grid.best_estimator_
train data와 파라미터 값을 넣으면 5-fold 그리드서치를 수행하는 함수이다.
%%time
param1 = {'penalty':['l2', 'l1'], 'C':[0.01, 0.1, 1, 5, 10], 'max_iter': [100, 500]}
logistic_tuning(train_sprs, train_target, params = param1)
첫 번째로 param1 파라미터를 적용해 그리드서치를 수행하였다.
(참고로 %%time 이라는 magic function을 사용하면 수행하는 데 걸리는 시간이 어느 정도였는지가 나온다. 내 컴퓨터에선 12분이나 걸렸다)
결과를 보면 C = 0.1, max_iter = 500, penalty = 'l2'일 때 AUC가 0.801로 가장 최적의 성능이라고 한다.
여기서 penalty = 'l2'는 디폴트와 같으므로, C와 max_iter 파라미터만 다시 튜닝해보았다.
%%time
# 좀더 세분화하여 파라미터 튜닝 (5-fold cv)
param2 = {'C':[0.05, 0.1, 0.125, 0.15, 0.5], 'max_iter': [300, 500, 700, 900]}
logistic_tuning(train_sprs, train_target, params = param2)
이번엔 C와 max_iter 값을 더 잘게 쪼개서 넣어보았다.
C = 0.125, max_iter = 300일 때 AUC가 0.801로 가장 최적의 성능이다. 마지막으로 한번만 더 쪼개보자.
%%time
# 좀더 세분화하여 파라미터 튜닝 (5-fold cv)
param3 = {'C':[0.1, 0.125, 0.15], 'max_iter': [200, 300, 400, 500]}
logistic_tuning(train_sprs, train_target, params = param3)
더 잘게 쪼갰지만 결과는 똑같이 C = 0.125, max_iter = 300 일 때의 성능이 가장 좋았다.
그리고 결과를 보면 알겠지만, 하이퍼 파라미터 튜닝을 하면 시간이 10~20분으로 오랜 시간이 걸리지만, 성능은 크게 차이가 없다.
train AUC 값은 5-fold cv를 했을 때 0.801189 정도 나왔다. 전체 데이터를 학습하여 예측해보면 더 성능이 좋아질 것이긴 하지만,
그리드서치를 하기 전 저번 포스팅에선 0.804 성능이 나왔음을 감안하면 성능이 소폭 감소하였다.
아무튼 param3 파라미터를 적용한 모델로 test 데이터에 대해 예측해보자.
# 파라미터 튜닝 결과 가장 AUC 값이 좋았던 건 이렇게 뽑으면 된다!
model = logistic_tuning(train_sprs, train_target, params = param3)
y_pred = model.predict_proba(test_sprs)[:, 1]
# sub 데이터에 담아서 제출
sub = pd.read_csv('sample_submission.csv')
del sub['target']
sub['target'] = y_pred
sub.to_csv('sub_sy_final.csv', index = False)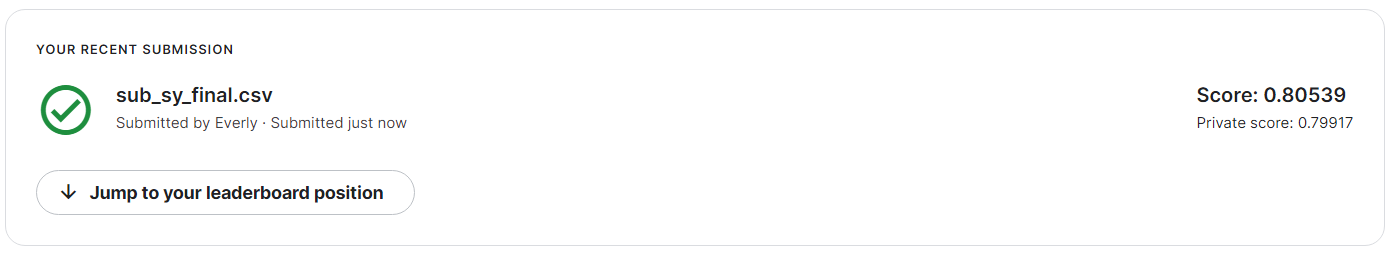
[Test Score]
- public: 0.80539, private: 0.79917
- train AUC가 0.801이었음을 감안하면, 오히려 test AUC를 뽑았을 때 성능이 더 좋았다.
- 저번 포스팅에서 만들었던 0.804보다 성능이 향상된 0.805가 나왔다.
2. 모든 변수 포함 & 하이퍼 파라미터 튜닝
앞에서 nom_9 변수를 제거하고 하이퍼 파라미터 튜닝을 해서 0.805를 만들었다.
하지만 1등이 0.808이라 좀 더 성능 향상이 필요하다.
바로 이전 포스팅에서 nom_* 변수는 제거하나 제거하지 않으나 큰 차이가 없었다. 심지어 변수를 많이 제거할수록 성능이 더 안 좋아지는 경향이 있었다.
그래서 이번에는 nom_9 변수를 아예 제거하지 않고(즉 모든 변수를 포함하고) 하이퍼 파라미터 튜닝을 진행해보았다!
결과를 미리 말하자면 가장 성능이 잘 나온 방법이었다.
train_sprs, test_sprs = cat_preprocessing(all_data, 10)
전체 변수를 포함해서 다시 인코딩을 시켰다.
다시 하이퍼 파라미터 튜닝을 해보자. (시간이 오래 걸리니 주의)
%%time
param1 = {'penalty':['l2', 'l1'], 'C':[0.01, 0.1, 1, 5, 10], 'max_iter': [100, 500]}
logistic_tuning(train_sprs, train_target, params = param1)
penalty = 'l2'일 때(디폴트), C = 0.1, max_iter = 500일 때 AUC가 0.804로 가장 성능이 좋았다.
아까 만들었던 튜닝 결과가 0.801이었는데 더 성능이 좋아졌다!
마찬가지로 C와 max_iter 값을 세분화하여 파라미터 튜닝을 시켜보았다.
%%time
# 좀더 세분화하여 파라미터 튜닝 (5-fold cv)
param2 = {'C':[0.05, 0.1, 0.125, 0.15, 0.5], 'max_iter': [300, 500, 700, 900]}
logistic_tuning(train_sprs, train_target, params = param2)
이번엔 C = 0.125, max_iter = 300일 때 가장 좋은 성능이다.
한번만 더 튜닝해보자.
%%time
# 좀더 세분화하여 파라미터 튜닝 (5-fold cv)
param3 = {'C':[0.1, 0.125, 0.15], 'max_iter': [200, 300, 400, 500]}
logistic_tuning(train_sprs, train_target, params = param3)
결과적으로 아까 했던 최적의 파라미터 조합과 똑같이 나왔다.
그럼 이제 이 파라미터를 적용하여 다시 test data에 대해 예측해보자.
3. 최종 결과는?
# 파라미터 튜닝 결과 가장 AUC 값이 좋았던 건 이렇게 뽑으면 된다!
model = logistic_tuning(train_sprs, train_target, params = param3)
y_pred = model.predict_proba(test_sprs)[:, 1]
# sub 데이터에 담아서 제출
sub = pd.read_csv('sample_submission.csv')
del sub['target']
sub['target'] = y_pred
sub.to_csv('sub_sy_final_new.csv', index = False)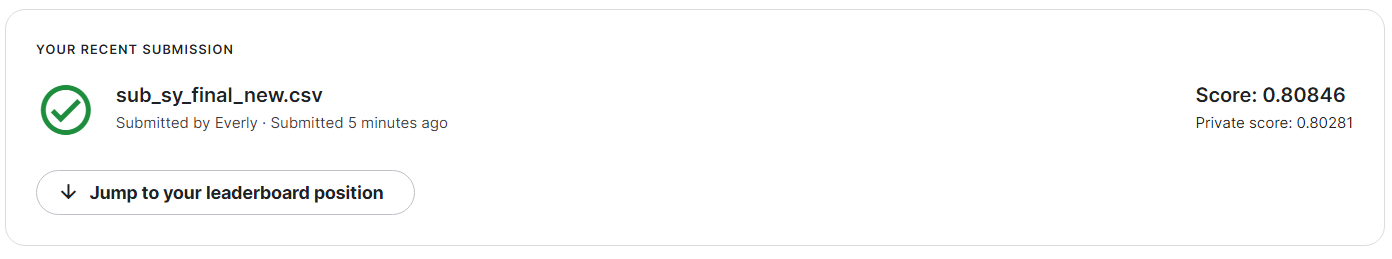
최종 결과는 public: 0.80846, private: 0.80281 으로 지금까지 했던 스코어 중 최고였다!
리더보드에서 최종 순위를 확인해 보면...
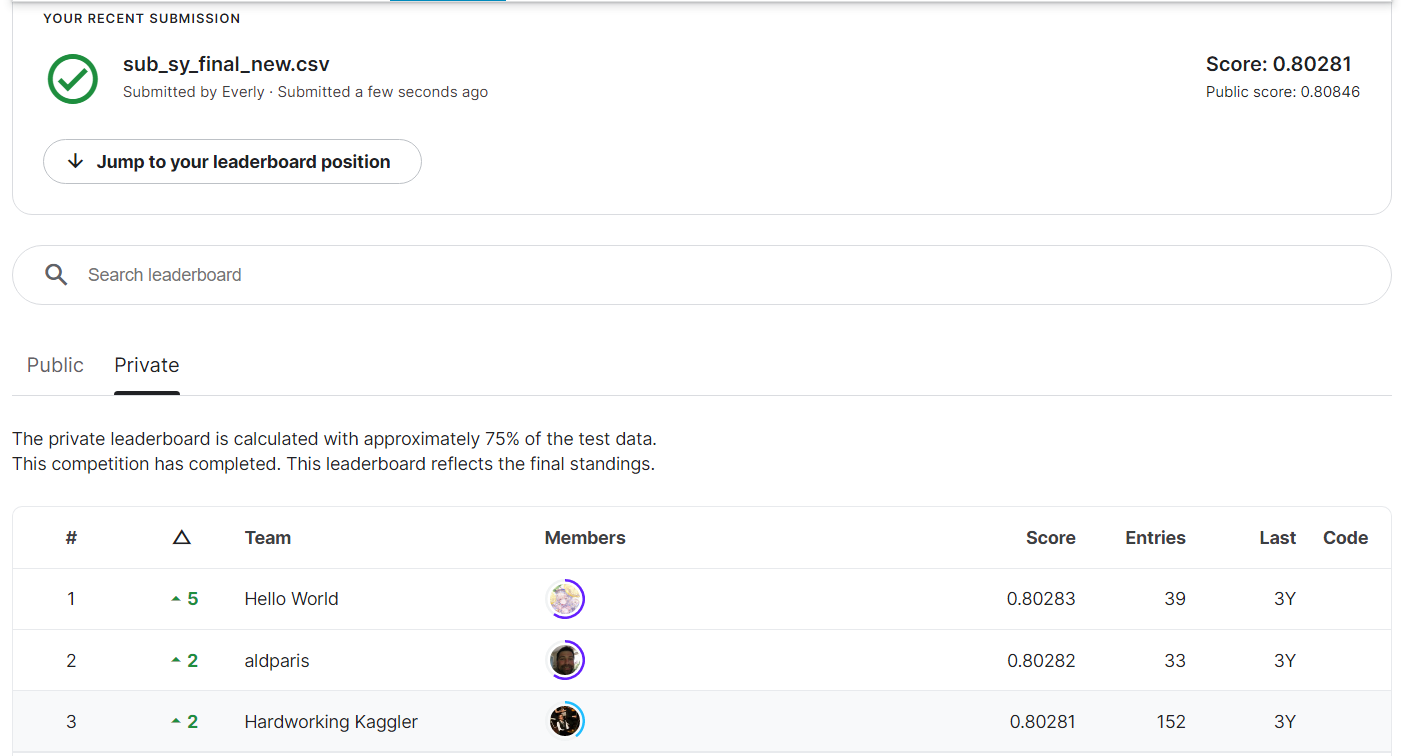
이처럼 private 리더보드에서 나의 성적인 0.80281은 3위를 기록했다 :)
[마치며]
범주형 데이터로만 이루어진 머신러닝은 처음 하는 것이었는데 꽤 재밌는 경험이었다.
이번 대회의 데이터셋은 좀 특이하게도, train score보다 test score가 좀 더 잘 나오는 경향이 있는 것 같다. (일반적으로는 그 반대이다. 과적합 때문에)
이번 데이터셋이 인공적으로 제작된 데이터라는 것이 이유 중 하나가 아닐까.
그리고 리더보드를 확인하면 알겠지만, 전반적으로 스코어 차이가 그렇게 크게 나지 않는다. 그래서 성능도 0.001 이렇게 조금 향상시켰는데도 순위가 갈리는 경향이 있었다.
교훈으로는,, 변수를 함부로 빠면 안 되는구나..! 라는 것을 알았다.
원래는 의미 없는 변수는 되도록이면 다 빼버리고 튜닝을 해서 완성시키는 걸 좋아하는 편인데, 이번 대회같은 경우엔 nom_* 변수를 전부 포함하고 튜닝하는 것이 가장 좋았다. 확실하게 의미가 없다는 것을 잘 검증하고 변수를 선택해야 할 것 같다 :)
'Data Science > Kaggle' 카테고리의 다른 글
| [kaggle] 범주형 데이터 분석 - 머신러닝 1편 (변수 선택) (0) | 2022.08.05 |
|---|---|
| [kaggle] 범주형 데이터 분석 - 변수 인코딩 & Baseline model (0) | 2022.08.04 |
| [kaggle] 범주형 데이터 분석 프로젝트 - EDA 2편 (0) | 2022.07.15 |
| [kaggle] 범주형 데이터 분석 프로젝트 - EDA 1편 (2) | 2022.07.14 |
| [kaggle] Bike Sharing Demand: ML 성능 개선 3편 (머신러닝 결측치 처리) (2) | 2022.07.03 |



