
Yours Ever, Data Chronicles
[pandas] 결측치 다루기 - 결측치 확인, 결측치 처리(NaN drop, interpolate) 본문
✔Table of Contents
참고로 데이터셋과 코드 파일은 저의 깃허브에 올려두었으니 다운받으시면 됩니다! :)
GitHub - suy379/python_for_DA: Python for Data Analysis (데이터 분석을 위한 중요한 파이썬 모음)
Python for Data Analysis (데이터 분석을 위한 중요한 파이썬 모음). Contribute to suy379/python_for_DA development by creating an account on GitHub.
github.com
1. 결측치 확인하기
데이터를 받은 후, 결측치가 얼마나 있는지를 확인하는 것은 무엇보다도 중요하다.
결측치라는 것은 말 그대로 값이 없는 것으로, 이렇게 값이 없다면 일반 연산을 한다거나, 머신러닝 모델을 만드는 등의 일을 할 수 없기 때문이다.
결측치를 확인하는 메서드는 다음과 같다.
- 각 열별 결측치 수: df.isnull().sum() / df.isna().sum()
- 각 열별 결측치가 아닌 것의 수: df.notnull().sum() / df.count()
- 위의 메서드를 활용해 특정 열의 결측치를 전부 제거한 데이터만 반환할 수도 있다!
import pandas as pd
import seaborn as sns
## 데이터는 seaborn에서 기본적으로 제공하는 titanic 사용
df = sns.load_dataset('titanic')
df.head()
오늘의 예제 데이터는 seaborn에서 기본적으로 제공하는 타이타닉 데이터셋(titanic)을 활용하였다.
head로만 뽑아봐도 몇몇 NaN으로 써져 있는 결측치들이 보인다. 실제로 몇 개인지 확인해보자!
1) 열별 NaN의 수 확인
#열별 결측치의 수 -> 특정 열에만 결측치가 있다
df.isnull().sum()
모든 열은 아니고 특정 열에만 결측치가 있다.
참고로 결측치를 확인하는 메서드는 isnull 뿐만 아니라, isna도 써도 된다.
# 동일한 결과
df.isna().sum()
전체 데이터 수에 비해 이 결측치의 양은 많은 양일까?
간단하게 전체 데이터프레임의 수인 len(df)로 나눠보면, 열별 결측치 비율을 뽑아볼 수 있다.
# 전체 개수 대비 많은 편일까? -> 각 열별 결측치의 비율
print(df.isna().sum()/len(df))
deck 열은 결측치가 무려 77%이며, age 열도 약 20%가 결측치이다.
그 외에 embarked, embark_town도 소수의 결측치가 존재한다.
2) 열별 NaN이 아닌 것의 개수 확인
그렇다면 결측치가 아닌 것의 개수만 세려면 어떻게 해야 할까? 다음의 메서드를 사용한다.
#그렇다면 결측치가 아닌 것의 개수는?
df.notnull().sum()
혹은 그냥 count만 붙여도 된다.
# 동일한 결과
df.count()
여기서는 일괄적으로 데이터프레임 df 뒤에 메서드를 붙여 전체 열의 결측치/결측치 아닌것의 개수를 세었는데,
당연히 특정 열의 결측치/결측치 아닌것의 개수를 구할수도 있다. (예시: embarked 열의 결측치 수)
# embarked 열의 결측치 / 결측치 아닌것의 개수
print(df['embarked'].isnull().sum())
print(df['embarked'].notnull().sum())
3) 결측치가 아닌 데이터만 추출(불린 인덱싱)
앞서 봤던 isnull, notnull 등의 메서드는 모두 불린(Boolean) 형태로 되어 있다.
즉, isnull의 경우엔 결측치가 맞다면 True, 아니면 False를 반환한다.
또한 notnull은 반대로 결측치가 아니어야 True, 맞으면 False를 반환한다.
df.notnull() #결측치가 아니면 True, 맞으면 False 반환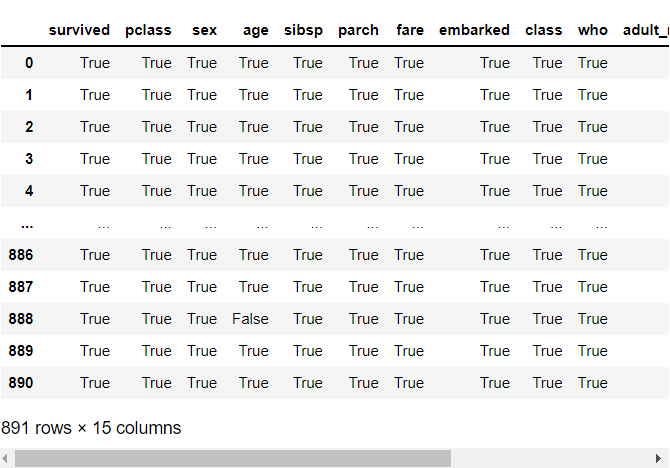
그러므로 불린 인덱싱(Boolean Indexing)을 활용할 수 있다!
다만, 전체 불린인덱싱은 불가능하다. 밑의 이미지처럼 NaN 값이 그대로 살아 있기 때문..
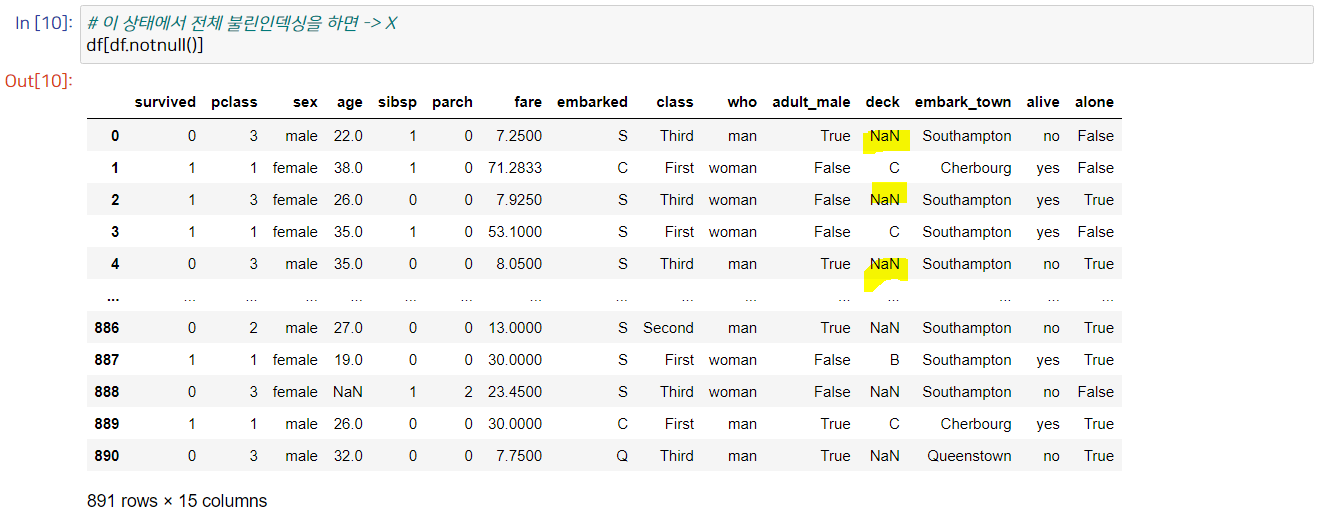
그래서 불린 인덱싱은 특정 열에 대해서 해줘야 한다. 즉, 특정 열에서만 결측치를 제외하는 방법을 사용한다.
예시로, deck 열의 결측치는 전부 다 삭제하고 싶다면 다음 코드를 사용하면 된다.
# 특정 열에 대해서 결측치를 제외하는 방법으로!
## deck 열 결측치는 전부다 삭제
df2 = df[df['deck'].notnull()]
display(df2.head())
print(len(df), len(df2))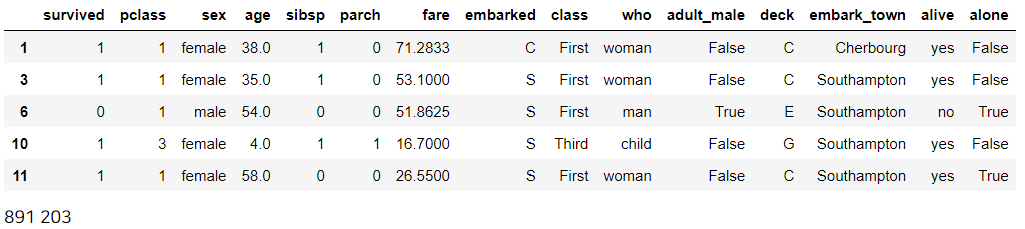
불린 인덱싱을 통해 deck 열에 결측치가 있으면 전부 삭제(행 삭제)하였다.
그런데 deck 열이 결측치가 77%나 있었다보니, 원래 891개였던 데이터의 수가 203개로 약 700개의 데이터가 날아가버렸다.
뒤에서도 살펴보겠지만, 이렇게 데이터가 너무 많이 삭제되는 경우엔 데이터 손실이 우려되므로 주의해야 한다!
참고로, 특정 열에서 결측치를 확인할 때 value_counts() 메서드에서 dropna = False로 설정해주는 방법도 있다.
df['deck'].value_counts(dropna = False)
2. 결측치를 처리하는 다양한 방법
- df['col'].fillna(임의의 값): 임의의 값으로 전부 채우기
- df['col'].fillna(method = 'ffill' or 'bfill'): 앞의 값 or 뒤의 값으로 채우기
- df['col'].interpolate(): 보간법(interpolate) 사용하기
- df.dropna(how = 'any' or 'all'): 아예 누락값이 있는 행 drop
- 또는 머신러닝으로 다른 열을 활용해 결측치 열을 예측하는 방법도 있다
1) 임의 값으로 전부 채우기
처리해야 하는 데이터프레임의 크기가 매우 큰 경우에 자주 사용하는 방법이다.
특정 열(컬럼)에 대해서만 임의값으로 채우는 방법을 자주 사용하는데,
모든 열에 대해서도 임의값으로 채우고 싶은 경우라면(예를 들어, 모든 열에 있는 NaN 값을 0으로 바꾸기) 이 경우 컬럼 지정 없이 그냥 df.fillna(0, inplace = True)를 써주면 된다.
예시로, age 열의 결측치를 age의 평균값으로 채워본다면 이렇게 하면 된다.
# 예시로 age의 결측치를 age의 평균값으로 채워보자.
df['age'].fillna(df['age'].mean(), inplace = True)
print(df['age'].isna().sum()) #결측치가 사라짐
inplace 옵션은 따로 변수로 지정하지 않아도 해당 데이터프레임에 적용할 것인지를 의미한다. 그래서 inplace = True를 사용하면 df의 'age' 열의 결측값이 평균값으로 모두 들어간다.
어쨌든 age 열의 결측치를 isna 메서드로 확인하면 0으로 결측치가 모두 사라졌다.
숫자뿐만 아니라 문자도 넣어줄 수 있다. 예시로 embark_town의 결측치를 보자.
# 숫자뿐만 아니라 문자도 된다!
# 예시로 embark_town의 분포를 보면
df['embark_town'].value_counts(dropna = False)
현재 결측치가 2개 있다.
가장 다수의 값인 'Southampton' 으로 채워주려면..
df['embark_town'].fillna('Southampton', inplace = True)
#다시확인
df['embark_town'].value_counts(dropna = False)
NaN이 사라졌음을 확인하였다.
2) 결측치의 앞의 값 or 뒤의 값으로 채우기
이 경우에는 앞의 케이스와 똑같이 fillna 메서드를 사용하는데, method 옵션을 추가하면 된다.
method에서 'ffill'을 쓰면 결측치의 앞의 값 / 'bfill'을 쓰면 결측치의 뒤의 값으로 채워진다.
참고로, ffill을 사용하는 경우엔 데이터의 맨 처음 값이 NaN이면 이 값이 채워지지 못하고
bfill을 사용하는 경우엔 데이터의 맨 마지막 값이 NaN인 경우 이 값이 채워지지 못해 그대로 NaN으로 출력된다.
예를 들어, age 열을 결측치 처리하기 전으로 다시 봐보자.
# 예를 들어 age의 값을 앞의 값으로 채워보자.
df.iloc[190:200, 0:4]
2개의 NaN의 값을 바로 아래에 위치한 42, 24로 채워줄 것이다. method = 'bfill'을 사용하면
df['age'].fillna(method = 'bfill', inplace = True)
df.iloc[190:200, 0:4]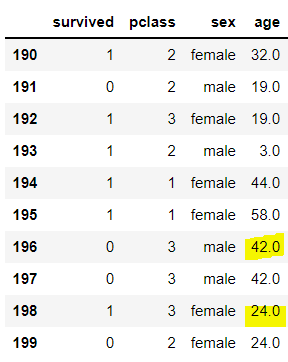
이번에는 deck 열의 값을 채워보자. ffill을 사용해서 채워준다.
# 이번엔 deck 열-> 얘는 ffill로 채워보자.
df.iloc[:10, 10:15]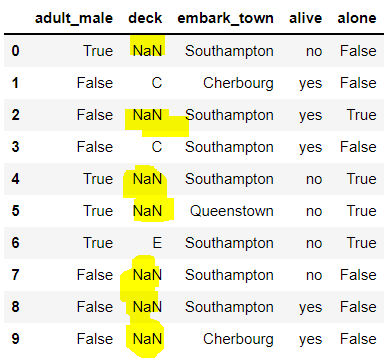
df['deck'].fillna(method = 'ffill', inplace = True)
df.iloc[:10, 10:15]
대부분 잘 채워졌으나, 맨 첫번째 값이 NaN이기 때문에 ffill로 채우면 이 값은 그대로 NaN으로 출력된다.
3) 보간법을 사용하여 채우기(interpolate)
이 방법은 누락값의 양쪽에 있는 값으로 중간값을 구해 결측치를 채우는 방법이다.
수치형 데이터일 때만 사용하며, 맨 첫번째 or 마지막 행이 NaN일 때에는 중간값을 구하지 못하므로 그대로 NaN이 나오게 됨에 주의!
# 예를 들어 age의 값을 양옆의 중간값으로 채워보자.
df.iloc[190:200, 0:4]
다시 앞에서 봤던 age 열이다.
여기 있는 2개의 NaN 값을 보간법으로 채워보자.
즉, 196번 행은 195번과 197번 행의 값인 58, 42의 중간값을 구해 NaN에 넣어보자!
df['age'].interpolate(inplace = True)
df.iloc[190:200, 0:4]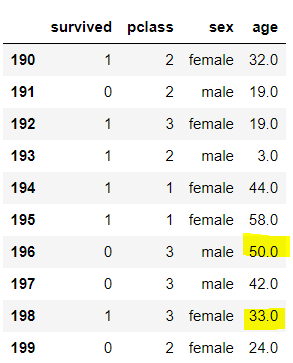
이렇게 잘 넣어졌다.
4) 결측치가 있는 행 아예 삭제하기
여기서는 dropna 메서드를 사용하며, 특정 열에 대해서는 사용이 불가능하다.(무조건 전체 열을 대상으로 함)
how 옵션으로 다음을 사용할 수 있다
- how = 'any' : 하나의 셀이라도 NaN이 있으면 그 행을 전체 삭제
- how = 'all' : 한 행의 모든 셀에 NaN이 있어야 그 행을 전체 삭제
이 방법은 아예 행 자체를 삭제하는 것이므로, 결측치가 많은 데이터의 경우엔 데이터 수가 너무 적어질 수도, 또는 너무 편향된 데이터가 될 수도 있음에 주의하자! (결측치가 너무 많거나 데이터의 수가 적다면 이 방법은 최후의 수단으로 남겨둬야 한다)
print(df.shape)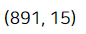
현재 데이터의 수는 891개이다.
how = 'any'를 사용하면 결측치가 단 하나의 셀에만 있어도 그 행 전체를 drop하게 되므로, how = 'any'를 사용한다면 데이터가 많이 줄어들 것이다. (특히 맨 앞에서 살펴봤듯, deck 열엔 결측치가 688개나 있기에..)
# how = 'any'
df2 = df.dropna(how = 'any')
print(df2.shape) #이렇게 182개만 남게 되었음
이렇듯 많은 데이터가 삭제되어 182개만 남겨졌다.
반대로, how ='all'을 사용하면 어떨까?
# how = 'all' 사용하는 경우
df3 = df.dropna(how = 'all')
print(df3.shape)
how = 'all'은 행 내의 모든 셀에 NaN이 들어있는 경우만 삭제되므로, 잘 삭제되지 않았다. 여기서도 891개의 데이터 중에서 아무것도 삭제되지 않았다.
사실 모든 셀이 다 NaN으로 이루어져 있는 데이터는 잘 없기 때문에 이 경우는 잘 사용하지 않는다.
이렇게 하여 데이터에 결측치(NaN)가 있는 경우 이를 확인하는 방법과 처리하는 방법에 대해 알아보았다.
마지막에 dropna는 행을 drop하는 경우였는데, 참고로 axis = 1로 설정하면 열을 drop할 수도 있다.
그래서 다음 포스팅에선 참고용으로 결측치가 특정 개수, 특정 비율 이상인 열을 drop하는 케이스에 대해 알아보자!
'Skillset > Python' 카테고리의 다른 글
| 파이썬 데이터프레임 인덱싱하기 - python dataframe indexing, slicing (0) | 2022.06.23 |
|---|---|
| [pandas] 결측치가 특정 개수, 특정 비율 이상인 열 drop하는 방법 (0) | 2022.06.22 |
| [pandas] 데이터 연결하기 - pd.concat, pd.merge 차이점 및 사용법 (0) | 2022.06.18 |
| python 열의 문자열을 분리해 N개 열로 만드는 방법(str, split, get) (2) | 2022.06.17 |
| [pandas] pd.melt, pd.pivot_table을 활용해 데이터프레임 가공하기 (2) | 2022.06.17 |



