
Yours Ever, Data Chronicles
파이썬 데이터프레임 인덱싱하기 - python dataframe indexing, slicing 본문
데이터프레임을 다룰 때, 정말 자주 쓰이고 기본적인 기능인 인덱싱(indexing)과 슬라이싱(slicing)에 대해 알아보자. 데이터를 인덱싱할 때 기준은 1차원, 2차원 기준으로 설명하였다.
먼저 데이터는 seaborn에서 제공하는 기본 데이터셋인 titanic(타이타닉)을 활용하였다.
import seaborn as sns
df = sns.load_dataset('titanic')
df.head()
✔Table of Contents
1. 1차원 인덱싱
먼저 1차원 인덱싱은 행만 인덱싱 or 열만 인덱싱하는 경우를 의미한다.
데이터가 연속된 경우는 콜론(:)을 사용해 인덱싱하며, 연속되지 않은 경우엔 괄호를 2개 쓴다.
열 인덱싱
열을 인덱싱하는 것은 아주 간단한데, 그냥 데이터프레임 뒤에 원하는 열을 대괄호 [ ] 를 이용해 추출해주면 된다.
위의 데이터셋에서 survived 열을 추출한다고 하면,
df['survived']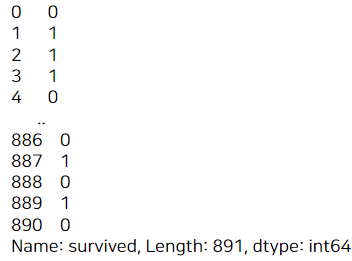
이와 같이 Series(시리즈)의 형태로 뽑힌다. 데이터프레임에서 열 1개는 시리즈와 같기 때문!
만일 열을 인덱싱하여 DataFrame의 형태로 뽑고 싶다면 괄호를 2개 사용한다.
df[['survived']]
열은 1개 말고 여러개도 뽑을 수 있다.
# 여러개의 열 인덱싱
df[['survived', 'pclass', 'sex']]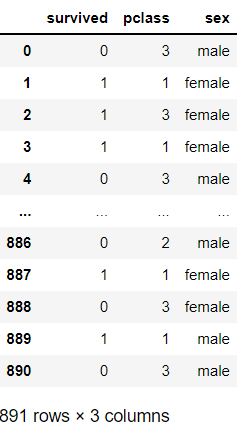
행 인덱싱
행을 인덱싱하기 위해서는 메서드인 loc와 iloc를 사용한다. 이 2개의 메서드는 받는 인자가 서로 다르다.
- loc: 인덱스 기준
- iloc: 행 번호 기준 (반드시 숫자)
이 titanic 데이터셋처럼 인덱스가(가장 왼쪽의 볼드체로 표시됨) 숫자형으로 된 경우는 loc와 iloc가 가리키는 것이 동일하다.
하지만 가끔 보면 데이터프레임의 인덱스가 숫자가 아닌 문자로 되어있을 수도 있기에, 이런 경우 loc로는 문자를, iloc로는 행 번호(숫자)를 넣어주어야 한다.

예시로 가상의 데이터를 한번 만들어보았다.
import pandas as pd
sy = [1,2,3]
sy1 = pd.DataFrame(sy, columns = ['Everly'])
sy1.index = ['A', 'B', 'C']
sy1
sy1 이라는 데이터프레임의 경우, 인덱스는 'A', 'B', 'C' 이다.
하지만 행 번호는 0, 1, 2이다.
이런 상황에서 iloc와 loc를 써보면?
sy1.iloc[1:3]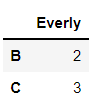
iloc를 쓰면 행 번호 1, 2인 데이터가 뽑혔다. 그러나 loc로 쓰게 되면
sy1.loc[1:3]
이런 식으로 에러가 나게 된다.
그래서, 이 데이터에서 loc를 사용하고자 하는 경우엔 반드시 인덱스 이름을 지정해주자.
sy1.loc['B':'C']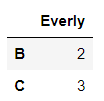
또한 행 인덱싱을 할 때 콜론(:)을 많이 쓰는데, 이를 쓰면 연속된 숫자를 가리킨다.
예를 들어 0:3은 0, 1, 2, 3을, :3은 0, 1, 2, 3을 가리킨다.
다만 조심할 점은 loc는 마지막 숫자를 포함하지만, iloc는 마지막 숫자를 포함하지 않는다. 바로 예제로 알아보자!
df.loc[1:3]
df.iloc[1:3]
재미있는 점을 또 하나 알아보자면, loc는 인덱스를 나타내므로 데이터프레임 내 인덱스로 주어진 숫자만 꼭 입력해야 한다.
하지만 iloc는 그저 행 번호일 뿐이므로, 인덱스 숫자가 아니어도 된다.
예를 들어, -1번 데이터를 뽑아보자.
df.iloc[-1]
위와 같이 -1번을 iloc로 뽑으면 데이터의 맨 마지막 행이 뽑힌다.
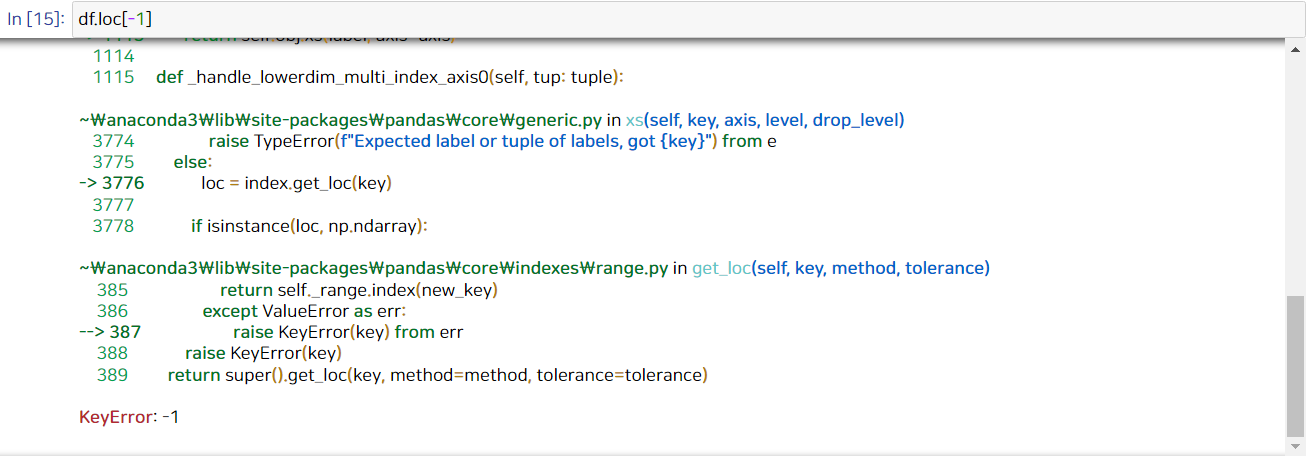
그러나 loc로 -1을 뽑게 되면 이렇게 에러가 난다는 것!
인덱스에 '-1' 이라는 숫자가 없기 때문이다.
마지막으로, 행이 연속된 경우엔 콜론(:)을 사용해서 뽑아줬는데, 연속되지 않은 경우라면?
괄호를 2개 사용해주면 된다. 이는 loc나 iloc나 똑같다.
df.loc[[2, 34, 78]]
df.iloc[[2, 34, 78]]
2. 2차원 인덱싱
앞의 1차원 인덱싱에선 열만 뽑거나, 행만 뽑는 경우였다.
2차원 인덱싱의 경우 데이터프레임의 특정 행 + 특정 열의 값을 뽑고자 할 때 사용한다.
앞에선 그저 df.loc[인덱스] 로 사용하면 되었지만, 이번엔 df.loc[행 인덱스, 열 인덱스] 이렇게 2개의 input을 받는다고 생각하면 된다.
마찬가지로 데이터가 연속된 경우는 콜론(:)을 사용해 인덱싱하며, 연속되지 않은 경우엔 괄호를 2개 쓴다.

예를 들어, 3번 인덱스의 성별이 궁금할 때는 다음을 사용한다.
df.loc[3, 'sex']
#또는
df.iloc[3, 2]
연속된 데이터를 뽑고자 한다면 콜론(:)을 사용한다.
df.loc[100:111, 'sex':'sibsp']
#또는
df.iloc[100:111, 2:5]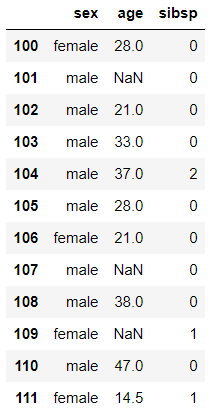
콜론은 전부 다 가져오는 것도 가능하다.
예를 들어, 행 인덱스는 5번부터 7번인데, 모든 열을 가져오고 싶다면?
df.loc[5:7, :]
또한 슬라이싱하는 것도 가능하다.
iloc를 사용하여, 행 번호는 0번~4번까지만 뽑고, 열은 class 이후의 것을 모두 뽑고자 한다면?
df.iloc[:5, 8:]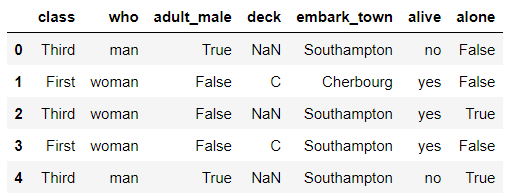
연속되어 있지 않은 경우엔 괄호 2개를 사용한다.
전체 행을 가져오되, 'sex', 'class' 열만 가져오고자 한다면? 멀리 떨어져 있는 열이므로 이중 괄호를 사용하자.
df.loc[:, ['sex', 'class']]
멀리 떨어져 있는 행도 가져올 수 있다. 55번 행, 34번 행만 뽑고 싶다면? 그리고 열은 'survived', 'deck'만 뽑고 싶은 경우엔
df.loc[[55, 34], ['survived', 'deck']]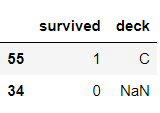
iloc를 사용하는 경우엔 숫자만 써야 한다. 이번엔 40, 41번 행과 0, 2, 5번 열만 뽑아보자.
df.iloc[[40, 41], [0, 2, 5]]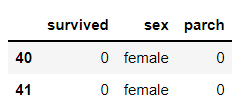
아주 편리한 기능: 범위 설정하기(range, 슬라이싱)
또한 인덱싱을 할 때는 range를 활용해 리스트로 지정을 해서 사용할 수도 있다.
예를 들어, 0번부터 5번 열만 뽑자고 해보자.
# 아님 리스트를 지정해서 사용도 가능
sy_list = list(range(6))
df.iloc[60:66, sy_list]
# 또는 한번에
df.iloc[60:66, list(range(0,6))]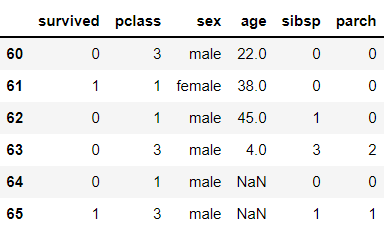
이렇게 range를 활용해도 0~5번 열을 뽑을 수 있다.
다만, range만 쓰면 안되고 꼭 이를 list 형태로 만들어줘야 한다.
(참고로 range는 range(시작인덱스, 끝인덱스, 간격) 을 input으로 받으며, 끝인덱스는 포함하지 않음)
이번엔 0~5번 열을 뽑되 2 간격을 두고 뽑아보자.
즉, 0번, 2번, 4번 열만 뽑는다.
# range는 간격을 설정할 수 있다
df.iloc[60:66, list(range(0,6,2))]
그런데 솔직히 range와 list를 모두 쓰기가 좀 번거롭다.
이런 경우엔 슬라이싱을 활용하는데, range에 넣었던 인자들을 모두 콜론(:)으로 연결하기만 하면 된다!!
# range와 같은 기능 = 슬라이싱
df.iloc[60:66, 0:6:2]
당연히 행에서도 사용이 가능하다.
df.loc[0:50:10, :]
'Skillset > Python' 카테고리의 다른 글
| [pandas] Series & DataFrame에서 자주 사용하는 유용한 메서드 (2) (0) | 2022.06.27 |
|---|---|
| [pandas] Series & DataFrame에서 자주 사용하는 유용한 메서드 (1) (0) | 2022.06.27 |
| [pandas] 결측치가 특정 개수, 특정 비율 이상인 열 drop하는 방법 (0) | 2022.06.22 |
| [pandas] 결측치 다루기 - 결측치 확인, 결측치 처리(NaN drop, interpolate) (0) | 2022.06.21 |
| [pandas] 데이터 연결하기 - pd.concat, pd.merge 차이점 및 사용법 (0) | 2022.06.18 |



