
Yours Ever, Data Chronicles
[pandas] 데이터 연결하기 - pd.concat, pd.merge 차이점 및 사용법 본문
이번 포스팅에선 데이터를 연결하는 방법(즉, 데이터 조인(join)시키는 방법)에 대해 알아본다.
데이터 분석을 하다보면 여러 개의 데이터프레임을 연결해야 하는 경우가 많다. 깔끔한 데이터(Tidy Data)를 만들기 위해 꼭 알아둬야 하는 메서드이다.
이번 장에서는 판다스의 대표적인 data join 메서드 2가지인 concat과 merge에 대해 예제로 알아보자.
(참고로 데이터셋과 주피터 노트북 파일은 이 깃허브를 참고하세요!)
✔Table of Contents
먼저 임의의 데이터 df1, df2, df3를 생성하였다.
이는 내가 임의로 만든 데이터로, 1반, 2반, 3반 학생들 3명의 시험 성적 데이터이다.
import pandas as pd
# df1: 1반 학생들(3명)의 시험 성적
a = [100, 66, 80, 97]
b = [26, 53, 45, 100]
c = [94, 100, 32, 43]
df1 = pd.DataFrame([a,b,c], columns = ['Korean', 'Math', 'English', 'Science'])
df1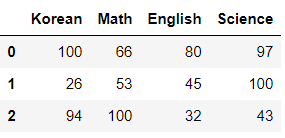
# df2: 2반 학생들(3명)의 시험 성적
a = [88, 94, 21, 39]
b = [82, 79, 19, 87]
c = [20, 10, 92, 13]
df2 = pd.DataFrame([a,b,c], columns = ['Korean', 'Math', 'English', 'Science'])
df2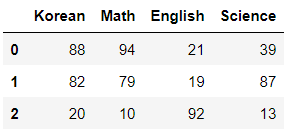
# df3: 3반 학생들(3명)의 시험 성적
a = [39, 18, 20, 72]
b = [47, 98, 50, 100]
c = [62, 79, 65, 81]
df3 = pd.DataFrame([a,b,c], columns = ['Korean', 'Math', 'English', 'Science'])
df3
1. pd.concat
pd.concat( [df1, df2, df3, ... ], axis = 0, ignore_index = False, join = 'outer')
- 반드시 df1, df2의 자리에는 데이터프레임(DataFrame) 형태만 넣어야 하며, 2개 이상의 데이터프레임을 한번에 넣을 수 있다.
- [디폴트] axis = 0 (row-bind) / 인덱스 초기화 X / outer join
- 합집합 형태로 데이터를 묶어야 할 때 사용하면 편리하다! (특히 데이터 간 공통되는 값이 없어 그냥 row-bind 또는 column-bind로 데이터를 연결하고자 하는 경우 Good)
먼저 디폴트 형태로 위의 3개 데이터프레임을 묶어보자.
# 디폴트 -> row-bind로 붙여지는 게 기본형태
pd.concat([df1, df2, df3])
이렇게 row-bind 형태로, 즉 행과 행이 쌓이는 형태로(같은 열을 가진 데이터끼리 묶여) 데이터가 만들어지는 것이 기본 형태이다.
가장 왼쪽의 인덱스를 보면 기본 인덱스 '0, 1, 2'가 그대로 남아 있는 것이 특징!
만일 축을 axis = 1로 바꿔보면 어떻게 될까?
# 축을 바꿔보면? -> col-bind로 붙여짐 (같은 인덱스 번호인 애들끼리)
pd.concat([df1, df2, df3], axis = 1)
축을 axis = 1로 바꾼다면 column-bind 형태로, 즉 열 옆에 열이 붙여지는 형태로(같은 인덱스를 가진 데이터끼리 묶여) 데이터가 만들어진다.
그래서 df1, df2, df3가 모두 같은 인덱스 번호 [0, 1, 2]를 갖고 있었으므로 위처럼 만들어진다.
# 인덱스 번호 초기화
pd.concat([df1, df2, df3], ignore_index = True)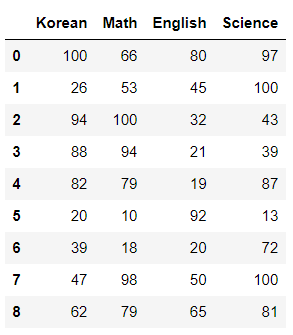
ignore_index = True를 사용하면 인덱스 번호가 전부 초기화되어, 0부터 순서대로 값이 매겨진다.
참고로 col-bind로 붙여진 경우에도 인덱스 번호 초기화가 가능하다.
# 참고로, col-bind로 붙여졌을 때도 인덱스 번호를 초기화할 수 있다
pd.concat([df1, df2, df3], axis = 1, ignore_index = True)
axis = 1이면 col-bind로 붙여지므로 이 때의 인덱스는 컬럼(열) 이다. 그러므로 열 이름이 0부터 순서대로 값이 매겨진다.
# 디폴트는 outer join으로 겹치는 값 상관없이 모두 join함.
# 겹치는 값만 뽑아보면 -> 열 이름이 같으므로 전부 뽑힌다!!
pd.concat([df1, df2, df3], join = 'inner')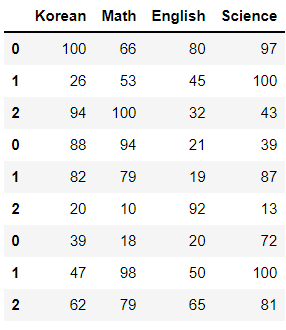
다음으로 pd.concat의 디폴트는 'outer join'(합집합) 이다.
그래서 인덱스 값이나 컬럼 값이 꼭 겹치지 않아도 모든 데이터를 붙여서 반환한다.
이 데이터에서는 axis = 0에서 컬럼값이 모두 동일하므로 inner join을 쓰나 outer join을 쓰나 값이 똑같다.
만일 outer와 inner join의 차이를 보고 싶다면 열 이름을 중복이 있는것과 없는 것으로 바꿔 조인을 해보자.
# (위에 이어서) 열 이름을 중복이 있는것과 없는걸로 바꿔서 조인해보자
df1.columns = ['A', 'B', 'C', 'D']
df2.columns = ['A', 'E', 'F', 'D']
pd.concat([df1, df2], join = 'inner')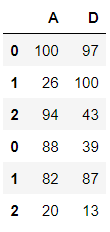
이와 같이 inner join 시에는 공통열인 'A'열, 'D'열만 출력되지만,
# 디폴트
## 이렇게 공통열이 아닌 부분은 NaN이 뜬다
pd.concat([df1, df2], join = 'outer')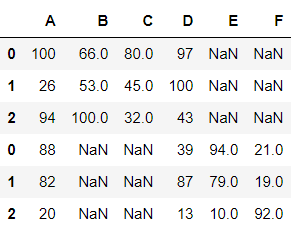
outer join(디폴트) 시 공통열이 아니더라도 전부 값을 조인해 준다. 겹치지 않는 부분은 NaN으로 표시한다.
마찬가지로 인덱스 값이 모두 다른 경우 axis = 1로 조인하면 inner join 시 인덱스번호가 같은 것끼리만 조인하고,
outer join 시에는 인덱스번호가 달라도 NaN으로 표시되어 조인될 것이다! (코드가 길어 주피터 노트북에만 첨부해두었다)
pd.concat의 또다른 기능
concat을 활용하면 인덱싱을 할 때 유용하다.
new_df = pd.concat([df1, df2, df3])
new_df
df1, df2, df3를 묶어 새로운 데이터프레임 'new_df'를 만들었다.
여기서 loc와 iloc 중 무엇으로 인덱싱하느냐에 따라 결과가 달라진다.
# 행 값이 1인 것만 추출 (인덱스가 1인 값 모두)
new_df.loc[1,]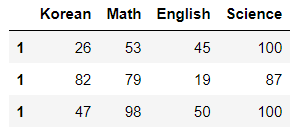
# 이번에는 딱 1행만 추출
new_df.iloc[1, ]
깜빡하고 학생 1명의 성적을 누락한 것을 발견해, 이를 new_df에 넣어주려고 한다.
이렇게 1개 단위의 데이터에 대해서는 데이터프레임 형태로 concat을 시켜줘도 되지만 append를 해주어도 된다. 또한, 딕셔너리 형태로 append하는 것도 가능하다!
## 컬럼이 여러개이면 Series가 아닌 Dataframe이므로 바꿔준다
df4 = pd.DataFrame([[47, 92, 88, 76]], columns = ['Korean', 'Math', 'English', 'Science'])
pd.concat([new_df, df4])
여기서 주의할 점은 df4의 값을 쓸 때 꼭 컬럼값을 넣어줘야 한다는 것이다.
앞에서도 봤지만, concat의 디폴트는 axis = 0으로 묶으므로 열 이름이 같은 애들끼리만 묶어주기 때문이다.
new_df.append(df4)
혹은, df4처럼 행 길이가 1개인 단순한 데이터는 append를 사용해도 같은 결과가 나온다.
이번에는 딕셔너리 형태로 만들어보자. 딕셔너리로 append를 해도 된다.
dict4 = dict({'Korean': 47, 'Math': 92, 'English': 88, 'Science': 76})
new_df.append(dict4)
그러나 이 경우엔 TypeError가 뜨는데, TypeError: Can only append a dict if ignore_index=True 라고 나온다.
원래의 데이터프레임에 딕셔너리로 append하는 경우엔 ignore_index를 꼭 써주어야 한다.
# 하지만, 딕셔너리 형태로 append하는 경우엔 ignore_index=True를 꼭 써주어야 한다!
new_df.append(dict4, ignore_index = True)
이렇게 하면 에러 없이 잘 나온다 :)
2. pd.merge
# df1, df2의 열 이름이 모두 동일한 경우
pd.merge(df1, df2, on = '공통열', how = 'inner')
# df1, df2의 열이 의미하는 것은 같은데 이름이 다른 경우
df1.merge(df2, left_on = 'df1의 공통컬럼명', right_on = 'df2의 공통컬럼명', how = 'inner')
- how = 'inner'가 디폴트지만, how에 left, right, inner, outer를 써줄 수 있다.(각각 왼쪽 테이블 기준 조인, 오른쪽 테이블 기준 조인, 교집합, 합집합)
- 데이터프레임이 2개인 경우만 조인할 수 있다.
- merge는 "특정 공통열"을 기준으로, 나머지 열까지 조인하고 싶을 때 편리하다!
이번에는 데이터를 다운받아 사용한다. (데이터는 깃허브에서 다운로드)
# 여기서는 데이터를 다운받아 사용한다 (데이터는 깃허브에 있다)
person = pd.read_csv('survey_person.csv') #관측한 사람의 이름
site = pd.read_csv('survey_site.csv') #관측한 위치
survey = pd.read_csv('survey_survey.csv') #날씨 정보
visited = pd.read_csv('survey_visited.csv') #관측한 날짜
display(person.head(3), site, survey.head(3), visited.head(3))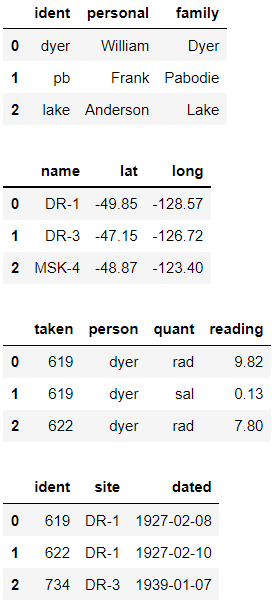
Q1. person과 survey를 연결하자.
두 데이터가 공통으로 갖고 있는 열은 이름이 서로 다르다. person 데이터에선 'ident'인데, survey 데이터에선 이 열이 'person' 이라는 이름이다. 두 열은 같은 기능이지만, 이름만 다르다.
이렇게 하나의 공통열을 기준으로 나머지 열도 조인하고 싶을 때 pd.merge를 사용하자!
#디폴트
person.merge(survey, left_on = 'ident', right_on = 'person')
조인된 결과를 보니, ident 열과 person 열의 데이터가 완전히 같다. 디폴트가 inner join(교집합)이기 때문이다.
그런데, person 데이터에선 없는 내용이 survey 데이터에선 있으면 어떻게 할까?
아님 survey 데이터에선 없는 내용이 person 데이터에서 있으면 어떻게 할까?
이럴 경우, 사용할 수 있는 옵션이 how = 'outer'(합집합)이다.
# 합집합
person.merge(survey, left_on = 'ident', right_on = 'person', how = 'outer')
outer join을 시키니 새로운 19번~21번 행이 생겼다.
- 19번 행: survey 데이터 값이 NaN이다.
- 즉 person 데이터에선 있는데 survey 데이터에선 없는 값이다.
- 20, 21번 행: person 데이터 값이 NaN이다.
- 즉 survey 데이터에선 있는데 person 데이터에선 없는 값이다.
이렇게 디폴트로는 두 데이터 모두에 공통적으로 있는 값만 추출하지만, outer join 옵션을 사용하면 꼭 공통된 게 아니더라도 값이 뽑힌다!
만약, 기준이 되는 데이터를 'person'으로 하고자 할 때, 즉 person 데이터 값은 전부 나오고 싶고, 얘랑 겹치는 survey 값만 뽑고 싶다면 어떻게 해야 할까? 바로 how = 'left' 옵션을 사용해보자.
# left join
person.merge(survey, left_on = 'ident', right_on = 'person', how = 'left')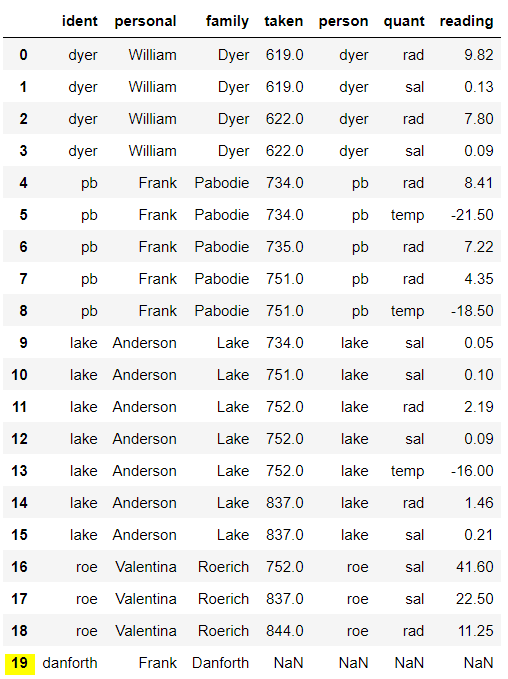
이렇게 19번 행만 살아남은 것을 볼 수 있다.
반대로 survey 데이터를 기준으로 조인하고 싶다면? how = 'right' 옵션을 쓰면 될 것이다.
(글이 길어지는 관계로 이 경우는 주피터 노트북에 적어 두었습니다!)
Q2. ps와 vs 데이터셋을 연결하자.
공통열의 개수가 꼭 하나가 아니어도 된다. 이번처럼 여러 개의 공통열인 경우에도 사용할 수 있다.
ps와 vs 데이터셋은 내가 임의로 만들었으며 이렇게 생겼다.
ps = person.merge(survey, left_on = 'ident', right_on = 'person')
# ps의 중복되는 열 삭제
del ps['person']
vs = visited.merge(survey, left_on = 'ident', right_on = 'taken')
# vs의 중복되는 열 삭제
del vs['taken']
display(ps.head(3), vs.head(3))
여기서 ps와 vs의 공통열들은 각자 다른 열 이름을 가지고 있다.
ps의 'ident'는 - vs의 'person'과 연결되는 식이다. 이렇게 공통열들을 찾아서 묶어보면..
ps.merge(vs, left_on = ['ident', 'taken', 'quant', 'reading'],
right_on = ['person', 'ident', 'quant', 'reading'])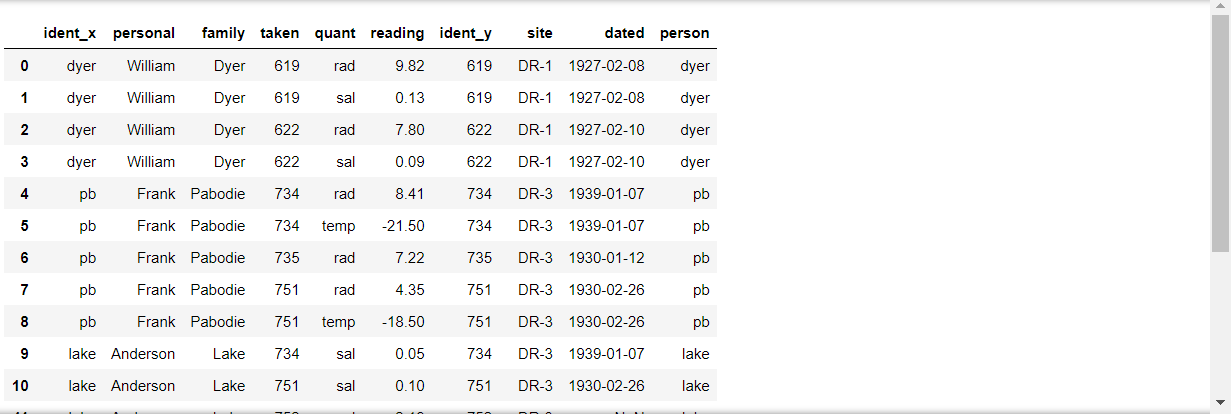
이렇게 공통열끼리 잘 묶여 데이터가 만들어진 것을 확인할 수 있다.
참고로, 새롭게 만들어진 데이터를 보면 서로 다른 열이지만 열 이름이 같은 'ident'는 파이썬에선 뒤에 x, y가 자동으로 붙어 만들어진다.
이렇게 하여 대표적인 판다스의 데이터 조인 기능 pd.concat, pd.merge에 대해 알아보았다!
각각 데이터를 합집합할 때, 데이터를 교집합할 때 유용하게 쓰이니 꼭 기억해두자 :)
'Skillset > Python' 카테고리의 다른 글
| [pandas] 결측치가 특정 개수, 특정 비율 이상인 열 drop하는 방법 (0) | 2022.06.22 |
|---|---|
| [pandas] 결측치 다루기 - 결측치 확인, 결측치 처리(NaN drop, interpolate) (0) | 2022.06.21 |
| python 열의 문자열을 분리해 N개 열로 만드는 방법(str, split, get) (2) | 2022.06.17 |
| [pandas] pd.melt, pd.pivot_table을 활용해 데이터프레임 가공하기 (2) | 2022.06.17 |
| [시각화] 파이썬 EDA에 꼭 필요한 시각화 그래프 (3) plt.subplots 사용하기 (0) | 2022.06.16 |



