
Yours Ever, Data Chronicles
[pandas] Series & DataFrame에서 자주 사용하는 유용한 메서드 (2) 본문
저번 포스팅에 이어, 파이썬 판다스의 Series(시리즈)와 DataFrame(데이터프레임)을 사용할 때, 자주 사용하는 유용한 메서드들을 정리하였다.
포스팅에서 사용한 코드는 이 깃허브에서 다운로드하시면 됩니다 :)
✔Table of Contents
2. 시리즈 & 데이터프레임 다루기 (공통 기능)
2-1. 인덱싱(Indexing)
저번 포스팅에서 만들었던 math_df를 활용한다.
math_df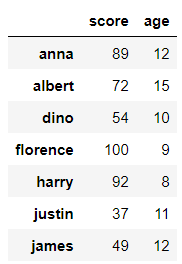
시리즈는 데이터프레임의 한 열만 떼어내면 된다고 했었다. 예시로 score 열을 떼어 오겠다.
# math_df에서 'score' 열만 떼면 -> 그것이 시리즈!
a = math_df['score']
a
# 시리즈의 인덱싱
시리즈에서는 index와 values 메서드를 제공한다. 두 메서드를 활용하면 인덱스와 그에 매칭되는 값이 리스트 형태로 뽑힌다.
# 인덱스 : 리스트 형태
print(a.index)
# 인덱스에 매칭되는 값: 리스트 형태
print(a.values)
이렇게 뽑힌 값은 모두 리스트이므로, 리스트 인덱싱도 가능하다.
a.index[5]
# 데이터프레임 인덱싱
데이터프레임의 경우에는 이전에 포스팅한 2차원 인덱싱과 동일하므로 간단하게만 소개하고 넘어가기로 한다.
math_df를 활용하여, 학생 이름이 harry와 dino의 성적을 뽑아보면?
## harry와 dino의 score
math_df.loc[['harry', 'dino'], 'score']
이번엔 학생 florence를 포함한 그 다음 순서 학생 모두의 성적과 나이는?
# florence를 포함한 그 다음 순서 학생들의 score, age
math_df.iloc[3:, :]
2-2. 기초통계량 추출하기
이번에는 기초통계량을 추출하는 방법을 알아보자. 여기서 사용하는 메서드는 바로 describe와 agg 함수이다.
- describe: 기본적인 통계량 (평균, 중위수, 최대, 최솟값 등)
- agg 함수: aggregation 함수, 즉 집계함수를 의미하며 평균, 중위수, 합계 등이 있다.
시리즈와 데이터프레임 바로 뒤에 이 메서드를 붙여 사용할 수 있다.
# 시리즈에 적용해보기
a
바로 뒤에 describe를 붙여 기초통계량을 뽑아보면
# score의 통계량 값을 뽑을 수 있음
a.describe()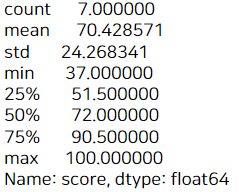
그리고 이렇게 agg 함수도 사용 가능하다!
# score의 평균값
a.mean()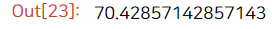
# 데이터프레임에 적용해보기
사실 이런 기초통계량은 데이터프레임에서 훨씬 더 자주 사용한다. 앞에서 만든 math_df를 활용하여 뽑아보면
math_df.describe()
이렇게 2개 열에 대한 기초통계량을 뽑아준다.
데이터프레임 자체에 agg 함수를 적용할 수도 있고, 또는 데이터프레임의 특정 열에만 agg 함수를 적용할 수도 있다.
# df 뒤에 바로 agg 함수 적용 - 각 열별 평균값
math_df.mean()
# 특정 컬럼만 떼서 볼수도 있다
math_df['age'].std()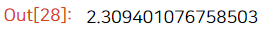
2-3. 불린 인덱싱(Boolean Indexing)
※ 불린 인덱싱이란?
참/거짓(True/False) 형태로 리스트에 담아, 시리즈나 데이터프레임에 전달하면 참만 뽑히게 하는 기법이다.
# 시리즈의 불린 인덱싱
앞에서 만든 시리즈 a를 다시 가져오자.
# 앞에서 만든 학생들의 score 값
a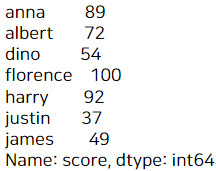
예를 들어, 성적이 50점 이상인 학생 이름과 성적만 뽑으려면 어떻게 해야 할까?
이럴 때 사용할 수 있는 것이 바로 불린 인덱싱이다.
먼저 성적이 50 이상이면 True, 아니면 False가 나오는 불(Bool) 형태를 만들어본다면 다음과 같다.
[a>=50]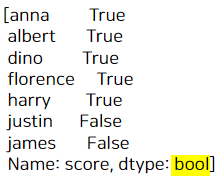
이렇게 50이 넘으면 True, 아니면 False가 뽑혔다.
이 상태를 리스트에 담아서 시리즈에 전달하면 True인 시리즈만 나온다.
a[a>=50] #True인 것만 뽑힘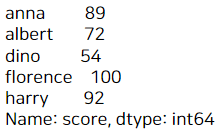
마찬가지로, 이번엔 평균 성적 이상인 성적값만 뽑으려면? 역시 불린 인덱싱을 활용하면 된다.
a[a>=a.mean()]
# 데이터프레임의 불린 인덱싱
math_df
데이터프레임 역시 마찬가지다. T/F 값을 갖는 bool 값을 리스트에 담아 데이터프레임에 전달해주기만 하면 된다.
이번엔 math_df의 나이(age)가 나이의 중간값 이하인 것만 뽑아보자. 먼저 T/F 형태로 나타낸다면
#math_df의 age가 age의 중간값 이하만 뽑기
math_df['age'] <= math_df['age'].median()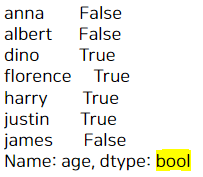
위의 코드를 그대로 리스트에 담아 전달하면 끝!
math_df[math_df['age'] <= math_df['age'].median()]
참고로 위처럼 loc나 iloc는 안 써도 되지만, 엄밀히 말해서 이 또한 인덱싱이므로 써도 같은 결과이다.
math_df.loc[math_df['age'] <= math_df['age'].median()]2-4. isin
Series or DataFrame.isin([궁금한 값 리스트])
시리즈나 데이터프레임에 '이 값'이 있는지가 궁금할 때 사용한다.
검사하고자 하는 값의 리스트를 isin에 담아 전달하면, 값이 있는 경우는 True, 없는 경우는 False를 반환한다. → 그러니 불린 인덱싱도 가능하겠지?
※ 반드시 궁금한 값은 리스트 형태여야 한다!
# 시리즈에 적용하기
a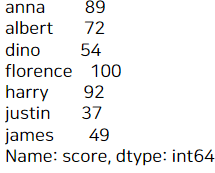
앞서 봤듯 a의 값은 학생들의 성적 데이터이다.
바로 이 성적 중에서 100점인 학생이 있는지 궁금할 때 isin을 사용하면 좋다.
# 성적(score)이 100점인 학생이 있는지 궁금하다.
a.isin([100])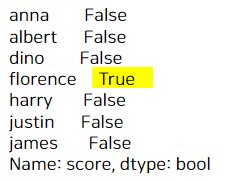
있는 경우엔 이렇게 True, 아니면 False가 나온다.
이를 활용해 불린 인덱싱을 해보면 어떤 값에 누가 해당하는지를 알 수 있다.
a[a.isin([100])] #100점 맞은 학생은 florence구나!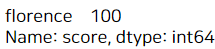
# 데이터프레임에 적용하기
math_df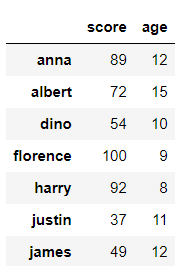
데이터프레임은 열이 여러 개가 존재하므로, 그냥 데이터프레임 자체에 대해 isin을 사용하면 모든 열에 대해 검사하게 된다.
# 데이터프레임은 열이 여러개이므로, 꼭 하나의 열만 검사하진 않는다.
math_df.isin([92, 95, 100, 9, 8])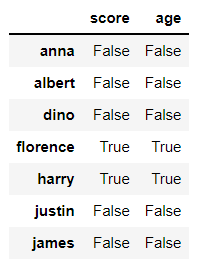
위처럼 score, age 열 둘 다에서 값이 있는지를 검사한다.
이게 싫은 경우엔 열을 지정해주자!
math_df['age'].isin([9, 8])
# 당연히 불린 인덱싱도 가능!!
math_df.loc[math_df['age'].isin([9, 8])]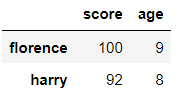
※ 참고로, 데이터프레임에 대해 불린 인덱싱을 하려면 위처럼 한 열에 대해 궁금한 값이 있는지를 검사해야 한다.
math_df.loc[math_df.isin([9, 8])] 이렇게 코드를 쓰게 되면 에러가 난다.
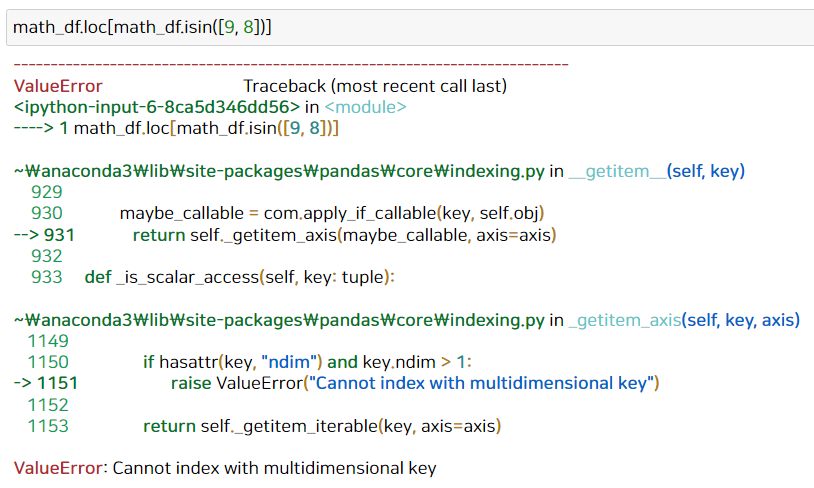
ValueError: Cannot index with multidimensional key 라는 에러가 나는데, 그 이유는
불린 인덱싱을 하는 대괄호 [ ] 안의 부분은 T/F 값, 시리즈 형태여야 하므로 전체 데이터프레임을 넣을 수 없기 때문이다.
2-5. 중복 제거하기(drop_duplicates)
# 시리즈 또는 데이터프레임에서 중복되는 값이 있는지를 검사(중복되면 True, 아니면 False)
Series or DataFrame.duplicated(keep = 'first/last/False')
# 시리즈 또는 데이터프레임에서 중복되는 값을 제거한 형태로 반환
Series or DataFrame.drop_duplicates([기준 컬럼], keep = 'first/last/False')
중복을 제거하는 drop_duplicates 메서드는 실제 데이터 분석을 시작할 때, 초반에 데이터 점검 용도로 정말 자주 사용하는 메서드이다.
- duplicated: 중복되는 값이 있는지 없는지를 검사하여 True/False 형태로 반환한다.
- keep 옵션은 중복된 값들 중 어떤 것을 중복으로 처리하는지를 의미한다. 예를 들어, 1번 행과 3번 행이 중복이라면
- first의 경우: 3번 행이 중복 (디폴트)
- last의 경우: 1번 행이 중복
- False의 경우: 1,3번 행 모두 중복
- keep 옵션은 중복된 값들 중 어떤 것을 중복으로 처리하는지를 의미한다. 예를 들어, 1번 행과 3번 행이 중복이라면
- drop_duplicated: 아예 중복값을 제거한 후 반환한다.
- keep 옵션은 위와 동일한 기능
- 인덱스가 리셋되지 않고 그냥 반환된다. 인덱스 값을 순서대로 리셋시키고 싶다면, ignore_index = True 옵션을 쓰거나 만들어진 데이터프레임에 reset_index를 적용하면 된다.
여기서는 중복을 제거해야 하므로 데이터 수가 많이 필요해서, 새로운 데이터를 불러와서 사용했다.
seaborn에서 기본 제공하고 있는 exercise 데이터이다.
# 이를 위해 새로운 데이터를 불러오자
import seaborn as sns
df = sns.load_dataset('exercise')
# 1열 제거
df = df.iloc[:, 1:]
df.head()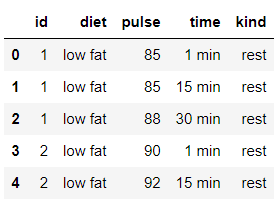
# duplicated(): 중복을 확인하기
먼저 전체 df에 대해 중복되는 값이 있는지를 확인해보자. (값이 완전히 동일한 행이 있어야만 True)
# 전체 df에 대해 중복 확인-> 값이 완전히 같은 행이 있어야만 True임
df.duplicated()
그런데 이렇게 나오게 되면 저 사이 생략된 부분에 True가 있는지 잘 모른다. 이럴 때는 뒤에 sum을 붙이면 True의 개수를 셀 수 있다!
df.duplicated().sum()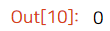
다행히 전체 행이 완전히 똑같은 데이터는 없다. 이번엔 특정 컬럼 'diet'에 대해 중복을 확인해보자.
df['diet'].duplicated().sum()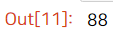
특정 열은 2개 이상 쓸 수도 있다.
## 열은 2개 이상 쓸 수도 있음
df[['diet', 'pulse']].duplicated().sum()
diet와 pulse의 값이 동일한 행은 34개가 있다.
# drop_duplicates(): 실제로 중복인 데이터를 제거한 후 반환
앞에서 duplicated()로 중복 데이터를 검사했다. 이번엔 실제로 중복인 값이 있다면 제거를 해보자.
예시로, df의 id는 중복되는 값이 많다. 그래서 id 값이 겹칠 때, 맨 마지막 것만 남기고 제거를 해보자.
df2 = df.drop_duplicates(['id'], keep = 'last')
print(df2.shape)
display(df2.head())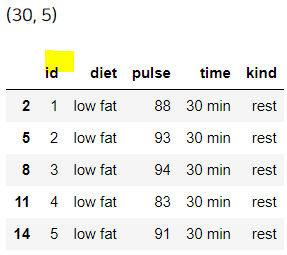
원래 keep = 'first'가 디폴트지만, 맨 마지막 것만 남긴다 하였으므로 last로 바꿨다.
원래 데이터 수는 90개였으나 지금은 데이터가 30개로 많이 줄었다.
이번에는 df의 id, pulse열의 값이 완전히 겹치는 게 있다면 첫 번째 값만 남기고 제거해보자.
df3 = df.drop_duplicates(['id', 'pulse'], keep = 'first')
print(df3.shape)
display(df3.head())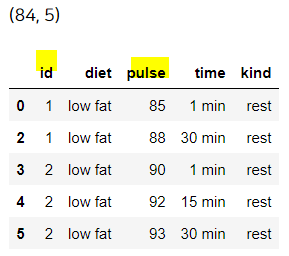
keep = 'first'가 디폴트이므로 이 옵션은 안 써도 결과는 동일하다.
원래 90개의 데이터에서 중복이 제거되어 84개만 남았다.
그런데 뭔가 이상한 점을 발견했는가? 바로 인덱스이다.
인덱스 값이 원래는 0부터 1씩 차례대로 부여되어 있었는데, 중간에 데이터가 삭제되면서 순서가 사라져버렸다.
중복을 제거한 후 인덱스까지 리셋해주려면 ignore_index 옵션을 사용하자.
## 인덱스는 리셋되지 않음 -> 인덱스까지 리셋하고 싶다면 ignore_index를 써주자
df.drop_duplicates(['id', 'pulse'], keep = 'first', ignore_index = True)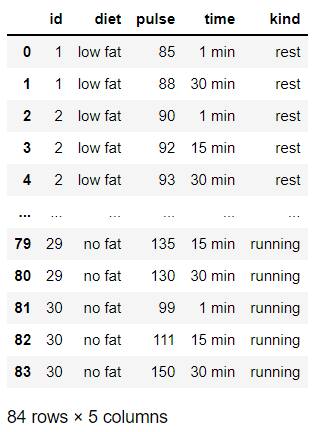
시리즈에 대해서도 똑같이 적용이 가능하다. 글이 길어지는 관계로 이건 코드에서 확인해보세용 :)
2-6. 값 정렬하기(sort)
이번 포스팅의 마지막 메서드이다.
값 정렬은 인덱스를 정렬할 수도 있고, 특정 열의 값을 정렬할 수 있다.
그리고 이 정렬하는 것은 숫자값일 때 사용하며, 오름차순(ascending = True)이 디폴트이다.
- 인덱스 정렬: Series or DataFrame.sort_index(ascending = True)
- 값 정렬: Series or DataFrame.sort_values(by = '기준 컬럼', ascending = True)
예전에 만들어두었던 math_df를 가져온다.
math_df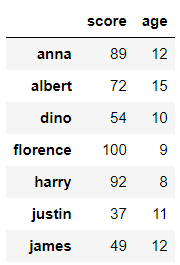
인덱스 값을 숫자로 바꿔주기 위해 수정한다.
# df의 인덱스 수정
math_df.index = [5, 7, 2, 10, 1, 0, 9]
math_df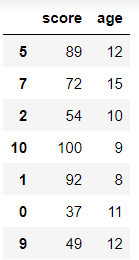
# 인덱스 정렬: sort_index()
먼저 인덱스를 숫자값이 작은 순서대로 정렬해보자. 오름차순이 디폴트이므로 그대로 sort_index를 적용
# 인덱스 정렬
math_df.sort_index()
# 값 정렬: sort_values()
이 경우를 실무에서는 훨씬 많이 쓴다. age 값이 작은 순서대로 정렬해보자.
# age 값에 따라 정렬
math_df.sort_values(by = 'age')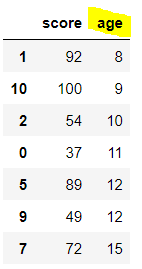
이번엔 반대로 age 값이 큰 순서대로 정렬해보자.
# age가 큰 순서대로 정렬
math_df.sort_values(by= 'age', ascending = False)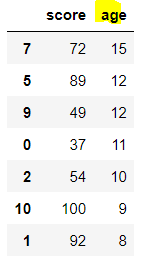
시리즈에서도 이와 마찬가지로 인덱스 및 값 정렬이 가능하다.
이렇게 하여 시리즈와 데이터프레임에 자주 사용되는 메서드 6가지를 정리해보았다.
데이터 분석은 전처리를 하는 데에만 프로젝트 시간의 반 이상을 쓴다는 말을 들어보았을 것이다. 판다스는 그 중에서도 전처리를 하는 데 아주 큰 도움을 주는 라이브러리이다.
그러니 기본 판다스 구문을 잘 익힌다면 실무에서 데이터 분석을 잘 하는 데 큰 도움이 되리라 생각한다 :)
'Skillset > Python' 카테고리의 다른 글
| [시각화] 파이썬 그래프 위에 글자 쓰기 (ax.patches, ax.text) (0) | 2022.07.09 |
|---|---|
| python sample 함수 사용법과 예제 (0) | 2022.07.04 |
| [pandas] Series & DataFrame에서 자주 사용하는 유용한 메서드 (1) (0) | 2022.06.27 |
| 파이썬 데이터프레임 인덱싱하기 - python dataframe indexing, slicing (0) | 2022.06.23 |
| [pandas] 결측치가 특정 개수, 특정 비율 이상인 열 drop하는 방법 (0) | 2022.06.22 |



