
Yours Ever, Data Chronicles
통계학과 출신의 데이터 사이언스 커리어 관련 회고 및 방향 본문
이번 포스팅은 통계학과 출신으로서, 데이터에 관심을 갖게 된 계기와 데이터 직군을 준비하면서 고민했던 것들, 경험했던 것들 그리고 앞으로는 어떤 방향으로 나아갈지에 대한 내용을 담아보고자 합니다.
데이터 직군을 준비하시는 분들께 조금이나마 도움이 되었으면 하며, 저는 아직도 부족한 점이 많기에 참고용으로 봐주시면 좋을 것 같아요 :)
2018.
내가 데이터의 매력에 처음 빠져 버렸던 계기는 2018년으로 거슬러 올라간다.
당시 대학교 2학년이었던 나는 부동산학과에서 열렸던 GIS를 활용한 분석 수업을 들었는데, 기존에 사용하던 비효율적인 방법을 데이터를 활용하면 더 효율적이면서도 합리적으로 문제해결을 할 수 있다는 것에 신선함을 느꼈다.
그 때 '무인택배함이 위치할 가장 최적의 장소를 GIS를 활용해 도출하는 팀 프로젝트'를 했었는데, 이 수업을 듣지 못했더라면 단순히 주어진 예산 안에서 활용이 가능한 곳이나 사람들이 많이 다니는 곳이라고 생각했을 것이다.
하지만 실수요층을 감안하여 1인 가구 수, 유동인구 수, 지하철역 및 버스정류소 데이터로부터 사람들이 많이 이용할 만한 지역을 추출하였고 GIS 툴을 이용하여 아직 택배함이 설치되지 않았지만 수요자가 많을 곳을 선정해낼 수 있었다.
그 이후 나는 데이터 분석에 많은 관심이 생겼고 이 무렵 '데이터 분석의 힘(이토 고이치로 저)' 책을 읽으면서 기업의 마케팅 전략을 비롯한 다양한 분야에서 데이터를 활용해 문제를 해결할 수 있다는 것을 알게 되었다. (정말 강추하는 책이다.)
특히 '데이터를 그저 숫자로 바라보는 것이 아니라, 이를 해석하여 인사이트를 추출할 수 있다'는 점이 가장 흥미로웠다.
통계학과 수업은 이론 수업이 대다수라, 학교 수업만으로 데이터 분석을 공부하기 어렵다는 판단을 내리고 데이터 분석 프로젝트를 할 수 있는 곳을 찾았다. 그렇게 들어가게 된 곳이 Growth Hackers라는 빅데이터 학회였다.
2019.
학회 5기 멤버로 활동하며 정말 다양한 것을 배웠다. 교육 세션을 통해 데이터 사이언스 지식을 배울 수 있었고 무엇보다도 좋았던 것은 기업 연계 프로젝트였는데, 유저 데이터를 직접 만져보며 실무에서 하는 분석을 배웠다.
방학 때 쏘카(socar)에서 프로젝트 인턴을 하며 유저를 어떻게 나눠볼까 같이 고민하며 클러스터링도 해보고 EDA를 통해 패턴도 찾아보고, 특정 패턴의 수요를 바탕으로 할증을 하면 어떻게 될지 시뮬레이션을 해보았다. 짧은 프로젝트 기간이었지만 새로운 경험이었다. 프로젝트에서 사용한 코드 일부는 밑의 깃허브에서 확인할 수 있다.
GitHub - suy379/19_summer: user's pattern analysis of car-sharing company
user's pattern analysis of car-sharing company. Contribute to suy379/19_summer development by creating an account on GitHub.
github.com
또한 학기중에 있었던 IGAWorks와의 연계 프로젝트에서는 data-driven attribution model을 만들었는데, 너무 어려운 주제였지만 프로젝트를 하던 멤버들과 열심히 협력하며 구현했던 기억이 난다. 이 프로젝트를 통해 유저들이 여러 광고를 보고 결국 전환되었을 때 어떤 광고에 이익을 어떻게 배분할 것인가에 대한 새로운 지식을 또 하나 얻어갔다.
2019년은 나에게 많은 성장을 이루게 해주었지만 한편으로는 많이 지치기도 한 해였다. 학점에 학회 활동까지 챙겨야 했으니. (사실 여기 적진 않았지만 학기중에 추천알고리즘을 만드는 팀플도 했다. 이 프로젝트도 하고 기업 연계 프로젝트도 하느라, 잠도 못 잤던 기억이..)
2020.
2020년엔 코로나가 터져, 학교 수업도 비대면이라 본가에서 공부에 열중했다. 2019년에 프로젝트를 하며 데이터 분석을 더 잘 하려면 데이터 툴(tool)을 더 잘 다뤄야겠다는 생각을 했기 때문이었다. 'Jump to Python(이지스퍼블리싱)'을 복습했고 머신러닝 교재로는 '머신러닝 완벽 가이드(위키북스)', 그리고 딥러닝으론 '딥러닝 입문(이지스퍼블리싱)'을 공부했다. (이 책들은 데이터 사이언스를 공부할 수 있는 입문서로 정말 추천하는 책이다.)
그 때 학교에서 '데이터마이닝(Data-mining)'이라는 수업을 들었는데, 머신러닝과 관련한 지식을 수학적으로 접근하며 어렵기도 했지만 재밌었다. 1학기 때는 이론 위주였지만, 2학기 때는 팀플이라서 뉴스 기사 원문 텍스트 데이터에 머신러닝 모델을 적용해 가장 중요한 3가지 문장을 추출하는 프로젝트를 했다. 이것도 처음 도전하는 프로젝트인데다 텍스트 데이터를 돌리려면 보통 딥러닝 모델을 적용해야 하지만 컴퓨팅 리소스 자원의 한계로 머신러닝의 문제로 바꿔 Text Classification 모델을 적용했다. 영어 논문 3개를 읽어가며 열심히 프로젝트를 수행했었다.
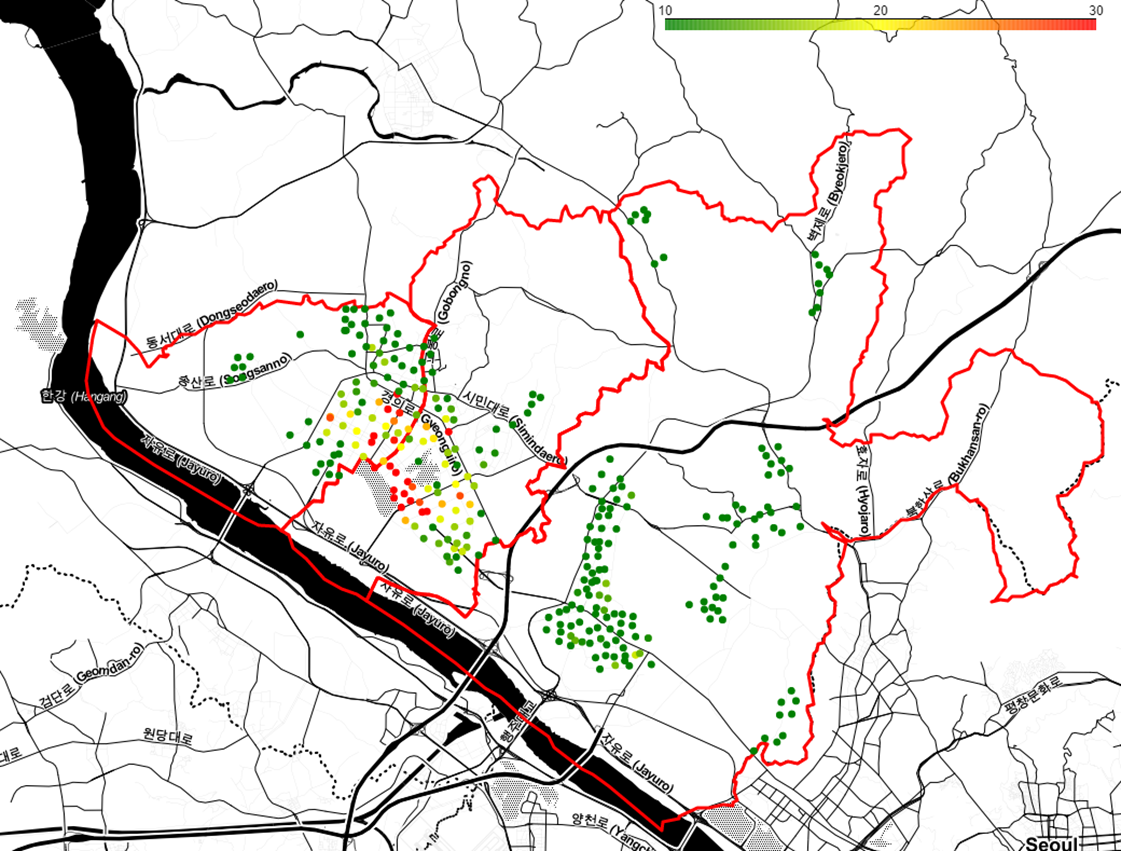
공부뿐 아니라 공모전에 도전한 첫 해이기도 했다. 여름방학에 COMPAS에서 주관하는 '고양시 자전거대여소 최적 위치 선정' 프로젝트를 했는데, EDA로 이용자들의 경로를 분석해보고 XGBRegressor 모델을 통해 데이터를 학습시켜 최적의 위치를 찾아냈다. 방학 동안 열심히 매달려 한 프로젝트였는데 감사하게도 장려상을 받을 수 있었다.
(밑의 깃허브 링크에서 사용한 코드와 분석 보고서를 확인할 수 있으니, 관심있으신 분은 참고하셔도 좋을 것 같다.)
GitHub - suy379/Goyang_fifteen: COMPAS Goyang City Bicycle Rental (Fifteen) Location Analysis (Encouragement Award)
COMPAS Goyang City Bicycle Rental (Fifteen) Location Analysis (Encouragement Award) - GitHub - suy379/Goyang_fifteen: COMPAS Goyang City Bicycle Rental (Fifteen) Location Analysis (Encouragement Aw...
github.com
2020년을 되돌아보면 정말 공부를 많이 한 해였던거 같다. 문제 해결을 위해 관련 논문을 찾고, 새로운 모델이나 분석 방법을 찾아 이를 주어진 데이터에 맞게 적용하는 데까지 시간도 오래 걸리고 힘들었지만 정말 뿌듯하고 즐거운 경험이었다.
2021.
2021년이 되고 나는 데이터 분석 인턴을 도전해 보기로 마음먹었다. 열심히 공부도 하고 프로젝트 경험도 쌓았지만, 늘 이런 프로젝트들은 '결과가 명확한' 프로젝트였기 때문이다. 어떤 것을 만들어야 하고 어떤 문제에 대한 답을 내야 하는지가 있었다. 하지만 데이터 업계에서 실무를 한다는 것은 정답이 없는 회사의 데이터를 다루어야 하니, 회사에서 인턴 경험을 꼭 쌓자는 생각이 있었다.
쇼핑을 즐겨 해서 그런지, 나는 커머스 업계에 관심이 많았다. 자주 이용하는 앱도 전부 올리브영, 에이블리, LF몰 등 이커머스였는데, 특히 나는 이 회사들이 만드는 프로모션에 관심이 많은 편이었다. (예를 들면 '더보기' 클릭)
관심있게 지켜본 프로모션이 하나 있다. 2021년 초 올리브영에선 '탑 리뷰어' 제도를 만들어 자체적으로 리뷰를 수집하기 시작했고 탑리뷰어들에겐 2주에 한번씩 신상품을 무료로 제공하고, 매주 2만원의 쿠폰을 뿌렸다. 나는 이걸 보고 '얘네 왜 이러지? 너무 손해 아닌가?' 라는 생각을 했다. TMI지만 내가 올리브영 탑리뷰어라서(ㅋㅋ) 이런 혜택을 많이 받았지만 올리브영에서 많이 구매를 하지는 않았기 때문이다.

하지만 2022년인 지금도 올리브영은 탑리뷰어 혜택을 유지하고 있다. 아마 탑리뷰어들이 대다수의 유저들과 다르게 쿠폰을 뿌린 것 이상으로 굉장한 매출을 올려주고 있다는 인사이트를 발견했기 때문이 아닐까?
이런 것들을 보면서, 커머스 업계에서 유저를 분석하고 싶다는 생각이 들었다. 프로모션의 효과를 높이기 위해선 어떤 것들이 필요할까? 신규 유저를 안착시키기 위해선 어떤 전략이 필요할까? 이 회사에선 이를 위해 어떤 방법을 쓰고 있을까? 너무도 궁금했다.
새 학기가 되고 인턴을 찾던 중, 내가 즐겨 쓰는 에이블리(ABLY)에서 데이터 분석 인턴을 모집한다는 공고를 보았고, 운좋게도 처음 써본 인턴 지원에 합격하여 빠르게 인턴 경험을 해볼 수 있었다.

회사에서 정식으로 인턴 업무를 한 것이 처음이라 실수도 잦았고 6개월 동안 힘든 적이 많았다. 빠르게 성장하는 스타트업이라 그런지 해야 할 일도 너무 많았고 파볼 데이터도 많았다.
에이블리에서 대시보드를 만드는 방법, 커머스업계에서 인사이트를 도출하는 데이터 분석 방법 등 여러 가지를 배웠지만, 가장 큰 수확은 "회사에 필요한 데이터 분석"을 하는 방법이었다. 나에게 많이 부족했던 점이기도 했고, 앞으로도 비즈니스적 마인드를 갖는 것은 배워나가야 할 점이다. 관련해서 느꼈던 바가 궁금하시다면 이전에 포스팅한 '초보 데이터 분석가가 느끼는 데이터 분석의 어려운 점' 을 참고하시면 좋을 듯하다. 그리고 인턴 생활을 하며 배웠던 점들도 추후 포스팅할 예정이다.

작년 10월 말 퇴사를 하고 나서 그동안 너무 달려왔던 나를 쉬게 하는 시간을 가졌다. 당시 번아웃도 살짝 온 상태였기에, 쉬면서 많은 책을 읽으며 '늘 바쁘게 살아야 한다'는 기존의 신념이 잘못된 거라는 생각을 많이 하게 되었다.
최근 중요하게 생각하는 것 중 하나는 '바쁘게 뭔가를 많이 하면서 사는 것' 보다는 '올바른 방향으로 여유롭게 사는 것'이다.
방향만 제대로 설정한다면 여유롭게 살더라도 역시 성장할 수 있다는 것을 최근에서야 깨닫고 있다.
마치며.
지금까지의 경험을 통해, 소위 '데이터 분석'이라 불리는 '데이터 사이언스(Data Science)' 분야가 정말 넓은 분야라는 것을 몸소 느꼈다. 데이터 추출-분석-예측-(때로는 배포)에 이르기까지의 넓은 분야이며, 이는 데이터를 추출해 이를 핸들링하고 분석을 통해 인사이트를 도출하는 Analyze의 영역과 모델링을 통해 다음에 발생할 것을 예측하고 알고리즘을 구현하는 Engineering의 영역을 모두 합친 것이 '데이터 사이언스'라는 것을 알았다.
그렇기에, 데이터 사이언스의 영역 모두를 알고 잘할 필요는 없다. (다 갖추고 있는 사람이 거의 없다.)
또한 나는 그래서 더욱 데이터 분석을 경험해보라고 조언하고 싶은데, 될 수 있다면 동아리(학회)든, 공모전이든, 인턴이든 뭐든지 해봤으면 좋겠다. 데이터 사이언스의 어떤 영역에서 자신이 강점을 갖고 있는지, 흥미를 느끼는지는 경험해보지 않으면 모르는 영역이기 때문이다.
나는 앞선 경험을 통해, 나는 다음과 같은 일에 흥미와 강점이 있음을 알게 되었다.
- 데이터 핸들링을 통해 현황을 파악하는 것
- 현재 처한 비즈니스 문제를 해결하는 것 (인사이트 도출 또는 알고리즘 구현을 통해)
- 리소스가 많이 드는 비효율적인 과정을 자동화(알고리즘화)하는 것
- 새로운 기술이나 툴을 빠르게 익히는 것
그래서 앞으로는 나의 이러한 흥미를 충족시킬 수 있는 일이면서도 지금까지 내가 못해본 경험을 할 수 있는 회사와 직무를 준비하려고 한다.
특히 그저 분석만 하는 게 아닌, 실험 설계를 통해 공격적으로 문제를 개선해나가고 싶고 알고리즘 구현을 통해 비즈니스 문제를 해결하고 싶다. 나는 약간 연구원(?) 스타일이라, 논문을 읽고 기존의 모델을 보완해 새로운 모델을 구현해보는 것이 목표이다. 작년엔 Analyst에 가까운 일을 했다면, 이번엔 Scientist에 가까운 일을 하고 싶다.
무척이나 긴 글이었는데, 끝까지 읽어주신 분이 있다면 정말 감사드린다. 이 글을 쓰면서 나 자신도 데이터 분석의 어떤 과정에 흥미를 느끼고 강점이 있는지를 잘 알게 된 것 같다. 나처럼 데이터 직군을 준비하는 분들이 있다면, 지금까지의 자신의 경험을 글로 직접 써보면서 어떤 포지션이 적합할지를 생각해보면 어떨까 싶다 :)
'Data Science > My Career Story' 카테고리의 다른 글
| [커리어 시리즈 #2] 데이터 분석가/인턴 서류에 합격하려면? (feat. 포트폴리오, 자소서, 이력서) (6) | 2023.07.02 |
|---|---|
| [커리어 시리즈 #1] 데이터 분석가/데이터 분석 인턴 지원 시작하기 (2) | 2023.06.29 |
| Yours ever, Welcome to Everly's Blog! (3) | 2023.06.27 |
| 데이터 분석 인턴은 어떤 일을 할까? (커머스, 스타트업 인턴 후기) (12) | 2022.05.25 |
| 초보 데이터 분석가가 느끼는 데이터 분석의 어려운 점에 대한 고찰 (24) | 2022.01.25 |



