
목록판다스 (6)
Yours Ever, Data Chronicles
 [pandas] 순서가 있는 범주형 데이터에 순서 지정하기 - CategoricalDtype
[pandas] 순서가 있는 범주형 데이터에 순서 지정하기 - CategoricalDtype
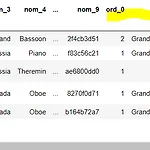
이전에 쓴 시각화 포스팅의 첫머리에서 데이터의 종류에 대해 설명하였다. 그 때 데이터는 사칙연산이 가능한 '수치형 데이터'(numerical data)와 '범주형 데이터'(categorical data)로 나눌 수 있으며, 범주형 데이터 중에서 순서(순위)가 있는 데이터를 순서형 데이터(ordinal data)라고 하였다. 이런 순서형 데이터가 있는 데이터를 받은 경우, 순위를 꼭 지켜줘야 한다. 그 이유는 순서형 데이터는 순위대로 중요도가 달라지기 때문이다. 대표적인 순서형 데이터인 '학점'의 경우 A+이라는 값과 F 라는 값은 큰 차이가 있듯이! 하지만 데이터셋에 순위가 지정되어 있지 않은 경우가 많다. 이럴 때 판다스의 CategoricalDtype 함수를 사용하면 내가 순위를 지정한 대로 순서가 ..
 [pandas] 범주형 데이터 2개를 비교하는 교차분석표(crosstab, 크로스탭) 알아보기
[pandas] 범주형 데이터 2개를 비교하는 교차분석표(crosstab, 크로스탭) 알아보기
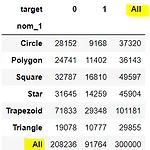
파이썬 판다스(pandas)에서 범주형 데이터 2개를 비교분석할 때 유용한 표, 교차분석표(crosstab)에 대해 알아보자. 이러한 교차분석표는 각 범주형 데이터의 개수를 행과 열로 cross해놓은 표를 의미한다. 다음은 pandas crosstab 공식 문서를 참고하였다. pd.crosstab(index, columns, values=None, rownames=None, colnames=None, aggfunc=None, margins=False, margins_name='All', dropna=True, normalize=False) 필수 input index: 행으로 그룹화할 값 (array, series, list) columns: 열로 그룹화할 값 (array, series, list) Opt..
 [pandas] Series & DataFrame에서 자주 사용하는 유용한 메서드 (2)
[pandas] Series & DataFrame에서 자주 사용하는 유용한 메서드 (2)
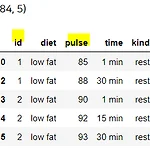
저번 포스팅에 이어, 파이썬 판다스의 Series(시리즈)와 DataFrame(데이터프레임)을 사용할 때, 자주 사용하는 유용한 메서드들을 정리하였다. 포스팅에서 사용한 코드는 이 깃허브에서 다운로드하시면 됩니다 :) ✔Table of Contents 2. 시리즈 & 데이터프레임 다루기 (공통 기능) 2-1. 인덱싱(Indexing) 저번 포스팅에서 만들었던 math_df를 활용한다. math_df 시리즈는 데이터프레임의 한 열만 떼어내면 된다고 했었다. 예시로 score 열을 떼어 오겠다. # math_df에서 'score' 열만 떼면 -> 그것이 시리즈! a = math_df['score'] a # 시리즈의 인덱싱 시리즈에서는 index와 values 메서드를 제공한다. 두 메서드를 활용하면 인덱스와..
 [pandas] 데이터 연결하기 - pd.concat, pd.merge 차이점 및 사용법
[pandas] 데이터 연결하기 - pd.concat, pd.merge 차이점 및 사용법
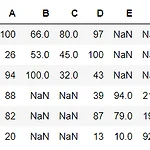
이번 포스팅에선 데이터를 연결하는 방법(즉, 데이터 조인(join)시키는 방법)에 대해 알아본다. 데이터 분석을 하다보면 여러 개의 데이터프레임을 연결해야 하는 경우가 많다. 깔끔한 데이터(Tidy Data)를 만들기 위해 꼭 알아둬야 하는 메서드이다. 이번 장에서는 판다스의 대표적인 data join 메서드 2가지인 concat과 merge에 대해 예제로 알아보자. (참고로 데이터셋과 주피터 노트북 파일은 이 깃허브를 참고하세요!) ✔Table of Contents 먼저 임의의 데이터 df1, df2, df3를 생성하였다. 이는 내가 임의로 만든 데이터로, 1반, 2반, 3반 학생들 3명의 시험 성적 데이터이다. import pandas as pd # df1: 1반 학생들(3명)의 시험 성적 a = [..
 python 열의 문자열을 분리해 N개 열로 만드는 방법(str, split, get)
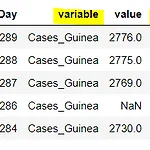
python 열의 문자열을 분리해 N개 열로 만드는 방법(str, split, get)
오늘은 python에서 문자열 데이터를 처리할 때의 꿀팁 중 하나인, 열 이름을 관리하는 방법에 대해 포스팅한다. 이 방법은 하나의 열에 여러 의미가 있는 경우, 이 열의 정보를 분리하여 새로운 N개 열로 만드는 방법이다. 예를 들어, 위와 같은 데이터가 있다고 하자. 이 데이터의 'variable' 열은 2가지 의미를 갖고 있는데, '_' 를 기준으로 왼쪽은 상태를, 오른쪽은 국가를 나타내고 있다. 그래서 'Cases_Guinea'라고 하면 'Cases'와 'Guinea' 이렇게 2개로 나누어 'status', 'country' 라는 열로 만들어주고자 한다. 이는 파이썬의 문자열 처리 메서드인 split와 get을 활용하면 바로 해결된다! 바로 알아보자. import pandas as pd ebola_..
 [pandas] pd.melt, pd.pivot_table을 활용해 데이터프레임 가공하기
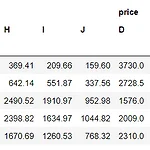
[pandas] pd.melt, pd.pivot_table을 활용해 데이터프레임 가공하기
오늘은 파이썬에서 데이터프레임(dataframe)을 가공하는 유용한 메서드인 pd.melt, pd.pivot_table에 대해 알아보자. 참고로 데이터셋&주피터 노트북 코드는 이 깃허브에 공유해두었습니다 :) GitHub - suy379/python_for_DA: Python for Data Analysis (데이터 분석을 위한 중요한 파이썬 모음) Python for Data Analysis (데이터 분석을 위한 중요한 파이썬 모음). Contribute to suy379/python_for_DA development by creating an account on GitHub. github.com ✔Table of Contents 1. pd.melt pd.melt(dataframe, id_vars, v..