
Yours Ever, Data Chronicles
파이썬 네트워크 시각화 분석하기(python networkx 예제) / 파이썬 데이터 분석 실무 테크닉 100 본문
파이썬 네트워크 시각화 분석하기(python networkx 예제) / 파이썬 데이터 분석 실무 테크닉 100
Everly. 2022. 4. 16. 19:33이번 포스팅에서는 python networkx 라이브러리를 활용해 네트워크를 가시화하는 방법을 알아보고, 실제 물류 데이터를 적용하여 효율적으로 운송이 이루어지고 있는지를 살펴봅니다.
최적화를 시각화하는 라이브러리는 다양하지만 여기서는 networkx를 사용합니다.
✔Table of Contents
Tech 53. 네트워크 가시화하기 (기초)
먼저 네트워크 시각화를 하기 위해선 다음이 필요합니다.
- 그래프 객체
- 노드(node) : 점
- 엣지(edge) : 점과 점을 연결하는 선
- 좌표 : 점의 좌표
위의 순서를 지켜, 가장 기본적인 네트워크를 만들어보겠습니다.
import networkx as nx
import matplotlib.pyplot as plt
#그래프 객체 설정
G = nx.Graph()
#노드 설정
G.add_node('nodeA')
G.add_node('nodeB')
G.add_node('nodeC')
#엣지 설정
G.add_edge('nodeA', 'nodeB')
G.add_edge('nodeA', 'nodeC')
G.add_edge('nodeB', 'nodeC')
#좌표 설정
pos = {}
pos['nodeA'] = (0,0)
pos['nodeB'] = (1,1)
pos['nodeC'] = (0,1)
#그리기
nx.draw(G, pos, with_labels= True)
plt.show()
코드는 간단합니다.
우선 그래프 객체 'G'를 설정하고 add_node를 사용해 노드(node)를 설정합니다. 여기선 노드를 nodeA, B, C 이렇게 3가지를 설정했습니다.
그리고 각 노드(점)을 잇는 엣지를 add_edge를 사용해 이어줍니다. 마지막으로 노드의 좌표를 설정해주면 됩니다. 좌표가 잘 이해가 되지 않는다면 다음 그림을 참고하세요:

우리가 고등학교 때 배웠던 좌표평면 위에 node A, B, C를 그렸다고 생각하면 됩니다.
Tech 54. 네트워크에 노드를 추가하기
이번엔 한 단계를 더 나아가보죠. 새로운 노드인 nodeD를 추가해봅니다. 이 노드는 nodeA하고만 연결이 되며, 좌표는 (1,0)으로 설정해보겠습니다. 코드는 어떻게 써야 할까요? 위에서 사용한 코드를 살짝만 변형합니다.
#앞서 만든 그림에 새로운 노드 nodeD(nodeA와 연결되는)를 추가한다.
#노드
G.add_node('nodeD')
#엣지
G.add_edge('nodeA', 'nodeD')
#좌표설정
pos['nodeD'] = (1,0)
#그리기
nx.draw(G, pos, with_labels = True)
노드-엣지-좌표 순으로 새로운 노드인 nodeD를 추가해주면 됩니다.
Tech 55. 경로에 가중치 부여하기
여기까지 우리가 기본적인 경로를 그려보았는데요. 하지만 우리가 마주하게 될 경로는 굉장히 복잡합니다. 이렇게 노드와 노드 간의 경로가 하나가 아닌 여러 개가 될 수도 있죠. 이렇게 많이 사용하는 경로와 적게 사용하는 경로는 어떻게 구분해서 그릴 수 있을까요?
바로 "가중치" 를 사용하면 됩니다. 가중치의 값이 커질수록, 노드 사이의 "엣지"의 굵기를 더 굵게 하면 됩니다.
가중치를 얻어오는 방법은 여러가지가 있지만, 여기선 csv 파일에 저장된 가중치 정보를 데이터프레임으로 읽어 와서 사용하겠습니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import networkx as nx
#데이터 불러오기
df_w = pd.read_csv('6장/network_weight.csv') #가중치
df_p = pd.read_csv('6장/network_pos.csv') #좌표
display(df_w, df_p)
이렇게 가중치 정보가 담긴 데이터 'df_w', 좌표 정보가 담긴 데이터 'df_p'를 불러왔습니다.
데이터를 보면 알겠지만, 노드는 node A~E까지 총 5개가 있네요. 그리고 각 노드 간 엣지의 굵기(가중치)가 df_w에 저장되어 있고, 노드의 좌표는 df_p를 사용하면 되겠네요!
우선 엣지 가중치를 리스트화해봅니다. 빈 리스트 edge_w를 만들고, 각 행, 열에 해당하는 가중치를 넣어줍니다. 예를 들어 노드A에 대해선 0번 인덱스에 해당하는 모든 열의 값을 가져오면 되겠죠?
그럼 노드A-A , 노드A-B, 노드A-C, 노드A-D, 노드A-E 를 연결하는 엣지의 가중치 값이 담길 것입니다. 코드로 만들어봅시다. (다만 가중치 값이 너무 작은 관계로 10을 곱한 값을 가중치로 사용합시다.)
size = 10
edge_w = []
for i in range(len(df_w)):
for j in range(len(df_w.columns)):
edge_w.append(df_w.iloc[i][j]*size)
edge_w
이제 이렇게 가중치를 리스트로 저장했습니다.
엣지에 가중치를 설정할 때와 아닐 때의 그래프의 차이가 어떻게 나타나는지를 확인하기 위해, 먼저 가중치가 없을 때의 그래프를 그려봅시다. 위의 df_w와 df_p를 활용해, 노드, 엣지, 좌표만 설정해봅니다.
#객체
G = nx.Graph()
#노드 5개 설정
for i in range(len(df_w.columns)):
G.add_node(df_w.columns[i])
#엣지 설정
for i in range(len(df_w.columns)):
for j in range(len(df_w.columns)):
G.add_edge(df_w.columns[i], df_w.columns[j])
#좌표 설정
pos = {}
for i in range(len(df_w.columns)):
node = df_w.columns[i]
pos[node] = (df_p[node][0], df_p[node][1]) #pos[노드] = (좌표) 임을 이용
#그리기
nx.draw(G, pos, with_labels=True)
plt.show()
모든 노드 간 엣지의 굵기가 똑같습니다. 그래서 어떤 노드들 간에 더 가중치값이 큰지를 전혀 알아볼 수가 없습니다.
이제 앞서 구한 가중치 리스트 edge_w 를 활용해 다시 그림을 그려봅시다. 엣지에 가중치를 추가하는 것은 width 옵션으로 지정하면 됩니다.
#엣지에 가중치 추가, 꾸미기
nx.draw(G, pos, with_labels=True,
font_size = 16, node_size = 1000, node_color= 'k', font_color = 'w', width = edge_w) #가중치는 width 옵션으로 지정
plt.show()
이렇게 가중치를 부여한 그림을 그리면, 어떤 경로가 더 부각되는지를 직관적으로 파악하기 쉽겠죠?
참고로 width 옵션 외에도 그림을 꾸미기 위한 다양한 옵션을 추가하였습니다. 노드와 폰트의 크기 및 색깔을 바꿨습니다.
Tech 56 - 57. 운송 경로 데이터를 불러오고 시각화하자.
이제는 어떻게 그리는지를 배웠으니, 물류 데이터를 직접 가져와서 networkx 라이브러리로 시각화를 해봅니다. 사용하는 데이터는 다음의 2가지입니다.
- trans_route.csv : 운송 경로 데이터. 창고(W) 에서 공장(F) 으로의 운송량이 기록됨 (df_tr)
- trans_route_pos.csv : 창고(W) 및 공장(F) 의 위치정보 (df_pos)
df_tr = pd.read_csv('6장/trans_route.csv', index_col = '공장')
df_pos = pd.read_csv('6장/trans_route_pos.csv')
display(df_tr, df_pos)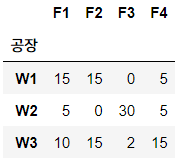

2가지 데이터를 불러왔습니다. 참고로 문제를 단순화하기 위해, df_tr 데이터에서는 창고(W) -> 공장(F) 에서만 물류가 이동한다고 봅니다.
시각화를 할 때는 창고(W)와 공장(F)을 노드로 사용하고, 각 노드 간 가중치를 df_tr 데이터로 사용합니다. 그리고 창고와 공장의 위치정보는 df_pos 데이터를 활용하면 되겠죠?
책에 시각화 코드가 나와있는데, 좀 복잡하게 되어 있어서 더 간단하게 쓴 제 코드로 설명하겠습니다.
시각화 코드의 순서는 위에서 했던 것과 똑같습니다. 노드 설정 - 엣지 설정 - 좌표 설정의 순서로 하면 됩니다. 여기서 주의할 점은 경로는 창고에서 공장으로의 이동만 있다는 점입니다. 따라서, 창고와 창고 간의 이동이나 공장과 공장 간의 이동은 없습니다.
그러므로, 엣지를 설정할 때 창고(W)에서 하나를 뽑고, 공장(F)에서 하나를 뽑아 연결짓는 방식으로 코드를 짰습니다.
가중치를 적용하지 않은 버전입니다.
#객체
G = nx.Graph()
#노드 설정(W 3개, F 4개)
for i in range(len(df_pos.columns)):
G.add_node(df_pos.columns[i])
#엣지 설정(W에서 하나 - F에서 하나를 연결)
for i in range(0, 3):
for j in range(3, len(df_pos.columns)):
G.add_edge(df_pos.columns[i], df_pos.columns[j])
#좌표 설정
pos = {}
for i in range(len(df_pos.columns)):
node = df_pos.columns[i]
pos[node] = (df_pos[node][0],df_pos[node][1])
#그리기
nx.draw(G, pos, with_labels=True)
plt.show()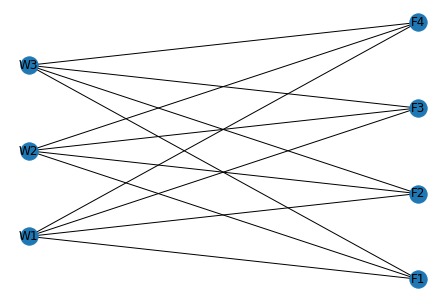
엣지에 가중치를 설정해봅시다. 가중치로는 df_tr의 값을 사용하는데, 가중치 값이 너무 커서 값을 그대로 사용하면 선이 엄청 뚱뚱하게 그려집니다. 그래서 가중치 값에 0.1을 곱해 값을 좀 줄여줍니다.
sy = []
size = 0.1 #가중치 값이 너무 커서 줄임 (그대로 쓰면 엣지가 엄청 굵게나옴)
for i in range(len(df_tr.index)):
for j in range(len(df_tr.columns)):
sy.append(df_tr.iloc[i,j]*size)
sy
위에서 만든 가중치 리스트 sy를 넣어 그림을 다시 그려봅니다.
#그래프 다시 그리기
nx.draw(G, pos, with_labels=True,
font_size = 16, node_size = 1000, node_color = 'k', font_color= 'w', width = sy) #width에 가중치 리스트 설정
plt.show()
이렇게 경로가 완성되었습니다. 이렇게 시각화하여 경로를 뽑아보니, 그냥 숫자로 볼 때보다 훨씬 더 직관적인 이해가 가능하죠? 창고 W2에서 공장 F3로 가는 경로가 가장 두드러지네요!
이번엔 책에 나온 방식으로 코드를 설명하겠습니다.
다른 점은 엣지와 가중치 설정 부분인데요. 저는 엣지와 가중치 설정 코드를 따로 썼지만 책에서는 for문으로 묶어 한번에 해결했습니다.
또한 저는 창고(W)와 공장(F) 간에만 엣지를 설정할 수 있기 때문에 W에서 하나, F에서 하나를 뽑아 엣지를 설정했지만, 책에서는 그냥 모든 조합을 만들고 W와 F를 연결하는 것이 아닌 경우엔 가중치(weight)를 0으로 두는 방법을 썼습니다. 주석에 설명을 달아두었으니 참고하세요!
#객체
G = nx.Graph()
#노드 설정(W 3개, F 4개)
for i in range(len(df_pos.columns)):
G.add_node(df_pos.columns[i])
#----------------------------------------- 엣지와 가중치 리스트 설정을 한번에!
num_pre = 0
edge_w = [] #가중치 리스트. for문을 통해 가중치(weight) 값을 하나하나 쌓을것
size = 0.1
for i in range(len(df_pos.columns)):
for j in range(len(df_pos.columns)):
if i != j :
#이 경우에만 엣지 설정 -> 자기자신에 대해서는 X, 다만 W끼리, F끼리도 엣지 설정할 수 있음 (가중치만 안 넣어주면 됨)
G.add_edge(df_pos.columns[i], df_pos.columns[j])
#엣지 가중치 추가
if num_pre < len(G.edges): #num_pre의 기본값인 0보다 len(G.edges)가 크다면 (즉, 엣지가 하나 이상 만들어진 경우)
num_pre = len(G.edges) #num_pre 값을 len(G.edges)로 바꿔줌
weight = 0 #가중치 초기화 : W끼리/ F끼리의 엣지라면 0으로 넣게됨.
## 이제 weight를 추가해보자. (weight는 W와 F 간에만 존재)
if (df_pos.columns[i] in df_tr.columns) and (df_pos.columns[j] in df_tr.index): #i에 해당하는 F 와 j에 해당하는 W값이 존재(True) 한다면
if df_tr[df_pos.columns[i]][df_pos.columns[j]]: #가중치값이 존재(True)한다면
weight = df_tr[df_pos.columns[i]][df_pos.columns[j]]*size #weight에 그 값을 넣기
elif (df_pos.columns[j] in df_tr.columns) and (df_pos.columns[i] in df_tr.index): #반대로, j에 해당하는 F와 i에 해당하는 W 값이 존재한다면
if df_tr[df_pos.columns[j]][df_pos.columns[i]]: #그리고 가중치값이 존재한다면
weight = df_tr[df_pos.columns[j]][df_pos.columns[i]]*size #weight에 그 값을 넣기
#weight(가중치) 리스트화
edge_w.append(weight)
#---------------------------------------------
#좌표 설정
pos = {}
for i in range(len(df_pos.columns)):
node = df_pos.columns[i]
pos[node] = (df_pos[node][0],df_pos[node][1])
#그리기
nx.draw(G, pos, with_labels=True,
font_size = 16, node_size = 1000, node_color = 'k', font_color= 'w', width = edge_w) #width에 가중치 리스트 설정)
plt.show()
좀더 자세히 설명하자면 if문이 한번 실행될 때마다 edge_w에 가중치(weight) 값이 차곡차곡 담깁니다. W끼리의 가중치이거나 F끼리의 가중치이면 기본값인 0이 담기고, W와 F 간의 가중치라면 df_tr에 있는 가중치값이 담깁니다.
이렇게 해서 총 21개의 가중치가 담기게 되는데요, 이는 7개의 가짓수(창고+공장 개수 = 7개) 에서 중복을 포함하지 않게 2개를 선택하는 경우인 7C2 = 21의 값과 동일합니다.
제가 한 것은 어차피 W끼리, F끼리의 가중치 값은 0이므로 애초에 포함시키지 않는 방법을 썼습니다. 즉, W와 F 각각에서 중복을 포함하지 않고 하나씩 뽑는 것이므로 3C1 * 4C1 =12개입니다. 앞서 21개 중에서 가중치 값이 있는 경우는 12개뿐이므로 제가 한 것과 교재에서 한 결과가 같은 이유입니다! (저는 개인적으로 제가 한 방법이 더 쉬운 거 같네요..!)
이로써 오늘의 포스팅을 마칩니다. 이번 포스팅을 통해, python networkx 라이브러리를 활용해 경로를 시각화하는 방법을 배웠습니다.
다음 포스팅에서는 목적 함수와 제약조건을 설정하는 방법을 배우고, 직접 이를 설정하여 최적화를 진행해봅니다.
궁금한 점 있으시다면 언제든 댓글 주세요! 감사합니다 :)
'Data Science > Analysis Study' 카테고리의 다른 글
| 파이썬 운송 최적화 -1편 (python pulp, ortoolpy) / 파이썬 데이터 분석 실무 테크닉 100 (0) | 2022.04.27 |
|---|---|
| 물류 이동 경로 최적화하기 (python optimization, 목적함수, 제약조건) / 파이썬 데이터 분석 실무 테크닉 100 (4) | 2022.04.17 |
| 최적화 문제란? (python optimization) / 파이썬 데이터 분석 실무 테크닉 100 (1) | 2022.04.16 |
| 머신러닝을 활용한 고객 이탈 예측 - 모델링 / 파이썬 데이터 분석 실무 테크닉 100 (4) | 2022.04.13 |
| 머신러닝을 활용한 고객 이탈 예측 - 전처리 / 파이썬 데이터 분석 실무 테크닉 100 (6) | 2022.04.12 |



