
Yours Ever, Data Chronicles
머신러닝을 활용한 고객 이탈 예측 - 전처리 / 파이썬 데이터 분석 실무 테크닉 100 본문
머신러닝을 활용한 고객 이탈 예측 - 전처리 / 파이썬 데이터 분석 실무 테크닉 100
Everly. 2022. 4. 12. 17:57안녕하세요 Everly입니다 :)
지난 4장에서는 클러스터링(Clustering)을 통해 고객의 행동을 유형별로 나눴었죠. 그리고 고객의 과거 6개월 간의 데이터를 바탕으로, 바로 다음 1달 동안의 이용횟수를 선형 회귀(Linear Regression model)를 통해 예측해보았습니다.
이렇게 고객의 행동 패턴을 분석하고 예측할 수 있다면, 실무를 하는 데 있어 여러 활용도가 있을 것입니다. 고객 유형을 나눠 특정 군집에 행동을 유발할 마케팅을 해볼 수도 있고, 다음달 예상되는 이용횟수를 바탕으로 적합한 프로모션을 할 수도 있겠죠. 이를테면 헬스클럽에 수요일이 가장 적게 올 것이 예측되면 '수요일은 헬스데이!' 라는 프로모션을 만들 수도 있을 것입니다.
이렇게 머신러닝(Machine Learning)을 활용하면 비즈니스 의사결정에 큰 도움을 줄 수 있습니다. 이번 5장에서는 고객의 행동 패턴을 분석하여, 어떤 고객이 탈퇴할지를 예측해봅니다. 이를 예측할 수 있다면 이 고객의 탈퇴 방지를 위한 정책을 준비할 수 있을 것입니다.
이번 장에선 탈퇴회원 및 지속회원 데이터를 바탕으로, 이 회원이 이탈할지를 예측하는 지도학습 모델링을 해봅니다. 4장이 회귀(Regression)의 문제였다면, 이번 5장은 탈퇴(1) 인지 아닌지(0)를 예측하므로 분류(Classification)의 문제가 되겠습니다.
✔Table of Contents
Tech 41. 데이터를 불러오고, 수정하자
여기서 사용하는 데이터는
- 3장에서 만들었던 customer_join.csv
- 4장에서 만들었던 use_log_months.csv
이렇게 2가지를 이용합니다.
import pandas as pd
c = pd.read_csv('customer_join.csv')
ul_m = pd.read_csv('use_log_months.csv')
display(c, ul_m)


먼저 customer_join은 'c' 라는 데이터로, use_log_months는 'ul_m'으로 불러옵니다.
위의 두 사진은 각각 c와 ul_m의 데이터입니다. 이 2가지 데이터를 활용하여, 머신러닝 모델에 적용할 수 있는 데이터를 만들기 위해 가공합니다.
지난 4장에서는 미래를 예측하기 위해 과거 6개월 간의 데이터를 가져오도록 가공을 했었죠? 하지만 이번에는 해당 달과 그 직전 달 이렇게 2개월 분의 데이터만 가져옵니다.
(그 이유는 6개월로 하면 가입 5개월 이내인 회원의 탈퇴는 예측할 수 없기 때문입니다. 또한 3장에서도 봤지만 '마의 10개월' 이라, 10개월을 넘긴 회원이 많이 없고, 불과 몇개월도 안 되어 탈퇴한 회원도 있기에 간격을 짧게 설정합니다.)
코드는 지난 4장에서 썼던 코드와 비슷합니다. 과거 6개월 데이터에서 -> 과거 1개월 데이터를 가져오도록 조금만 수정하면 됩니다. 먼저 'uselog'라는 빈 데이터프레임을 만들고, for문을 돌려 여기에 가공한 데이터를 차곡차곡 쌓아줍니다.
## 이번 코드는 4장에서 가공한 데이터프레임과 비슷한데, 6개월-> 1개월로 단축하였으므로 이전에 만든 코드를 조금만 수정하자.
year_months = list(ul_m['연월'].unique())
uselog = pd.DataFrame() #비슷하게 빈 데이터프레임을 생성하고 여기에 가공한 데이터를 쌓아준다.
year_months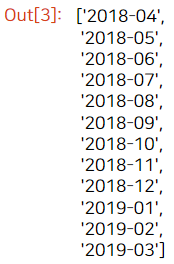
for문을 돌리기에 앞서 year_months에서 필요한 연월을 살펴봅니다. 데이터는 2018년 4월부터 2019년 3월까지 있는데, 해당 달과 바로 직전 달의 데이터가 있어야 하므로 2018년 4월만 빼고 데이터를 가공하면 되겠죠?
그래서 for문의 범위(range)는 인덱스 1번(2018-05) 부터 시작합니다.
for i in range(1, len(year_months)): #직전 달의 데이터를 얻을 수 있어야 하므로 2018년 5월~2019년 3월까지에 대해서만 설정. 그래서 인덱스 1부터 시작
#해당 월에 대한 임시 데이터프레임 생성
tmp = ul_m.loc[ul_m['연월'] == year_months[i]]
tmp.rename(columns = {'cnt': 'cnt_0'}, inplace=True)
#그리고 해당 월의 바로 직전 달에 대한 임시 데이터프레임 생성
tmp_before = ul_m.loc[ul_m['연월'] == year_months[i-1]]
del tmp_before['연월'] #'연월' 컬럼은 2번 쓸 필요 없으므로 삭제
tmp_before.rename(columns = {'cnt': 'cnt_1'}, inplace=True)
#이제 두 데이터프레임을 결합
tmp = pd.merge(tmp, tmp_before, on = 'customer_id', how='left')
#tmp를 빈 데이터프레임인 uselog에 차곡차곡 쌓기(row-bind)
uselog = pd.concat([uselog, tmp], axis=0, ignore_index=True) #행 인덱스를 그대로 붙이지 않고 초기화시킴
uselog
먼저 year_months에 해당하는 ul_m 값을 'tmp'로 설정합니다. tmp는 해당 월의 데이터프레임이며 이 때의 이용횟수(cnt) 컬럼명을 'cnt_0'로 바꿔줍니다.
그리고 바로 직전 달에 해당하는 ul_m 값은 'tmp_before'로 설정합니다. 그리고 이 때의 이용횟수(cnt) 컬럼명을 'cnt_1'으로 바꿔줍니다. 어차피 '연월'은 해당 월만 있으면 되므로, tmp_before 데이터셋의 연월은 삭제해줍니다.
이렇게 만들어진 tmp와 tmp_before를 merge시키고, 처음 만들어두었던 uselog 데이터셋에 차곡차곡 쌓으면 됩니다. row-bind로 쌓을 것이므로 axis=0으로 설정합니다. 참고로 ignore_index = True 옵션을 주면 데이터셋이 쌓일 때 인덱스가 초기화됩니다.
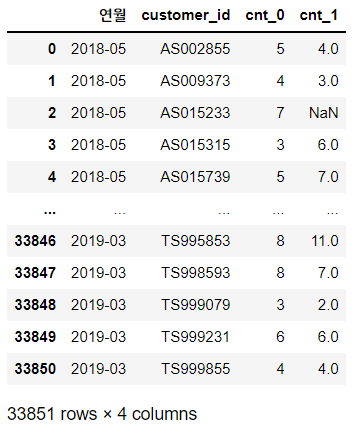
만들어진 데이터셋을 보면, 해당 연월의 이용횟수는 cnt_0에, 바로 직전 달의 이용횟수는 cnt_1에 들어간 것을 확인할 수 있습니다.
이제 예측을 위해 가장 중요한 컬럼을 생성합니다. 바로 "이 회원이 탈퇴했는가 or 아닌가" 라는 컬럼입니다.
이를 위해선 c 데이터셋에서 customer_id와 일치하는 is_deleted 컬럼을 가져와야겠죠? (*이 컬럼은 탈퇴한 경우 1, 아니면 0의 값을 가짐) 지금부터 바로 해봅시다.
Tech 42. 탈퇴회원의 데이터를 작성하자.
이 헬스장은 특이하게도 탈퇴를 하고 싶으면 바로 직전 달에 탈퇴신청을 해야 하는 규칙이 있습니다.
예를 들어, 2019년 2월에 탈퇴하고 싶어 탈퇴신청을 할 경우, 2019년 3월에 탈퇴 처리가 완료됩니다. 데이터셋의 탈퇴시점(end_date)에는 2019년 3월로 기록이 남죠.
그래서 이 데이터 분석에서는 탈퇴시점(end_date) 뿐만 아니라, 탈퇴 전 시점(탈퇴시점의 1달 전)이 중요합니다. 이 때 신청을 해야만 탈퇴가 가능하니까요. 과연 탈퇴한 고객들은 탈퇴 전 시점에 어떤 행동을 보였을까요?
end_date는 데이터로 주어져 있지만, 탈퇴 전 시점은 없으므로 exit_date 라는 새로운 컬럼을 만들어봅시다.
우선 exit_date 를 만드려면 당연히 탈퇴를 한 회원에 대해서만 만들어야겠죠? 그래서 is_deleted 컬럼이 1인 값만 뽑아 탈퇴고객만 추려냅니다.
from dateutil.relativedelta import relativedelta
#우선 탈퇴고객을 뽑는다. (1350명)
exit_c = c.loc[c['is_deleted'] == 1]
#탈퇴 전 시점인 'exit_date'를 만들고, 탈퇴시점 'end_date'는 datetime으로 바꿔준다.
exit_c['exit_date'] = None
exit_c['end_date'] = pd.to_datetime(exit_c['end_date'])
exit_c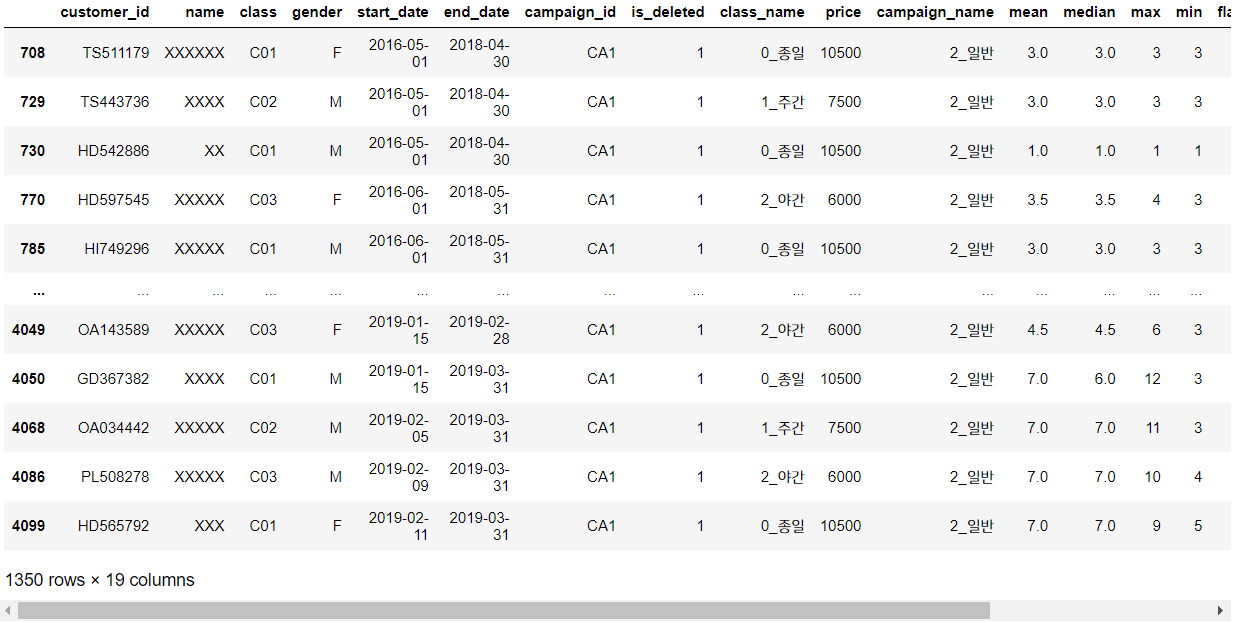
탈퇴고객만 모은 데이터셋 'exit_c' 를 만들어보니 총 1350행이 있네요. 탈퇴고객은 1350명입니다.
그리고 exit_date를 구하기 위해 먼저 end_date 부터 datetime 형태로 변환해줍니다.
다음으로는 end_date 값에서 1달을 뺀 값을 exit_date에 넣어줍니다. relativedelta를 사용합니다.
#이제 exit_date 컬럼을 end_date에서 1개월 전의 날짜로 채워보자.
for i in range(len(exit_c)):
exit_c['exit_date'].iloc[i] = (exit_c['end_date'].iloc[i] - relativedelta(months = 1))
exit_c.head()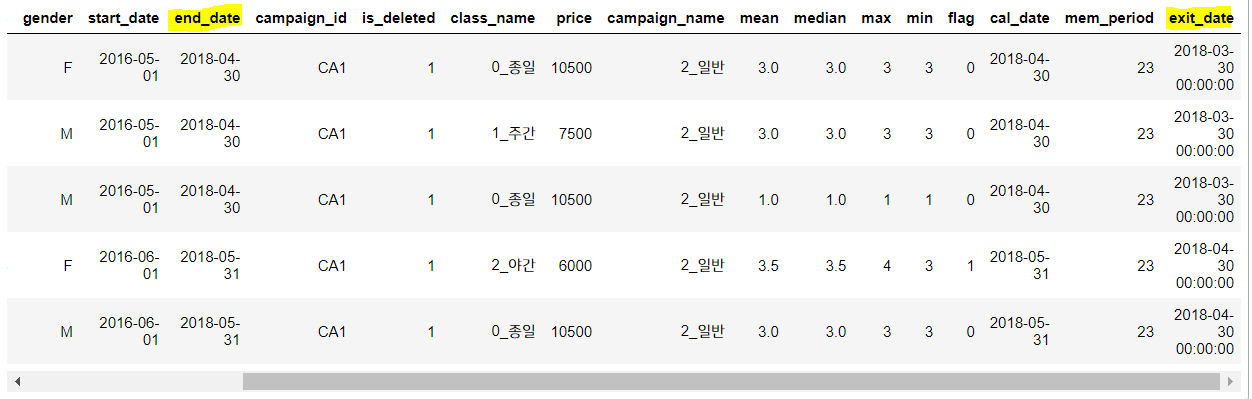
결과를 보면 잘 들어간 것을 확인할 수 있죠?
이제 exit_date에서 연월만 뽑아 새로운 '연월' 컬럼을 만들어봅니다.
exit_c['exit_date'] = pd.to_datetime(exit_c['exit_date'])
exit_c['연월'] = exit_c['exit_date'].dt.strftime("%Y-%m")
exit_c.head()
이제 탈퇴회원의 이용이력을 확인하기 위해, 앞서 가공한 'uselog' 데이터셋의 '연월' 컬럼과 조인시킵니다. 이렇게 되면 탈퇴회원이 바로 직전 달(exit_date)에 몇 회나 이용했는지를 알 수가 있겠죠?
(여기서 '연월'의 값은 end_date가 아닌 exit_date로 했다는 점 주의!)
exit_uselog = pd.merge(uselog, exit_c, on = ['customer_id', '연월'], how='left')
print(len(uselog))
print(len(exit_uselog))
exit_uselog.head()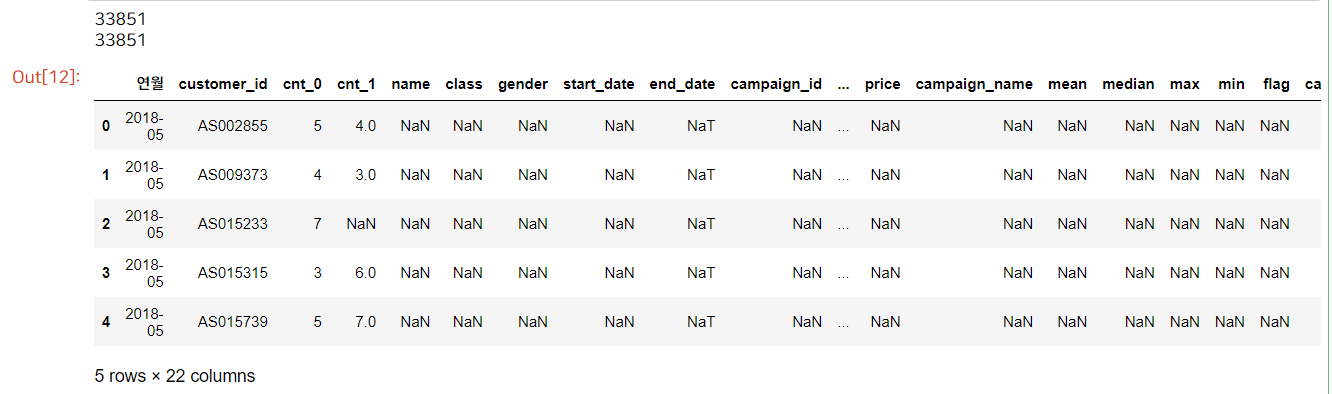
uselog를 기준으로 left join 시켰으므로, 만든 데이터셋 'exit_uselog'는 uselog의 전체 행 개수와 같아집니다.
exit_uselog 데이터를 보면 한 눈에 보기에도 NaN 값이 너무 많아 보이죠. 이는 당연합니다.
왜냐하면 우리가 앞서 Tech 41에서 가공한 uselog 데이터는 탈퇴회원과 지속회원이 모두 포함되어 있어요. 하지만 여기 결합했던 exit_c 데이터는 탈퇴회원만 있으므로, uselog 데이터를 기준으로 데이터를 결합시켰으니 탈퇴회원인 경우만 값이 있고 아닌 경우는 값이 비어 NaN 으로 채워진 것입니다. 이를 그림으로 나타내볼게요.

이제 이해가 되시죠? 결합해서 만들어진 'exit_uselog'는 결측치가 너무 많으므로, 'name' 열에 결측치가 하나라도 있으면 삭제하겠습니다.
이를 위해선 dropna를 사용하는데, subset 옵션으로 특정 컬럼을 지정할 수 있습니다. 이를 지정하면 이 특정 컬럼에 결측치가 있는 경우에만 전체 행을 삭제합니다.
#exit_uselog에서 'name'에 결측치가 하나라도 있으면 삭제 -> 1104개 데이터로 줄어듦
exit_uselog = exit_uselog.dropna(subset = ['name'])
print(len(exit_uselog))
print(exit_uselog['customer_id'].nunique())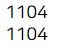
아까 33851개였던 데이터가 1104개로 확 줄어들었네요!
customer_id의 유니크한 값으로 셌을 때 전체 데이터의 행 개수와 같으므로, customer_id도 고유하게 (중복 없이) 들어가 있음을 확인했습니다.
마지막으로 exit_uselog의 결측치가 있는지를 확인해봅시다.
exit_uselog.isna().sum()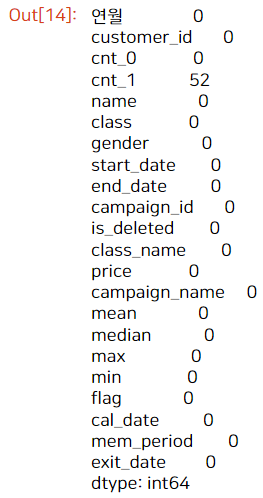
결측치는 cnt_1 에만 52개가 존재합니다. 이는 exit_date를 연월로 묶은 것이므로, cnt_0가 탈퇴 전 월, cnt_1이 탈퇴 2개월 전 월을 뜻하죠. -> 즉, 탈퇴 2개월 전에 사용한 적이 없는 경우 결측치로 나타납니다.
이러한 결측치가 있으면 머신러닝 모델링을 할 수 없으니 추후 처리해주겠습니다.
아무튼 이렇게 특정 회원이 탈퇴하기 전(1개월, 2개월 전)의 상태를 나타내는 데이터 exit_uselog를 만들어보았습니다. 이 데이터는 모두 탈퇴를 한 회원의 데이터입니다.
이번에는 탈퇴하지 않은, 지속회원은 어떤 상태를 보이는지를 분석해봅시다.
Tech 43. 지속회원의 데이터를 작성하자.
지속회원은 탈퇴를 한 적이 없는 회원을 말하죠. 그러므로 지속회원은 어떤 연월의 데이터를 작성해도 상관없습니다.
탈퇴회원에서 했던 것과 마찬가지로 지속회원을 추출하고 uselog와 결합시켜 봅시다.
#지속회원 추출
conti_c = c[c['is_deleted'] == 0]
print(len(conti_c))
#uselog 데이터와 결합
conti_uselog = pd.merge(uselog, conti_c, on = ['customer_id'], how='left')
print(len(conti_uselog))
conti_uselog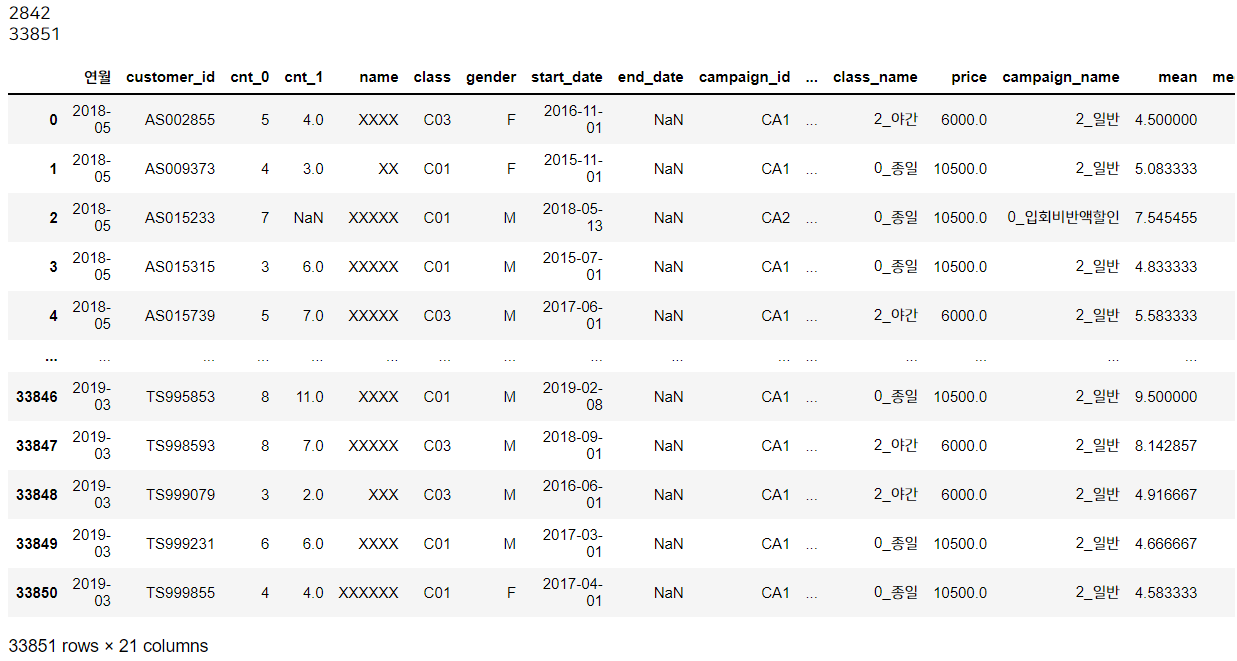
지속회원은 is_deleted 열의 값이 0인 것이겠죠. 2842명이 존재합니다.
이를 customer_id를 key로 하여 uselog와 조인시킵니다. uselog를 기준으로 조인했으므로 uselog의 행 개수와 동일하게 33851개가 나옵니다. 이 지속회원의 데이터셋은 'conti_uselog'라고 합시다.
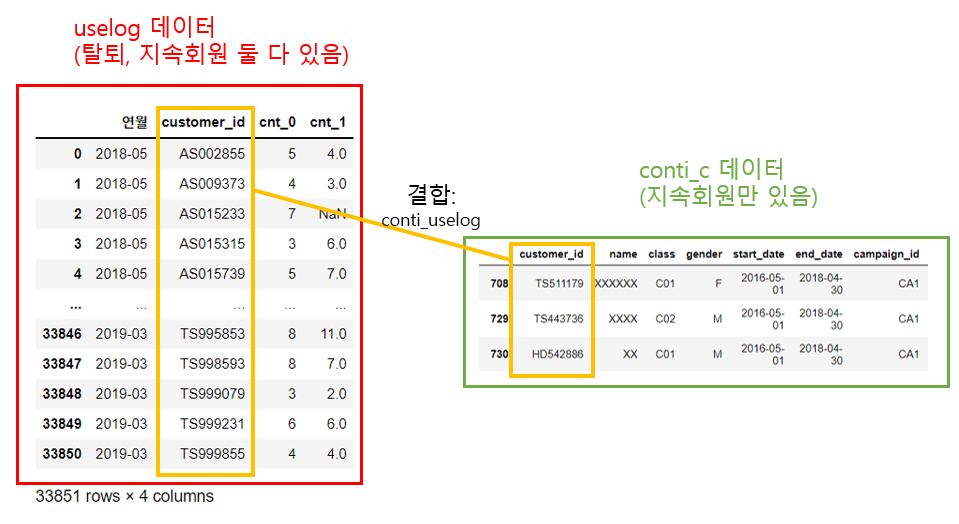
앞서 탈퇴회원에서 했던 것처럼, 지속회원이 아닌 탈퇴회원의 데이터가 있는 경우 결측치가 있을 것입니다. 이를 제거하기 위해 'name'에 결측치가 있으면 drop합시다.
conti_uselog = conti_uselog.dropna(subset = ['name'])
print(len(conti_uselog))
print( )
print(conti_uselog.isna().sum())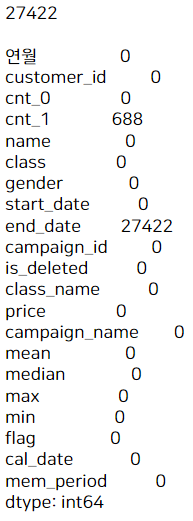
결측치를 제거하고 보니 원래 33851개에서 -> 27422개로 줄었습니다. 탈퇴회원은 탈퇴 직전 1개월, 2개월의 데이터만 세이브한 반면 지속회원은 탈퇴를 하지 않았기 때문에 모든 연월의 데이터가 있어 exit_uselog보다 훨씬 많습니다.
- 예를 들어 Everly라는 사람이 2018년 10월과 2019년 1월 두번 모두 이용한 적이 있다면, 이것이 2개의 행으로 존재합니다. (한 행은 연월 2018-10, 다른 한 행은 연월이 2019-01)
어쨌든 cnt_1(직전 월)에 688개의 결측치가 있네요. end_date는 탈퇴시점이므로 모든 행에 있어야 하는 결측치입니다. (탈퇴시점이 없어야 지속회원이니까요!)
그런데 탈퇴회원(exit_uselog) 데이터가 지속회원(conti_uselog) 데이터에 비해 너무 적게 되어버리면 문제가 생깁니다. 이런 데이터를 불균형 데이터(imbalanced data) 라고 합니다. 예를 들어 보험사 사기 예측의 문제를 아시나요? 사기를 친 케이스가 극소수고 대다수가 사기를 치지 않은 것이므로 이런 데이터로는 아무리 모델을 정교하게 만들어도 좋은 예측 성능을 기대하기 어렵습니다.
이를 위해서 지속회원 데이터가 회원 당 여러개가 아니라 딱 1개의 데이터만 남을 수 있도록 언더샘플링(UnderSampling)을 합니다.
위의 예시에서 Everly라는 사람이 2번 이용한 경우, 중복을 제거하여 Everly의 이용이 단 1개의 행만 남도록 하는 것입니다. 이를 위해 데이터를 랜덤하게 섞은 후 중복을 제거합니다.
#데이터 섞고 중복 제거 (고객별로 랜덤하게 단 하나)
conti_uselog = conti_uselog.sample(frac = 1, random_state = 99).reset_index(drop = True) #frac은 뽑는 비율을 의미, 0~1 사이값을 설정 가능. 인덱스가 랜덤히 섞이므로 인덱스도 리셋해줘야 함
conti_uselog = conti_uselog.drop_duplicates(subset = 'customer_id') #고객id의 중복 제거, 디폴트로는 첫번째 값만 남기고 나머지는 drop
print(len(conti_uselog))
conti_uselog.head()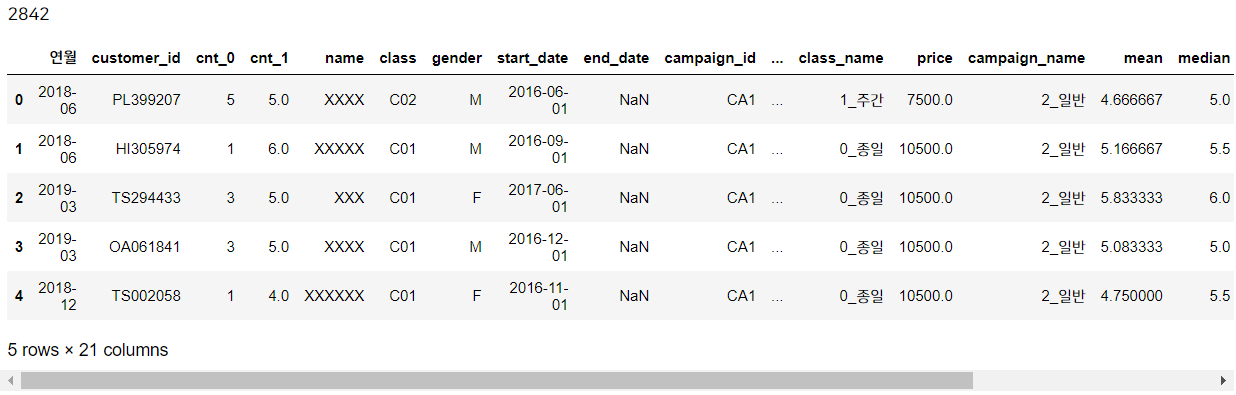
데이터를 랜덤하게 섞기 위해선 python sample 함수를 사용합니다. frac 옵션은 뽑는 비율을 의미하며 0~1 사이값을 입력합니다. 예를 들어 0.2를 입력한다면 100개 중에서 20개를 랜덤으로 뽑아줍니다. 여기선 그냥 인덱스만 섞을 것이므로 1을 입력합니다.
주의점은 sample 함수는 랜덤하게 섞으므로 코드를 실행할 때마다 다른 값이 나온다는 것입니다. 그래서 저는 random_state 값을 임의로 99로 설정했습니다. 이렇게 설정하면 코드를 실행할 때 다른 값이 나오는 것을 방지합니다. (참고로 이렇게 설정해서 책에서 한 모델링 정확도와 제가 한 모델링 정확도가 살짝 다르게 나왔습니다.)
한 회원에 대해 중복을 제거하기 위해선 customer_id에 대해 drop_duplicates 함수를 사용합니다. 결과를 보면 지속회원의 고유한 개수였던 2842개로 줄어들었네요!
자, 이렇게 해서 탈퇴회원의 데이터 exit_uselog, 지속회원의 데이터 conti_uselog 이렇게 2개를 잘 만들어 보았습니다. 두 개의 데이터 수도 큰 차이가 안 나네요! 이제 row-bind로 두 데이터셋을 묶은 최종 데이터셋 'pred_data'를 만들어봅시다.
#이렇게 탈퇴회원과 지속회원 데이터 개수를 비슷하게 맞췄다. 이 둘을 row-bind로 묶고 새로운 데이터셋 'pred_data'를 만들어보자
pred_data = pd.concat([conti_uselog, exit_uselog], ignore_index = True)
pred_data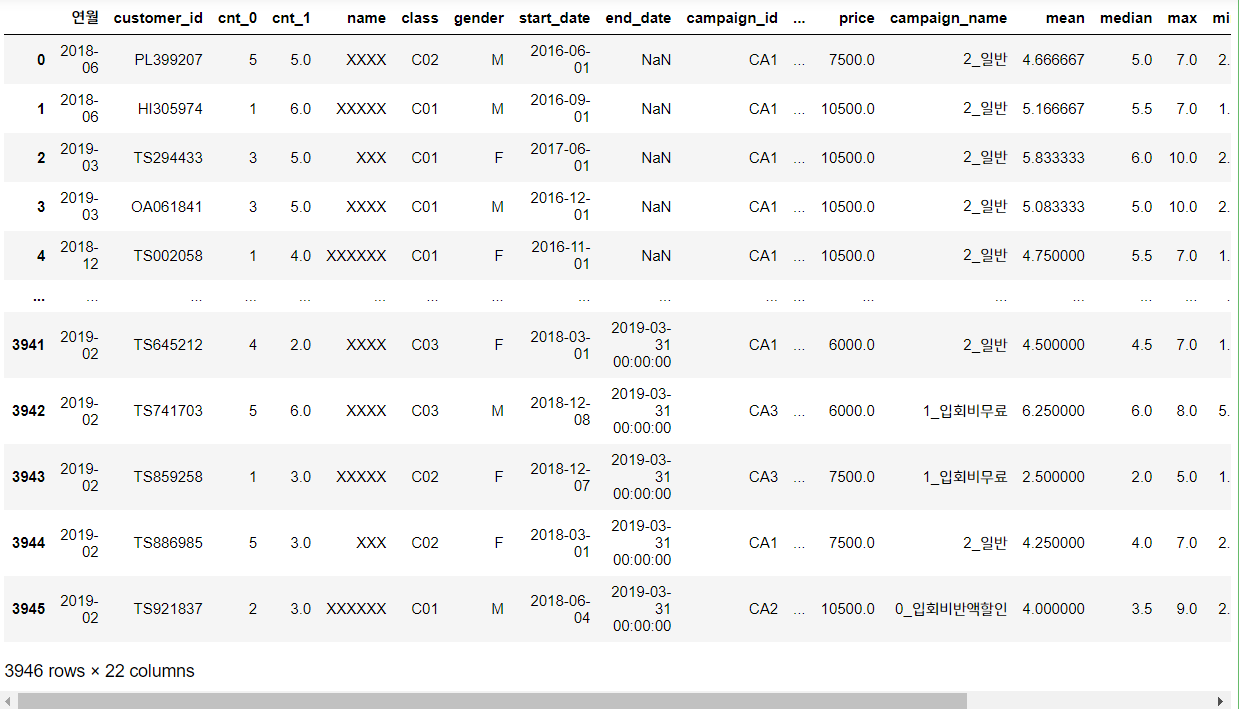
이렇게 전처리를 마쳤습니다. 아직 결측치 처리 등 자잘한 것이 남아 있지만, 포스팅이 너무 길어지는 관계로 다음 장에서 이어집니다. 다음 장에서는 직접 모델링을 통해 고객 이탈을 예측해봅니다.
'Data Science > Analysis Study' 카테고리의 다른 글
| 최적화 문제란? (python optimization) / 파이썬 데이터 분석 실무 테크닉 100 (1) | 2022.04.16 |
|---|---|
| 머신러닝을 활용한 고객 이탈 예측 - 모델링 / 파이썬 데이터 분석 실무 테크닉 100 (4) | 2022.04.13 |
| 머신러닝을 활용한 고객 이용 횟수 예측 - 모델링 / 파이썬 데이터 분석 실무 테크닉 100 (6) | 2022.04.06 |
| 머신러닝을 활용한 고객 이용 횟수 예측 - 전처리 / 파이썬 데이터 분석 실무 테크닉 100 (4) | 2022.04.06 |
| 고객 유형을 나누기(파이썬 클러스터링, 군집 분석) / 파이썬 데이터 분석 실무 테크닉 100 (6) | 2022.04.06 |



