
Yours Ever, Data Chronicles
파이썬 EDA : 고객의 전체 모습 파악하기 -2편 / 파이썬 데이터 분석 실무 테크닉 100 본문
파이썬 EDA : 고객의 전체 모습 파악하기 -2편 / 파이썬 데이터 분석 실무 테크닉 100
Everly. 2022. 1. 17. 22:57저번 포스팅에 이어, 이번에는 이용이력(ul) 데이터를 가공하여 사전 분석을 실시한다.
✔Table of Contents
Tech 25. 이용이력 데이터를 집계하자.
이용이력 데이터는 저번 포스팅에서 했던 고객 데이터와 다른 점이 무엇일까?

바로 고객 데이터와는 달리, 회원이 스포츠센터를 이용할 때마다 시간이 찍히기 때문에 시간적인 요소를 분석할 수 있다.
예를 들어 한 달 이용 횟수의 변화나, 회원이 스포츠센터를 정기적/비정기적으로 이용하는지 와 같은 것들이다.
우리는 우선, 스포츠센터를 이용하는 회원들이 월별 몇 회를 이용하는지 그 평균값, 중앙값, 최댓값, 최솟값을 구해보도록 하자.
이용이력(ul) 데이터는 고객데이터와는 달리 customer_id가 중복이 있기 때문에(이용할 때마다 찍히는 데이터이니 당연하다) 월별, 고객 id별로 묶어 통계를 내고, 그 다음에 월별로 전체 통계를 낸다.
ul['usedate'] = pd.to_datetime(ul['usedate'])
#연월로 변경
ul['연월'] = ul['usedate'].dt.strftime("%Y%m")
ul.head()우선 '월별' 을 뽑기 위해 날짜 형태를 연월로 바꿔준다. 현재 'usedate'가 날짜형이 아니므로 변환 후,

월별, 고객id별 이용횟수를 카운트한다. (groupby 후 log_id를 count)
#연월, 고객별 이용횟수를 알아보자!
ul_month = ul.groupby(['연월', 'customer_id'], as_index = False).count()
#as_index=False 인자를 넣으면 연월, customer_id가 인덱스가 아니게 됨. 주의점은 groupby 메서드 안에 넣기!
ul_month※ 주의점으로는 as_index =False 인자를 써주지 않으면 디폴트로 "연월"과 "customer_id"가 인덱스로 잡히게 된다. 뭐 나중에 인덱스를 reset시켜주면 되긴 하지만, groupby 시 as_index 인자를 써줌으로써 굳이 나중에 reset을 해야 하는 수고로움을 덜 수 있다!
여기서 어차피 log_id를 count한 것이나, usedate를 count한 것이나 데이터 수를 세는 것은 같기에 두 컬럼값이 같게 나온다.
여기서 log_id 컬럼을 'cnt'로 바꾸고 (rename 메서드 사용)
usedate 컬럼을 삭제하자. (drop 메서드 사용)
#log_id -> cnt 변경
ul_month.rename(columns = {'log_id':'cnt'}, inplace=True)
#usedate 열 삭제
ul_month.drop('usedate', axis=1, inplace=True)
ul_month.head()
이제 월별, 고객별 스포츠센터 사용 횟수 데이터가 완성되었다.
하지만 이 상태로는 어떠한 의미도 찾을 수 없다. 다시 groupby를 사용해 의미 있는 결과를 낼 수 있도록 통계를 내보자.
여기서 customer_id(고객id)를 기준으로 cnt의 평균을 낸다면, 고객별 월평균 사용횟수를 구할 수 있을것이다.
평균뿐 아니라 중위값, 최댓값, 최솟값도 구해보자.
#이렇게만 끝내면 전혀 어떠한 정보도 없음. 고객별 평균, 중앙, 최댓, 최솟값을 집계
import numpy as np
ul_month.groupby('customer_id')['cnt'].agg([np.mean, np.median, np.max, np.min])※ 위 코드처럼 groupby는 agg 함수 사용이 자유롭다는 것이 장점이다.
특히 위처럼 np.집계함수를 사용해 리스트로 묶어주면, groupby의 통계량 여러가지를 한번에 구할 수 있다.

#np를 안쓰는 경우..
ul_month.groupby('customer_id')['cnt'].agg(['mean','median','max','min'])참고로, 위에 agg 함수에 넣은 것은 numpy에서 제공하는 집계함수를 사용하였는데, 일반적인 통계량을 구하는 것인 경우엔 위의 코드를 사용해도 같은 결과가 나온다.
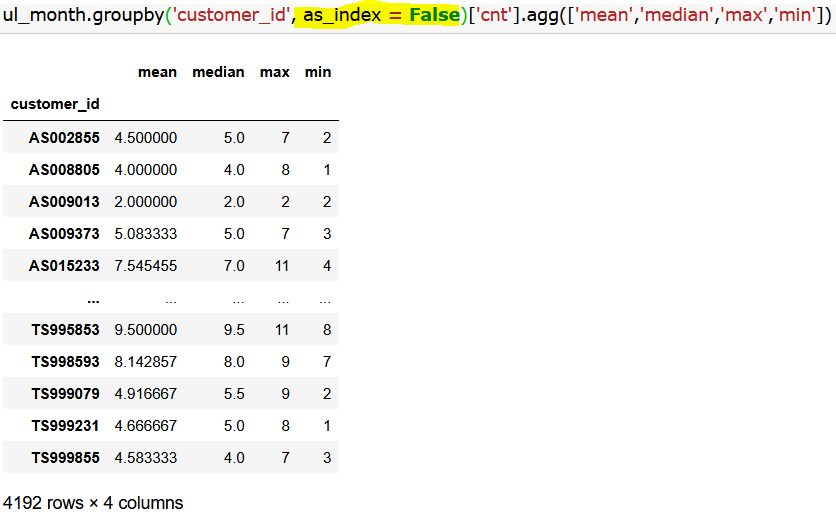
이제, customer_id가 인덱스로 설정되었으니 이를 지우고 최종 데이터프레임 'ul_cust'를 완성했다.
ul_cust = ul_month.groupby('customer_id')['cnt'].agg(['mean','median','max','min'])
#인덱스 삭제 (기존 인덱스는 버리지 않는다)
ul_cust = ul_cust.reset_index(drop=False)
ul_cust.head() #<- 최종적으로, 고객별로 평균/중위/최대/최소 월 사용수
- 해석: 고객번호 AS002855인 사람은 월 평균 4.5회, 중위값 5회, 월 최대 7회, 월 최소 2회를 이용했군.
(※ 잠깐! 여기서 customer_id가 인덱스로 설정되는 게 싫으면, 아까처럼 groupby 메서드 안에 as_index=False를 쓰면 되지 않나? 라고 생각할 수 있다.
하지만 이렇게 여러 가지 집계함수를 한번에 사용할 경우 as_index = False 인자가 적용되지 않아, 조금 불편하지만 reset_index를 사용해 인덱스를 리셋해주자.)
Tech 26. 이용이력 데이터로부터 정기 이용 플래그(0-1 coding)를 작성하자.
스포츠센터의 경우, 지속 요소 중 하나가 '습관'이다.
그래서 여기서는 정기적으로 센터를 이용하는 고객을 특정해보자. 이는 정의하는 방법에 따라 다르지만, 매주 같은 요일에 왔는지 아닌지로 판단해보자.
여기서는 임의로, 고객별 그리고 월/요일별로 방문한 횟수의 최댓값이 4 이상인 요일이 하나라도 있는 회원이면 플래그를 1로 처리한다. 즉 0,1로 구성된 binary 변수인 "flag"를 만든다.
-> 다시 말해서, 한 고객이 특정 월이자 특정 요일에 방문한 횟수가 4 이상이라면(ex. 1월에 토요일마다 방문한 횟수가 4라면) 거의 매주 방문한다는 뜻이 된다. 이는 특정 월과 특정 요일에 카운팅한 최댓값이므로, 해당 고객이 매월 특정요일마다 방문한다는 뜻은 아니다. 적어도 1번 이상 그런 적이 있다면 그래도 정기적으로 방문한 사람이라고 생각해 보자는 뜻이다.
이를 위해서 고객별, 월별, 요일별 groupby를 하여 횟수를 count한 후, 그 횟수의 최댓값을 구해보자.
#앞에서 월은 뽑았는데 요일이 없으니 요일을 뽑자.
ul['weekday'] = ul['usedate'].dt.weekday
ul.head()참고로 weekday는 월요일을 0부터 시작하여, 일요일을 6으로 지정한다.
#고객별, 월별, 요일별 방문횟수 카운트
ul_week = ul.groupby(['customer_id', '연월', 'weekday'], as_index=False).count()
ul_week.rename(columns = {'log_id': 'cnt'}, inplace=True)
del ul_week['usedate']
ul_week.head()
이렇게 하여 고객별, 월별, 요일별 방문횟수를 카운트하였다.
한 회원인 AS002855번 고객에 대해 살펴보자. 이 고객은 2018년 4월 토요일(weekday: 5)에 4번, 2018년 5월 수요일(weekday:2)에 1번, 또 2018년 5월 토요일(weekday: 5)에 4번을 방문하였다.
요일번호 5번인 토요일에 자주 온 것으로 보인다. 특히 1달동안 토요일에만 4번이면 매주 토요일마다 왔다는 것이므로, 토요일이 이 고객에겐 헬스데이일 수도 있다.
아무튼, 이제는 고객별로 groupby를 하여 cnt의 최댓값을 뽑자.
ul_week = ul_week.groupby('customer_id', as_index=False)[['cnt']].max()
ul_week
이제 위의 데이터 ul_week를 가지고, cnt 값이 4 이상이면 1, 아니면 0인 'flag' 변수를 만들자.
방법은 3가지가 있다.
## 첫번째 방법: apply lambda 사용하기
ul_week['flag'] = ul_week['cnt'].apply(lambda x: 1 if x>=4 else 0)
## 두번쨰 방법: 불린 인덱싱 사용하기
ul_week['flag'] = 0
#불린 변수(cnt가 4 이상인 변수의 인덱스는 True)
is_over4 = (ul_week['cnt']>=4)
#위의 인덱스로 인덱싱
ul_week.loc[(is_over4), 'flag'] = 1
## 세번째 방법: where문 사용하기
ul_week['flag'] = 0
ul_week['flag'] = ul_week['flag'].where(ul_week['cnt']<4, 1) #조건이 참이면 0이고, 거짓이면 1을 넣는다.
ul_week.head()
3가지 방법 중 편한 것을 골라서 쓰자. 나는 개인적으로 apply lambda 방법이 가장 편리해서 자주 사용하는 방법이다.
이렇게 연산 자동화시키는 것에 있어 중요한 점은, 되도록 for문을 쓰지 말자는 것이다.
데이터의 수가 적으면 상관없지만, 보통 큰 데이터에서 for문은 아주 오랜 시간이 걸리기 때문!
대신 인덱싱을 활용해 연산하거나, 다른 컬럼을 이용해 연산하는 것이라면 apply lambda를 사용하는 것이 가장 편리하고 빠르다. (연산 속도가 진짜 달라진다! 기회되면 나중에 포스팅하겠다.)
Tech 27. 고객 데이터(cust_join)와 이용이력 데이터(ul_cust, ul_week)를 조인하자.
앞서 만든 3개의 데이터들을 다시 가져온다.
#앞서 만든 데이터들
display(cust_join.head(), ul_cust.head(), ul_week.head())
공통 컬럼은 3개 데이터 모두 'customer_id'이다.
늘 해왔던 대로, cust_join을 기준으로 나머지 두 데이터를 left join시킨다.
#cust_join을 기준으로 left join
cust_join = pd.merge(cust_join, ul_cust, on = 'customer_id', how='left')
cust_join = pd.merge(cust_join, ul_week[['customer_id', 'flag']], on = 'customer_id', how='left') #ul_week에서 cnt 열은 버린다.
cust_join.head()
이렇게 최종 데이터인 'cust_join' 파일이 완성되었다.
하지만 방심은 금물! 마지막까지 조인이 잘 되었는지, 데이터 행의 개수와 결측치를 살핀다.
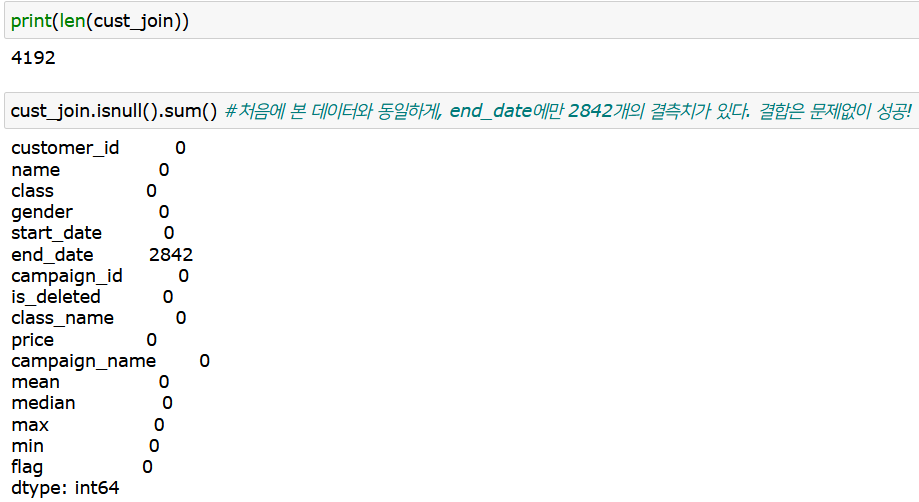
별다른 문제가 없으니 넘어가자.
Tech 28. 회원 기간을 계산하자.
이제 cust_join 데이터를 보면, 기존의 고객 정보뿐 아니라 이용이력 데이터도 모두 들어가서 데이터 분석이 가능해졌다!
여기에 분석에 앞서, '회원 기간'이 어느 정도인지 컬럼 'mem_period'를 추가해두자.
회원기간은 단순히 탈퇴일에서 가입일을 빼면 된다.
그런데 현 데이터에선 탈퇴를 하지 않은 사람들이 많으므로, 탈퇴일이 이렇게 빈 경우는 임의로 '2019년 4월 30일'로 해 두겠다. (2019년 3월 말의 데이터니까 탈퇴일을 2019-03-31로 해야 하지 않나? 싶지만, 2019-03-31에 진짜로 탈퇴한 사람도 있기 때문에 이 사람이 진짜 이때 탈퇴자인지, 임의로 해 둔 것인지 구분이 힘들어서 아예 불가능하도록, 미탈퇴자는 2019-04-30을 탈퇴일로 지정한다.)
우선 임의로 만든 탈퇴일은 새로운 컬럼 'cal_date'로 하고, 먼저 end_date의 값을 그대로 복사해온다.
#cal_date를 end_date로 임의로 넣어두기
cust_join['cal_date'] = cust_join['end_date']
cust_join.head()
end_date 값이 비워져 있는 경우에만, cal_date의 값을 '2019-04-30'으로 한다.
#end_date가 비워진 경우, cal_date엔 '2019-04-30'으로 채운다.
cust_join['cal_date'].fillna(pd.to_datetime('20190430'), inplace=True)그리고 회원기간 컬럼인 'mem_period'를 추가하는데, 이는 cal_date에서 start_date를 빼면 된다.
#회원기간을 계산하는 'mem_period' 컬럼 추가
cust_join['mem_period'] = (cust_join['cal_date'] - cust_join['start_date']) / np.timedelta64(1, 'M') #단위가 '월'이므로 추가
cust_join.head()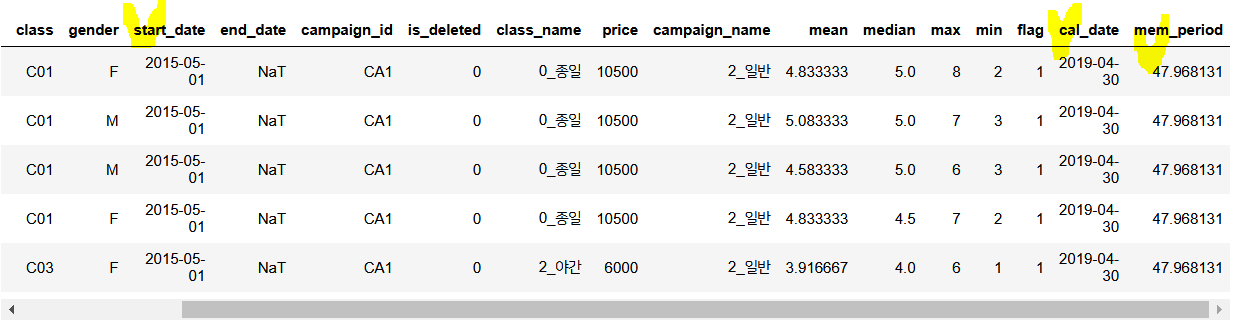
다만 주의할 점이 있다!
위의 코드를 보면 단순히 cal_date에서 start_date를 빼지 않았다. 왜냐하면, datetime 연산 시 기본적으로 'days'를 디폴트로 출력하기 때문이다.
하지만 이 데이터에선 탈퇴일과 시작일 간의 길이가 길기 때문에, 단위가 day(일)인 경우 값이 매우 커지는 문제가 발생하기에 이 단위를 month(월)로 바꿔주어야 한다. 바꿔주는 과정에서 소수점 이하 값이 생긴다.
이를 위해 cal_date에서 start_date를 빼고, 이를 np.timedelta(1, 'M')으로 나누었음에 주의! (Python days to months 바꾸는 방법)
혹은 위의 과정 말고, relativedelta를 이용하면 된다.
## 다른 방법(relativedelta 사용)
from dateutil.relativedelta import relativedelta
cust_join['mem_period'] = 0
for i in range(len(cust_join)):
delta = relativedelta(cust_join.loc[i, 'cal_date'], cust_join.loc[i, 'start_date']) #두 기간의 차이를 계산
cust_join.loc[i, 'mem_period'] = delta.years*12 + delta.months #위의 delta 값을 mem_period에 넣음 (단위: month)
cust_join.head()
위의 코드를 활용하면 아까 datetime을 month로 나눠주었던 것과 같은 결과가 나온다. 하지만 소수점 없이 깔끔하게 나온다.
relativedelta를 활용하면 years와 months 기능도 사용할 수 있으며,
사용하는 방법은 먼저 cal_date에서 start_date의 차이를 계산하여 'delta'라는 변수에 넣고,
mem_period 변수 안에 이 delta 값을 넣어주는데, 여기엔 year와 month 모두 들어 있으므로 단위를 month로 하기 위해선 year엔 12를 곱하고, month는 더해주면 된다.
여기서는 두번째 방법인 relativedelta를 사용하는 것이 mem_period 변수가 더 깔끔하게 나오므로 이 방법을 사용해서 분석을 진행하겠다.
Tech 29. 고객 행동의 각종 통계량을 파악하자.
이제 최종적으로 만들어진 'cust_join' 데이터를 활용해 여러 통계량을 파악해보자!
1. 전체 회원들의 월 평균/중앙/최대/최소 이용 횟수는?
cust_join[['mean', 'median', 'max', 'min']].describe()이는 앞서 이미 우리가 구했던 mean, median, max, min 컬럼으로 통계량을 내면 된다.
앞서 이 컬럼들은 "한 고객당" 월 이용 횟수의 통계량이었다.
이제는 이 값들 전체로 평균을 구하므로, 전체 회원을 대상으로 평균/중앙/최대/최소 이용 횟수의 월 평균 이용횟수가 얼마인지를 구하는 것과 같다.

전체 회원에 대해, 모든 회원에 대해 1인당 월 평균 5.3회, 1인당 월 중위수 5.2회, 1인당 월 최대이용횟수 7.8회, 1인당 월 최소이용횟수 3회이다.
결과적으로 고객 1인당 한달에 약 5회 사용(최소: 3회 ~ 최대: 7.8회)한다는 인사이트를 도출하였다.
2. 전체 고객 대상 flag 현황 (지속적 이용하는 사람(flag = 1)의 비율은?)
round(cust_join.groupby('flag').count()['customer_id'] / cust_join.shape[0] *100,1)
flag가 1이라는 것은 아까전에 1달에 특정 요일에 4번 이상 이용한 적이 있으면 부여되었음.
위의 결과를 확인해보면, 정기적으로 1달에 특정 요일마다 오는 사람이 81%로, 정기적으로 이용하는 사람이 대다수였다.
헬스장에 특정 요일마다 주기적으로 방문하는 사람이 무려 전체의 80%라는 인사이트를 도출하였다.(*물론, 무조건 매달 방문한다는 것은 아니다.)
3. 전체 회원들의 회원 기간의 분포는 어떻게 될까?
import matplotlib.pyplot as plt
plt.hist(cust_join['mem_period'])
plt.show()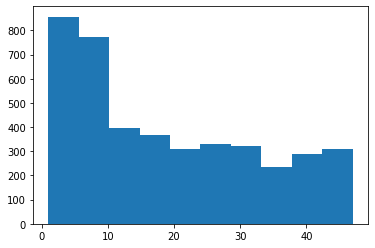
회원 기간 단위가 "달(month)"인데, 가장 많은 건 0~10개월 사이가 많고, 10개월 이상 다니고 있는 회원 수는 비슷비슷하다.
대다수의 회원이 회원 기간 10개월을 넘기지 못한다는 인사이트를 도출하였다.(마의 10개월...)
10개월 넘게 쓸 수 있도록 뭔가 유인책을 생각해보는 것도 좋겠다. 짧은 기간에 고객이 빠져나가는 업계인 듯.
Tech 30. 탈퇴하는 회원과 지속하는 회원의 차이를 파악하자.
그렇다면 탈퇴회원과 지속회원 간에는 어떤 차이가 있는지, 간단한 통계로 알아보자.
우선 탈퇴한 사람은 is_deleted = 1이며 지속회원은 0이다.
#탈퇴여부는 is_deleted=1이면 탈퇴, 0이면 지속
#통계량 살펴보기(탈퇴회원)
cust_join[cust_join['is_deleted'] == 1].describe()
#지속회원
cust_join[cust_join['is_deleted'] == 0].describe()
탈퇴회원은 지속 회원보다 매월 이용횟수 평균, 중앙, 최대, 최솟값 모두 작다. 특히 평균, 중앙값은 1.5배나 차이남(월평균 탈퇴자 월평균 3.8회 / 지속자 월평균 6회 이용)
flag를 보면 탈퇴자는 평균이 0.45, 지속자는 0.98로 1달에 특정 요일마다 매주 방문하는 것이 지속회원은 아주 높다(거의 1에 가까움)
-> 즉, 지속회원은 정기적으로 이용하는 회원이 아주 많다. 탈퇴회원은 절반은 랜덤하게 이용하고 있었다.(매주 방문하는 사람 절반, 아닌 사람 절반)
회원기간의 경우, 탈퇴회원은 평균 8달, 지속회원은 평균 24달(약 2년)을 유지했다.
마지막으로 가공한 데이터를 다음 #4장에서 사용하기 위해 다운로드한다.
#마지막으로, 다음 4장에서 이용하기 위해 cust_join 데이터를 csv로 출력해놓자.
cust_join.to_csv('customer_join.csv', index=False)
오늘 포스팅은 내용이 다소 많았던 거 같은데, 이렇게 직접 인사이트를 도출해보는 것이 중요한 거 같아요! :)
꾸준히 하다보면 분석방법에 대한 감을 익혀서 실무에도 적용할 수 있을 거랍니다.
다음 포스팅에선 이번 장에서 가공한 데이터를 바탕으로, 머신러닝 모델을 적용하는 포스팅으로 찾아뵐게요. 감사합니다.
'Data Science > Analysis Study' 카테고리의 다른 글
| 머신러닝을 활용한 고객 이용 횟수 예측 - 전처리 / 파이썬 데이터 분석 실무 테크닉 100 (4) | 2022.04.06 |
|---|---|
| 고객 유형을 나누기(파이썬 클러스터링, 군집 분석) / 파이썬 데이터 분석 실무 테크닉 100 (6) | 2022.04.06 |
| 파이썬 EDA : 고객의 전체 모습 파악하기 -1편 / 파이썬 데이터 분석 실무 테크닉 100 (3) | 2022.01.17 |
| 파이썬으로 지저분한 데이터 가공하기 -2편 / 파이썬 데이터 분석 실무 테크닉 100 (0) | 2022.01.14 |
| 파이썬으로 지저분한 데이터 가공하기 -1편 / 파이썬 데이터 분석 실무 테크닉 100 (2) | 2022.01.14 |



