
Yours Ever, Data Chronicles
파이썬 EDA : 고객의 전체 모습 파악하기 -1편 / 파이썬 데이터 분석 실무 테크닉 100 본문
파이썬 EDA : 고객의 전체 모습 파악하기 -1편 / 파이썬 데이터 분석 실무 테크닉 100
Everly. 2022. 1. 17. 18:23안녕하세요, Everly입니다 :)
저번 포스팅(파이썬 데이터 분석 #1장, #2장)을 통해, 현장에서 데이터 분석을 어떻게 시작하는지에 대해 기본적인 내용을 공부했습니다. 이번 포스팅부터는 데이터 분석을 본격적으로 시작해 보겠습니다.
데이터 분석 업무를 한다는 것은 결국 '결과를 내기 위한' 것입니다. 여기에는 2가지 측면이 있는데요,
하나는 통계를 사용한 사전 분석으로, EDA라고도 합니다. 데이터를 찬찬히 뜯어보고, 가공하는 데이터 핸들링(data handling)을 하는 과정입니다. 이 과정에서 현재의 상황이 어떤지를 데이터를 통해 자세히 알아볼 수 있죠. 또한 이러한 현황 파악을 통해 어떠한 알고리즘을 적용하면 좋을지도 알 수 있습니다.
나머지 하나는 앞서 한 사전 분석을 토대로, 머신 러닝 알고리즘을 데이터에 적용하여, 미래를 예측하는 것입니다.
이렇게 두 가지 업무는 모두 중요하며, 꼭 필요한 과정입니다. 이러한 데이터 분석의 과정을 통해, 우리는 문제점을 파악하고 더 나은 성과를 위해 최적의 의사결정을 할 수 있도록 도울 수 있습니다. (이것이 데이터 사이언티스트의 역할!)
경우에 따라 머신러닝까지 하지 않고, EDA로 데이터를 가공해 시각화하는 것만으로도 많은 정보를 얻을 수 있습니다.
이번 #3장 포스팅에서는 이러한 분석 업무 중 첫번째, 사전 분석(EDA)을 진행합니다. 그리고 #4장, #5장에서는 머신러닝에 관해 포스팅하겠습니다.
이번 포스팅에서는 "고객의 전체 모습을 파악하는" 사전 분석 과정을 다룬다.
제가 운영하는 스포츠 센터는 트레이닝 붐 덕에 고객 수가 증가해왔습니다. 그런데 최근 1년 동안은 고객 수가 늘지 않는 것 같습니다. 자주 이용하는 고객은 자주 오지만, 가끔 오는 고객은 오지 않는 경우도 있는 것 같습니다.
제가 제대로 데이터를 분석한 적이 없어서, 어떤 고객이 계속 이용하고 있는지조차 모릅니다. 데이터 분석을 하면 뭔가를 알 수 있을까요?
의뢰인은 데이터는 있으나, 분석을 해본 적이 없어 어떠한 고객이 있는지도 모르고, 자주 오는 사람만 오는 것 같다고 어렴풋이 추측만 하고 있다. 이러한 심증을 실질적인 증거로 바꿔주는 것이 바로 데이터 분석이다.
우리는 의뢰인에게서 전달받은 데이터를 통해, 한번 고객들은 어떤 유형이 있는지를 알아보고, 진짜로 이용하는 사람만 이용하는 것인지를 살펴보도록 하자.
이용하는 데이터
- use_log: 센터 이용이력(2018.04~2019.03)
- customer_master: 회원정보(탈퇴 회원 포함, 2019년 3월 말 시점으로 뽑은 데이터)
- class_master: 회원 구분(종일/주간/야간회원)
- campaign_master: 행사 구분(일반/무료/반액할인)
✔Table of Contents
Tech 21. 데이터를 읽어들이자.
import pandas as pd
ul = pd.read_csv('3장/use_log.csv')
cust_m = pd.read_csv('3장/customer_master.csv')
class_m = pd.read_csv('3장/class_master.csv')
camp_m = pd.read_csv('3장/campaign_master.csv')
display(ul.head(), cust_m.head())
먼저 이용이력 데이터(ul)와 회원정보 데이터(cust_m) 이다.
이용이력 데이터는 매우 방대하며 회원이 이용할 때마다 로그가 남는다. 197428개의 데이터가 있다.
그리고 회원정보 데이터는 탈퇴한 회원을 포함한 모든 회원에 대한 정보이며, end_date가 비어 있으면 탈퇴하지 않은 회원이다. (이는 is_deleted값이 0인 것과 같다) 총 4192개의 데이터가 있다.
display(class_m, camp_m)회원구분 데이터(class_m)은 회원권이 무엇인지 종일/주간/야간으로 구분된다.
행사구분 데이터(camp_m)은 입회비가 프로모션이 적용되었는지 무료/반액할인/일반권으로 구분된다.
당연히 주로 볼 데이터는 ul, cust_m가 될 것이며 class_m과 camp_m은 class와 campaign에 대한 join용도로 사용한다.
먼저 고객현황 데이터(cust_m)를 위주로 살펴보자.
Tech 22. 고객현황 데이터를 가공하자(데이터 조인하기)
고객현황 데이터인 cust_m에 class_m과 camp_m 데이터를 결합하여 새로운 데이터 'cust_join'을 만들어보자.
공통 컬럼은 다음과 같다.
- cust_m & class_m : class
- cust_m & camp_m : campaign_id
cust_m을 기준으로 left join한다.
cust_join = pd.merge(cust_m, class_m, on = 'class', how='left')
cust_join = pd.merge(cust_join, camp_m, on = 'campaign_id', how='left')
cust_join.head()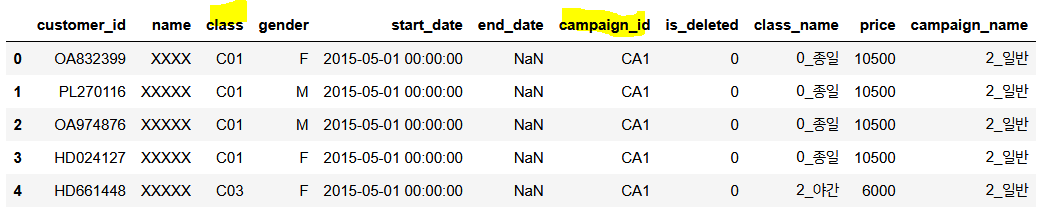
공통컬럼을 기준으로 잘 조인되었는지 확인
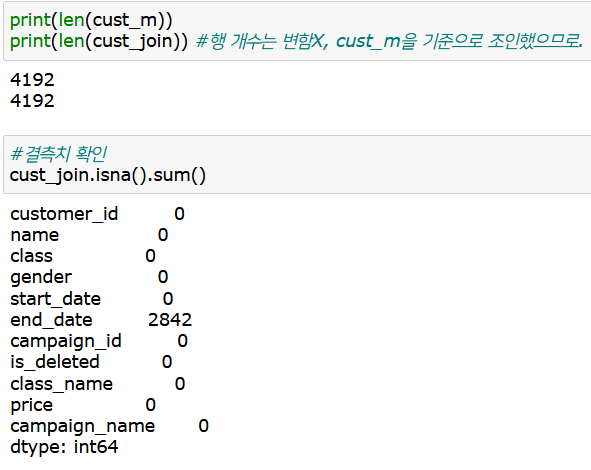
보면 원본인 cust_m과 조인된 새로운 데이터인 cust_join의 행의 수가 같으므로 조인이 잘 되었다.
그리고 결측치를 확인하는 이유는, 조인할때 키가 없거나 조인이 잘못되면 자동으로 결측치가 들어가게 되기 때문이다. 그러므로 조인 후에는 결측치를 확인해야 하는데, 여기선 원래 결측치가 있던 end_date에만 결측치가 있으므로 데이터가 정확히 들어갔음을 알 수 있다.

참고로, cust_join의 고유한 고객id를 확인해보면 전체 행의 개수와 같다. 즉, 이 cust_join 데이터의 각 행에 있는 customer_id는 고유하다. (중복되는 id가 없다.)
Tech 23. 새로 만든 고객 데이터를 집계하자.
이제 만든 고객 데이터인 'cust_join'으로 간단한 데이터 분석을 해보자.
먼저, 무엇을 집계할지를 생각해본다. 무엇이 궁금한가? (궁금한 것이 있는 것도 아주 중요한 과정이다!) 예를 들면..
- 어떤 회원과 어떤 캠페인이 많은가?
- 언제 입회/탈퇴가 많은가?
- 남녀 비율은?
- 탈퇴할 때까지의 평균 기간은 며칠인가?
떠오르는 여러 단순한 질문들에 데이터를 갖고 명확한 답변을 해보자.
변수 타입이 범주형 데이터로 되어 있으면 value_counts() 메서드를 써도 좋지만, groupby 메서드를 사용하는 것이 보다 더 깔끔하게 나오니(자동으로 정렬됨) 이것을 써보자.
#회원 구분 현황
cust_join.groupby('class_name')['customer_id'].count()
회원권은 종일권이 가장 많으며 그 다음이 야간권, 주간권 순이다.
이렇게 count로 groupby를 하게 되면 회원권 종류별 개수를 센다. 전체에서 차지하는 비율로 알고자 한다면
round((cust_join.groupby('class_name')['customer_id'].count() / cust_join.shape[0])*100,1)
이렇게 전체 개수로 나누고, 백분율로 나타내준다. 그럼 회원권 중 종일권이 약 49%로 대다수이며, 야간권 27%, 주간권 24%이다.
#캠페인 구분 현황
round((cust_join.groupby('campaign_name')['customer_id'].count() / cust_join.shape[0])*100,1)
프로모션(캠페인)의 경우 일반 할인혜택 없이 가입한 가입자가 73%, 그 다음이 반액할인(15%), 무료(12%)이다.
#성별 현황
cust_join.groupby('gender')['customer_id'].count()
성별은 남성이 여성보다 좀 더 많다.
#탈퇴자 현황
round((cust_join.groupby('is_deleted')['customer_id'].count() / cust_join.shape[0])*100,1)
탈퇴한 고객으로는 end_date가 비어있는 것, 비어있지 않은걸로 봐도 되지만 여기서는 is_deleted가 1(탈퇴), 0(탈퇴안함) 으로 나눠보는 게 더 편리하므로 이를 알아보았다.
탈퇴 안한 사람이 전체의 68%, 탈퇴한 사람이 32%이다. (전체 회원 중 32%가 탈퇴자라니 꽤 많은 수치인듯)
이렇게 알아보면 뭔가 여러 가지 가설이 떠오를 것이다. 예를 들어 '탈퇴한 사람의 대부분은 캠페인 프로모션을 받은 사람 아닐까? 그래서 프로모션 기간이 끝나서 탈퇴한 것일수도..?' , '성별이 남성일수록 종일권을 더 많이 구매하지 않았을까?', '프로모션을 진행한 기간에 폭발적으로 인원이 많아지지 않았을까?' 같은...
이렇게 제가 만든 것처럼, 궁금한 것들을 만들어보자. 그리고 이를 데이터로 확인해보다 보면 좋은 인사이트가 발견될지도 모른다. 또한 책에서는, 직접 집계하는 것뿐 아니라 현장 사람들에게 질문을 많이 하는 것도 중요하다고 한다.
Tech 24. 최신 고객 데이터를 집계하자.
데이터의 크기가 클 때에는 일부 데이터만 뽑아서 현황을 파악하는 방법이 있다. 이 데이터는 크기가 매우 크진 않지만, 시험 삼아 일부 데이터만 뽑아 전체 현황을 살펴보자.
월별 집계를 하려고 하므로, 데이터상 가장 최근(고객현황 데이터를 뽑은 시점)인 2019년 3월의 데이터만 뽑아 현황을 파악한다.
2019년 3월 당시 잘 이용하고 있는 사람만 뽑으려면, 이 기간에 탈퇴를 하면 안 되므로
1)end_date가 2019.03.31 이후이거나 2)탈퇴를 한 적이 없어야 한다.(NaN 값)
cust_join['end_date'] = pd.to_datetime(cust_join['end_date'])
cust_new = cust_join[(cust_join['end_date'] >= pd.to_datetime("20190331")) | (cust_join['end_date'].isnull())]
cust_new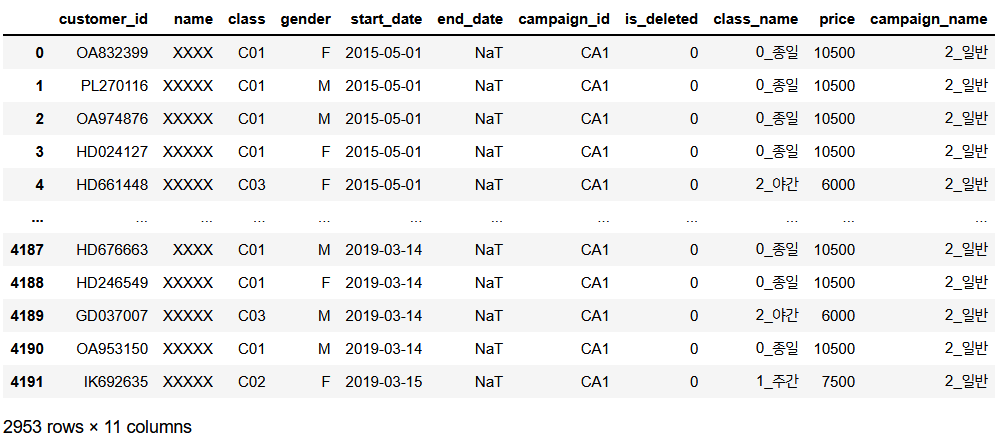
두가지 조건의 합집합이므로 '|' 기호를 써서 조건을 묶어 불린 인덱싱 해준다.
전체 4천여개 데이터에서, 2019년 3월 기준 잘 다니고 있는 고객들의 데이터 약 3천개가 뽑혔다.

다음과 같이 end_date 의 값이 위처럼 딱 2개만 나온다면 잘 한 것이다.
이제는 앞서 Tech 23번에서 했던 것과 같은 코드를 사용하여, 전체 데이터에서의 현황과 2019년 3월 기준 잘 다니고 있는 고객들의 현황이 어떠한 차이점이 있는지를 살펴보자.
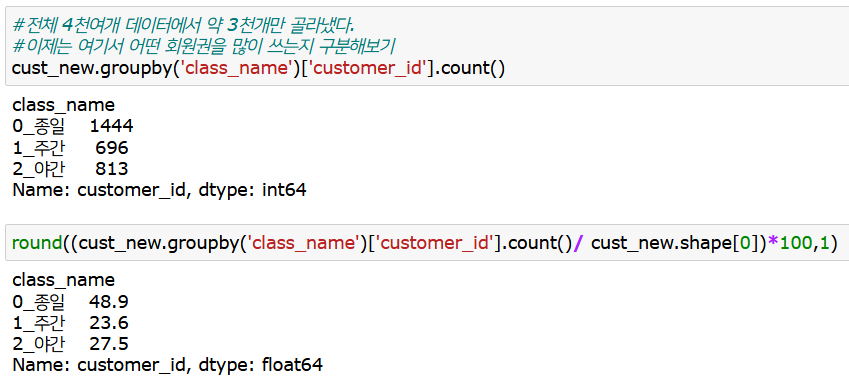
먼저 회원권은, 종일이 49% > 야간 > 주간권 순이다. 이는 전체 현황과 크게 다르진 않아 보인다.

다음은 어떤 캠페인 프로모션으로 가입했는지인데, 일반회원이 무려 81%이다. 할인을 받아 가입한 사람은 약 20% 정도이다.

성별도 전체 데이터와 큰 차이가 나지 않는다. 남성비율이 좀 더 높다.
이를 정리해보면,
새롭게 뽑은 데이터가 전체 데이터와 다른 점은, 2019년 3월 기준 잘 활동하고 있는 회원만 뽑은 데이터라는 점이다.
회원권과 성별 변수에 대해서는 전체 데이터(cust_join)에 대해 뽑았던 것과 비율이 크게 다르진 않았다.
=> 특정 회원권이나 성별이 탈퇴한 것이 아님!
하지만 캠페인 변수에선 비율이 좀 달랐다. 전체에서는 일반 가입이 70%였는데, 이 데이터에선 일반 가입이 80%이다.
=> 즉, 입회 캠페인은 회원 비율 변화에 영향을 미친다!
이렇게 해석할 수 있다.
지속적으로 이용하고 있는 회원 데이터에서 일반 가입이 프로모션 가입보다 비율이 훨씬 높은 것으로 보아, '프로모션 가입자는 일반 가입자보다 지속할 가능성이 낮다' 라는 가설을 세우고 검증해보는 것도 좋을 듯하다.
여기까지 고객 현황 데이터를 가지고 간단하게 현황을 알아보았다. 글이 길어지는 관계로 나머지 부분은 다음 포스팅에서 알아보도록 하자.
다음 포스팅에선 이 포스팅에서 다루지 않았던 이용이력(ul) 데이터를 가공하여 새로운 인사이트를 알아보자.
'Data Science > Analysis Study' 카테고리의 다른 글
| 고객 유형을 나누기(파이썬 클러스터링, 군집 분석) / 파이썬 데이터 분석 실무 테크닉 100 (6) | 2022.04.06 |
|---|---|
| 파이썬 EDA : 고객의 전체 모습 파악하기 -2편 / 파이썬 데이터 분석 실무 테크닉 100 (8) | 2022.01.17 |
| 파이썬으로 지저분한 데이터 가공하기 -2편 / 파이썬 데이터 분석 실무 테크닉 100 (0) | 2022.01.14 |
| 파이썬으로 지저분한 데이터 가공하기 -1편 / 파이썬 데이터 분석 실무 테크닉 100 (2) | 2022.01.14 |
| 쇼핑몰 데이터 주문 수 분석하기 (월별, 상품별) -2편 / 파이썬 데이터 분석 실무 테크닉 100 (6) | 2022.01.12 |



