

Yours Ever, Data Chronicles
파이썬으로 지저분한 데이터 가공하기 -2편 / 파이썬 데이터 분석 실무 테크닉 100 본문
파이썬으로 지저분한 데이터 가공하기 -2편 / 파이썬 데이터 분석 실무 테크닉 100
Everly. 2022. 1. 14. 16:34저번 포스팅에서 이어서 '지저분한 데이터 가공하기'의 남은 부분을 공부해보자.
배우는 부분: 데이터 전처리 / 데이터 가공 / 엑셀 숫자 날짜로 변환 / 문자열 전처리
✔Table of Contents
Tech 16. 고객 이름 오류 수정하기
이번에는 'ko'라고 하는 데이터를 살펴보자. 이는 엑셀(xlsx) 데이터로, 많은 오류가 있다.
ko.head()
보다시피 고객이름은 '김 현성'처럼 공백이 들어가 있으며,
등록일은 날짜타입으로 된 것도 있으나 숫자형태로 되어 있기도 하다. 이는 엑셀에서의 서식을 날짜가 아닌 다른 방식으로 지정했기 때문이다.
우선 고객 이름부터 수정해보도록 하자.
고객이름에는 공백이 두 번(" ") 들어있는 것도 있고, 한 번(" ") 들어있는 것도 있는데, 이러한 공백들을 모두 없애주자. 앞선 포스팅에서 한 것처럼 문자열 전처리이므로 해당 열을 str으로 바꾼 후 replace로 공백을 지운다.
ko['고객이름'] = ko['고객이름'].str.replace(" ","")
ko['고객이름'] = ko['고객이름'].str.replace(" ",'')
ko.head()
위와 같이 전처리가 잘 된 것을 확인할 수 있다.
Tech 17. 엑셀 날짜 오류 수정하기
이번에는 '등록일' 열에 있는 42782같은 정체불명의 숫자를 날짜로 인식하도록 해보자.
먼저, ko 데이터의 열별 데이터 타입은 무엇일까?

dtypes로 확인해보면 '등록일' 열은 object로, 문자열로 되어 있다. 하지만 42782같은 숫자도 있는데, 얘네도 문자로 저장된 걸까..? '등록일'열만 떼어 숫자가 있는지 isdigit()으로 확인해본다.
ko['등록일'].astype('str').str.isdigit()
여기서 주의할 점은 object는 문자열과 같은 역할이긴 하나, 엄밀히 말하면 str(string)과는 조금 달라서 반드시 astype으로 문자열을 'str'로 바꾼 후에 알아봐야 한다는 점이다.
아무튼 isdigit으로 확인해본 결과, 몇몇 행은 True로 나온다. 즉, 42782 같은 숫자가 들어있는 것은 숫자로 인식된다는 것이다. 날짜로 잘 입력이 된 나머지 데이터들은 숫자가 아니기에 False로 나온다.

이렇게 잘못 입력된 것들의 개수는 22개가 있다.
그럼 이렇게 엑셀 서식이 잘못되어 날짜인데 숫자로 들어가 있는 데이터는 당연하게도 이 상태에서 분석은 불가능하다. 그렇다면 어떻게 변형해야 할까??
→ 바로 숫자로 들어가 있는 데이터를 float 타입으로 변형한 뒤, 형식을 D(day)로 바꾸고 1900-01-01 날짜를 더해주면 된다!
#먼저 숫자이면 True, 아니면 False인 불린 변수를 만든다.
is_serial = ko['등록일'].astype('str').str.isdigit()
#위의 변수로 불린 인덱싱을 하여, 날짜인데 숫자로 잘못 들어간 애들을 날짜 단위로 변환한다.
pd.to_timedelta(ko.loc[is_serial, '등록일'].astype('float')-2, unit='D')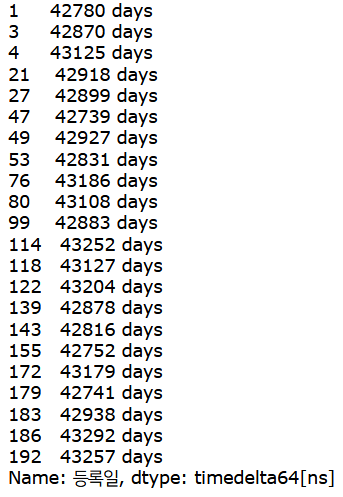
여기서도 불린 인덱싱을 활용한다.
숫자이면 True, 아니면 False를 뽑는 불린 변수(is_serial)을 만들고,
ko 데이터에서 is_serial이 True인 '등록일'을 뽑아 float로 변형 -> D(day) 단위로 변경한다. (여기서 2를 왜 빼는지는 이따가 설명하겠다.)
위의 과정을 실행하면, 숫자였던 데이터가-> 몇일인지 days 단위로 바뀌었음을 확인해볼 수 있다!
그리고 여기서 "1900-01-01" 날짜를 더해주면 완료!
from_serial = pd.to_timedelta(ko.loc[is_serial, '등록일'].astype('float')-2, unit='D') + pd.to_datetime("1900/01/01")
from_serial
이제는 is_serial 불린값이 False인 것도 datetime 형태로 변환한 후, 만들어진 두개 변수를 조인하면 전처리 끝
#앞서 숫자로 판명되지 않은 것(False)도 datetime으로 바꿔주기
from_string = pd.to_datetime(ko.loc[~is_serial,'등록일'])
#두 변수(from_serial, from_string) 조인하여 데이터프레임에 넣기
ko['등록일'] = pd.concat([from_serial, from_string])
ko.head()

이제 dtypes를 출력했을 때, 등록일의 데이터 타입은 datetime으로 잘 바뀐 것을 확인해볼 수 있다!
※잠깐! 왜 아까 엑셀 숫자를 날짜로 바꿀 때, float타입으로 변환 후 2를 빼줬을까?
그 이유는 2를 빼지 않고 변환 시, 파이썬에선 이틀 어긋나게 변환되기 때문!
※ 왜 이런 일이 발생하는가?
1. 엑셀 데이터는 0이 아닌 1부터 시작 > 파이썬은 0부터 시작
2. 1900년은 평년이나, 엑셀에선 1900-02-09일을 유효한 날짜로 계산함(엑셀의 버그) > 파이썬에선 당연히 카운트되지 않음.
이 때문에 엑셀의 숫자 형식은 파이썬으로 곧바로 변환 시 이틀이 차이나기 때문에, 꼭 2를 빼주어야 함!
전처리가 잘 되었는지를 알아보기 위해, '등록일' 컬럼에 이제 숫자가 있는지를 검산하자.
ko['등록일'].astype('str').str.isdigit().sum()
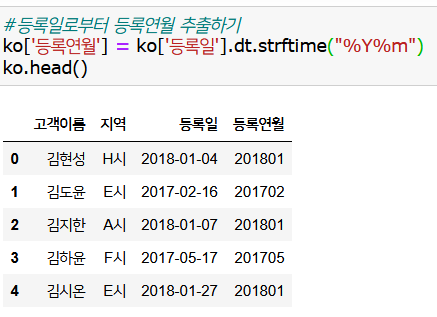
잘 전처리되었으며, 마지막으로 '등록일'에서 연월만 뺀 '등록연월'을 만들고 마무리
Tech 18. 고객이름을 key로 하여, 두 데이터를 조인하자.
이제 'uriage'와 'ko' 데이터의 전처리 작업이 완료되었다.
지금부터는 두 데이터에 공통적으로 있는 열인 '고객이름'을 기준으로 두 데이터를 조인한다.

여기서 구매내역이 있는 매출 데이터를 만들 것이기 때문에, uriage를 기준으로 left join시킨다.
join_data = pd.merge(uriage, ko, left_on = 'customer_name', right_on = '고객이름', how='left')
join_data
Tech 19. 정제된 데이터를 저장하자.
이렇게 만들어진 최종 데이터인 'join_data'는 앞으로 데이터 분석 때마다 계속 활용할 데이터이다.
따로 저장해두지 않고 지나간다면, 앞으로 분석을 할 때마다 앞의 모든 과정을 처음부터 다시 해주어야 하기 때문에, 이를 막기 위해 따로 파일로 저장해두자.
저장하는 것은 아주 쉽다. pd.to_csv로 저장하면 끝!
다만, join_data에서 원하는 컬럼만 뽑아오기 위해 데이터 컬럼 순서를 약간 바꿔 가져온다.

이렇게 다운로드한 후, 'dump_data.csv' 파일이 어디에 있는지를 꼭 확인하자.
나의 경우, 주피터 파일이 저장된 경로에 저장했기 때문에 여기에 저장되어 있음을 확인할 수 있다.

Tech 20. 데이터를 집계하자. (데이터 분석)
우리의 목표였던 지저분한 데이터를 전처리하는 것은 끝났다. 이제부터는 데이터 분석의 시간!
마지막으로 정말 간단하게 데이터 분석을 하고 이 포스팅을 마치겠다.
위에서 저장했던 데이터인 'dump_data'를 불러온다.
import pandas as pd
data = pd.read_csv('dump_data.csv')
data.head()
월별, 상품별 팔린 개수를 집계한다. (저번 포스팅에서 전처리를 안하고 했던 결과와 차이가 난다)
data.pivot_table(index = 'purchase_ym', columns='item_name', aggfunc = 'size', fill_value = 0)
월별, 상품별 매출액을 집계
data.pivot_table(index = 'purchase_ym', columns = 'item_name', values = 'item_price', aggfunc='sum', fill_value = 0)
월별, 고객별 구매횟수 집계
data.pivot_table(index = 'purchase_ym', columns = '고객이름', aggfunc = 'size', fill_value = 0)
월별, 지역별 구매횟수 집계
data.pivot_table(index = 'purchase_ym', columns = '지역' , aggfunc = 'size' , fill_value = 0)
마지막으로, 우리가 전처리를 끝내고 만든 데이터인 dump_data는 uriage(매출정보)를 기준으로 ko(고객정보)를 붙였기 때문에 물건을 실제로 구매한 사람의 데이터만 나온다.
그렇다면, 가입은 했으나 구매를 해본 적 없는 사람은 어떻게 구하면 될까? 바로 반대로 ko를 기준으로 uriage를 붙인 후, uriage에 대한 정보가 결측값(NaN)으로 나오는 부분을 뽑으면 되겠지!
away = pd.merge(uriage, ko, left_on = 'customer_name', right_on = '고객이름', how='right')
away
이번엔 위처럼 right join을 한다. 마지막 행처럼 uriage(매출정보)에 해당하는 내역이 NaN으로 나온다면, 가입은 했지만 구매는 안 한 고객이다.
이러한 사람은 누구인지, 불린 인덱싱을 통해 뽑아보자. 구매를 안 했다면 purchase_date 열이 비어 있을 것이므로, away['purchase_date'].isnull() 이 T/F인 불린 값임을 이용한다.
away[away['purchase_date'].isnull()]
이렇게 딱 1명밖에 없었다.
만일 이렇게 가입은 했지만 구매는 안 한 경우가 많다면, 전체 몇 명이 있는지 뒤에 sum만 붙여주면 된다.

이로써 1장, 2장에선 데이터 분석에 있어 가장 중요한 데이터 가공(전처리) 를 배웠다.
이러한 전처리는 정확성 이 핵심!! 소홀히 하면 나중에 큰코다칠 수 있으니 꼭 정확하게! 그리고 검산도 반드시 해봐야 한다.
다음 포스팅인 3장부터는 좀 더 본격적인 데이터 분석에 대해 알아보도록 하자.
'Data Science > Analysis Study' 카테고리의 다른 글
| 파이썬 EDA : 고객의 전체 모습 파악하기 -2편 / 파이썬 데이터 분석 실무 테크닉 100 (8) | 2022.01.17 |
|---|---|
| 파이썬 EDA : 고객의 전체 모습 파악하기 -1편 / 파이썬 데이터 분석 실무 테크닉 100 (3) | 2022.01.17 |
| 파이썬으로 지저분한 데이터 가공하기 -1편 / 파이썬 데이터 분석 실무 테크닉 100 (2) | 2022.01.14 |
| 쇼핑몰 데이터 주문 수 분석하기 (월별, 상품별) -2편 / 파이썬 데이터 분석 실무 테크닉 100 (6) | 2022.01.12 |
| 쇼핑몰 데이터 주문 수 분석하기 (월별, 상품별) -1편 / 파이썬 데이터 분석 실무 테크닉 100 (1) | 2022.01.12 |



