
Yours Ever, Data Chronicles
[시각화] 파이썬 이중 Y축 그래프 그리기 (ax.twinx) 본문
파이썬 그래프를 그릴 때, 한 그래프에 더 많은 정보를 담고자 한다면 이중 축을 활용한다.
예를 들어 밑의 예시처럼, (좌측) 특정 변수의 countplot 및 비율만 그릴 수도 있겠지만
(우측) 오른쪽에 이중 축을 하나 더 만들어 또다른 변수의 값이 1인 비율도 나타낼 수 있다.

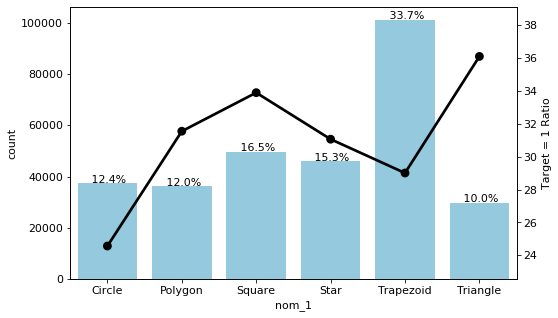
이렇게 이중 축을 만들고자 할 때, seaborn의 ax.twinx() 를 활용하는 방법을 알아보자.
NOTE: 코드는 저의 깃허브에서 내려받을 수 있습니다!
먼저, 좌측 그래프는 앞의 포스팅에서 이미 그렸다.
이번 포스팅에서는 앞에서 그린 비율 countplot에 하나의 이중축을 더 만들어볼 것이다. 이중축은 'nom_1' 변수의 각 고유값들이 target = 1로 갖고 있는 비율을 나타내보자!
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
df = pd.read_csv('train.csv', index_col = 'id')
df.head()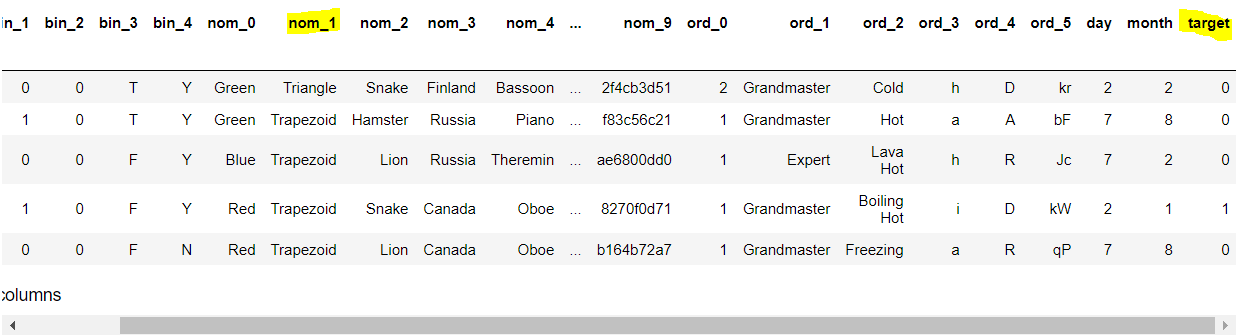
df 데이터의 'nom_1' 과 'target' 변수를 활용할 것이며 둘 다 범주형 데이터이다.
nom_1의 각 고유값들이 target 값 0, 1을 몇 %나 갖고 있는지를 알아보기 위해 판다스의 교차표(crosstab,크로스탭)을 구한다.
참고로 교차분석표가 무엇인지 궁금하다면 이 포스팅에서 자세히 설명하였다 :)
pd.crosstab(df['nom_1'], df['target'], normalize = 'index')*100
예를 들어 'nom_1'의 고유값 중 'Circle'은 target = 0을 75%, target = 1을 25% 갖고 있음을 알 수 있다.
여기서는 target = 1인 비율만 궁금하므로, 위의 크로스탭에서 target = 1만 활용할 것이다.
ct = pd.crosstab(df['nom_1'], df['target'], normalize = 'index')*100
print(ct.index)
print(ct[1])
이제 이중축을 생성하고 크로스탭 ct의 값으로 pointplot을 그려보자.
plt.figure(figsize = (8, 5))
ax = sns.countplot(x = 'nom_1', data = df, color = 'skyblue')
for patch in ax.patches:
ax.text(x = patch.get_x() + patch.get_width()/2,
y = patch.get_height() + len(df)*0.001,
s = f'{(patch.get_height()/len(df))*100: 1.1f}%',
ha = 'center')
#---------------- 이중 축 생성
ax2 = ax.twinx()
ct = pd.crosstab(df['nom_1'], df['target'], normalize = 'index')*100
ax2 = sns.pointplot(x = ct.index, y = ct[1], ax = ax2)
ax2.set_ylabel('Target = 1 Ratio')
plt.rc('font', size = 11)
plt.show()
주석으로 '이중 축 생성'으로 써놓은 부분의 코드를 보면 된다.
먼저 ax2 = ax.twinx()를 활용해 새로운 이중 축 ax2를 만들었다. 이러한 twinx 메서드는 x축은 공유하고 y축은 공유하지 않는, 새로운 이중 Y축을 만든다.
그리고 ax2에 pointplot을 그렸다. x에는 ct의 index를, y에는 ct의 비율값을 넣고 축을 ax2로 지정하였다.
엇! 잘 그린 줄 알았는데 뭔가 이상하다. 혹시 눈치챘는가?
원래 이중축을 그리기 전에 countplot에서 가장 큰 비율 33.7%를 차지하는 값은 Polygon이 아니라 Trapezoid였다. 근데 왜 Polygon으로 설정되어 있는 것일까?
그 이유는 크로스탭의 index 순서에 맞춰서 그래프가 그려지기 때문이다.
즉, 첫번째 축(ax)에 그려진 countplot에서 고유값들의 순서와, 두번째 축(ax2)에 그려진 pointplot의 고유값들의 순서가 일치하지 않는다!!
이런 경우를 방지하기 위해 ax와 ax2 모두 order 옵션으로 순서를 지정해주자!
## order 맞춰주기
plt.figure(figsize = (8, 5))
ax = sns.countplot(x = 'nom_1', data = df, color = 'skyblue', order = ct.index.values)
for patch in ax.patches:
# 2개의 patch 값을 가짐
ax.text(x = patch.get_x() + patch.get_width()/2,
y = patch.get_height() + len(df)*0.001,
s = f'{(patch.get_height()/len(df))*100: 1.1f}%',
ha = 'center')
#---------------- 이중 축 생성
ax2 = ax.twinx()
ct = pd.crosstab(df['nom_1'], df['target'], normalize = 'index')*100
ax2 = sns.pointplot(x = ct.index, y = ct[1].values, ax = ax2, order = ct.index.values)
ax2.set_ylabel('Target = 1 Ratio')
plt.rc('font', size = 11)
plt.show()
ax의 countplot과 ax2의 pointplot 모두 order 옵션으로 크로스탭의 index 값을 순서로 지정해주었다. 이제는 제대로 그려졌다!
마지막으로 그래프를 꾸미기 위해 pointplot의 색상을 까만색으로, 그리고 이중 Y축의 범위(limit)를 좀 더 늘려보았다.
# pointplot 색상 및 y축 수정
## order 맞춰주기
plt.figure(figsize = (8, 5))
ax = sns.countplot(x = 'nom_1', data = df, color = 'skyblue', order = ct.index.values)
for patch in ax.patches:
# 2개의 patch 값을 가짐
ax.text(x = patch.get_x() + patch.get_width()/2,
y = patch.get_height() + len(df)*0.001,
s = f'{(patch.get_height()/len(df))*100: 1.1f}%',
ha = 'center')
#---------------- 이중 축 생성
ax2 = ax.twinx()
ct = pd.crosstab(df['nom_1'], df['target'], normalize = 'index')*100
ax2 = sns.pointplot(x = ct.index, y = ct[1].values, ax = ax2, order = ct.index.values, color = 'k')
ax2.set_ylim(ct[1].min() - 2, ct[1].max() + 3)
ax2.set_ylabel('Target = 1 Ratio')
plt.rc('font', size = 11)
plt.show()
완성!
'Skillset > Python' 카테고리의 다른 글
| [pandas] 순서가 있는 범주형 데이터에 순서 지정하기 - CategoricalDtype (0) | 2022.07.11 |
|---|---|
| [pandas] 범주형 데이터 2개를 비교하는 교차분석표(crosstab, 크로스탭) 알아보기 (0) | 2022.07.10 |
| [시각화] 파이썬 그래프 위에 글자 쓰기 (ax.patches, ax.text) (0) | 2022.07.09 |
| python sample 함수 사용법과 예제 (0) | 2022.07.04 |
| [pandas] Series & DataFrame에서 자주 사용하는 유용한 메서드 (2) (0) | 2022.06.27 |



