
Yours Ever, Data Chronicles
파이썬 자연어 처리(NLP) - 텍스트 데이터 전처리 / 파이썬 데이터 분석 실무 테크닉 100 본문
파이썬 자연어 처리(NLP) - 텍스트 데이터 전처리 / 파이썬 데이터 분석 실무 테크닉 100
Everly. 2022. 5. 16. 19:43안녕하세요~ Everly입니다 😀
오늘부터는 [파이썬 데이터 분석 실무 테크닉 100] 책의 마지막 10장인 '자연어 처리' 부분 포스팅을 업로드합니다.
이 자연어 처리(NLP; Natural Language Processing) 기술은 텍스트(text) 데이터를 분석하는 것으로, 비정형 데이터를 분석하는 기술이라고 볼 수 있겠죠.
예를 들어 고객에게 설문조사를 실시하고, 여기서 필요한 정보만 뽑아낸다고 해봅시다. 설문조사를 한 고객 수가 적으면 일일이 확인해도 되겠지만, 이게 몇 천, 몇 만 명에게 했다고 한다면 사람의 눈으로 파악하기 힘들겠죠.
그리고 어차피 우리가 궁금한 것은 사람들이 공통적으로 말하고 있는 장점이나 단점 정도만 보면 될 테니까요!
이럴 때 사람이 아니라 NLP를 활용한 데이터 분석을 통해 이를 해결할 수 있습니다.
이런 예시 말고도 다양한 분야에서 이미 자연어 처리 기술을 활용하고 있어요.
또다른 예시로 위의 뉴시스 뉴스기사처럼, 뉴스기사 원문으로부터 중요한 문장만 뽑아 요약하는 AI를 만들어 볼 수도 있죠. 아님 문장을 뽑지 않고 직접 AI 모델이 요약된 한 문장을 만들어내도록 할 수도 있답니다!
(사실 저도 예전에 요런 문장 요약 AI를 만든 적이 있었는데요, 관련해서 포스팅할 예정입니다 😉)
[고객의 소리] 우리 회사는 오랫동안 이 도시에서 부동산업을 경영했습니다. 덕분에 정부 기관과의 유대가 깊어서, 부동산 업자의 관점에서 도시 건설 제안을 의뢰받는 경우가 있습니다.
그래서 우리 회사와 관계있는 고객과 동업자에게 협조를 받아 설문조사를 했습니다. 예상보다 많은 사람이 해주셔서 전부 눈으로 훑어보기에 어려운 상황입니다.
조금만 읽어봐도 유익한 정보가 많아 AI를 사용해 분석했으면 합니다. 이런 게 가능할까요? 가능하다면 알기 쉽게 보고서도 작성해주시면 감사하겠습니다.
먼저 의뢰 내용은 "설문조사 결과로부터 의미 있는 정보를 뽑아달라" 는 것입니다.
그래서 이번 장에선 설문조사 데이터(survey.csv)로부터 어떻게 필요한 정보만을 추출할 수 있는지 방법을 배울 것입니다. 텍스트 데이터를 전처리하고, 형태소 분석 및 코사인 유사도를 이용해 의미 있는 정보를 뽑아봅시다.
✔Table of Contents
Tech 91. 데이터를 불러오자
데이터는 2019년 1월부터 4월까지 고객만족도 설문조사 데이터입니다.
import pandas as pd
sur = pd.read_csv('10장/survey.csv')
print(sur.shape)
display(sur.head())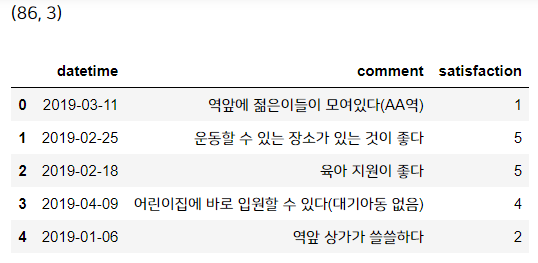
#결측치 확인
sur.isna().sum()
데이터는 비교적 간단한 데이터입니다. 고객이 남긴 의견과 날짜, 만족도 점수가 표시되어 있습니다.
보통은 설문조사에서 의견(comment)은 선택사항이므로 비어있는 경우가 많습니다. 그런데 이 데이터의 고객님들은 잘 남겨주셨네요! 그래서 2개만 결측치가 존재합니다.
2개 정도는 지워도 상관없으므로 제거합니다.
sur = sur.dropna(how='any')
sur.isna().sum()
Tech 92. 불필요한 문자를 제거하자(정규 표현식)
사람마다 언어를 쓰는 방식이 다릅니다. 대표적인 것이 공백인데요. 어떤 문장을 쓸 때
"나는 바나나를 먹었다." 처럼 공백 1개를 쓰는 사람도 있지만,
"나는바나나를먹었다." 라든가, "나는 바나나를 먹었다." 이렇게 쓰는 사람도 있죠.
이렇게 불필요한 문자(특히 특수문자)를 지워서 표준적인 comment로 바꿔주겠습니다. 이는 정규 표현식을 이용하면 간단한 코드로 구현할 수 있습니다.
※ 정규표현식(Regular Expression) 이란?
문자열을 처리하는 방법 중 하나로 특정한 조건의 문자를 검색하거나 치환하는 과정을 매우 간편하게 처리할 수 있는 수단이다.
sur.head()
위의 sur 데이터에서 comment 컬럼에 있는 'AA역' 의 AA를 지워봅시다.
# 'AA역'에서 AA를 지워보자.
sur['comment'] = sur['comment'].str.replace('AA','')
sur.head()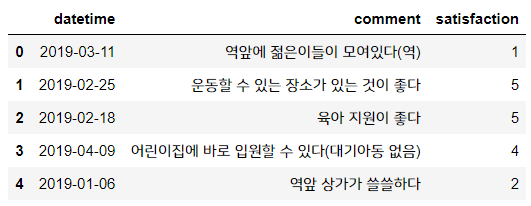
0번째 인덱스를 보면 AA가 사라져 그냥 '역' 이라고만 나온 것을 알 수 있죠?
이번엔 정규표현식을 활용합니다. (역) 이라거나 (대기아동 없음) 처럼 괄호를 쓴 의견이 몇개 보이는데요,
보통 이렇게 괄호가 있는 경우, 괄호 및 괄호 안의 내용을 제거하는 전처리를 진행합니다.
#( ) 괄호 안에 1문자 이상 있으면 제거
sur['comment'] = sur['comment'].str.replace('\(.+?\)', '')
sur.head()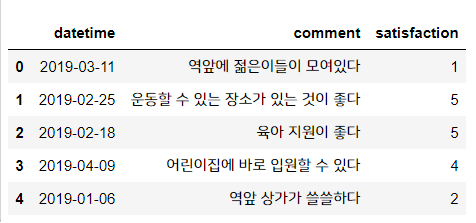
이렇게 위의 정규표현식을 사용하면 괄호 안에 1문자 이상 있으면 제거합니다. 결과를 보면 괄호와 괄호 안 문자가 모두 지워졌죠?
*참고로 백슬래시 표시는 \를 입력하면 됩니다.
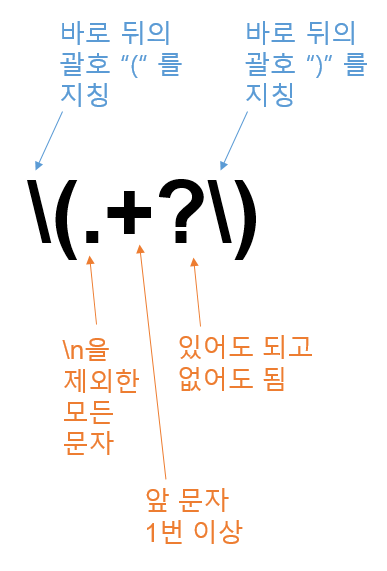
여기서 정규표현식의 뜻은 위와 같기 때문에, 이 식이 뜻하는 것이 '한 개 문자 이상' 입니다. (더 자세한 내용이 궁금하시다면 관련 서적을 참고하시길 추천드려요! [Jump to Python] 책에도 잘 나와 있습니다!)
Tech 93. 글자수를 히스토그램으로 나타내자
이번에는 각 의견(comment 열)의 문자 수를 세어봅시다. 여기는 장문도 있고, 단문도 있는데요. 어떤 형태가 가장 많을까요?
#새로운 열 'length' 생성
sur['length'] = sur['comment'].str.len()
sur.head()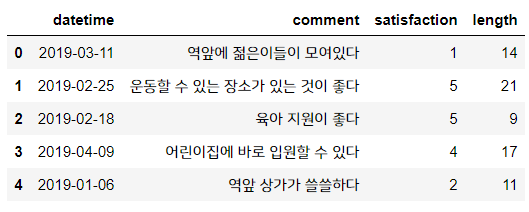
여기선 string에 쓸 수 있는 len() 메서드를 사용하면 편리하게 글자수를 셀 수 있습니다.
이렇게만 보지 말고, 시각화를 해서 글자수 현황을 알아봅시다.
#이제 length 열을 히스토그램으로!
import matplotlib.pyplot as plt
%matplotlib inline
plt.hist(sur['length'])
plt.show()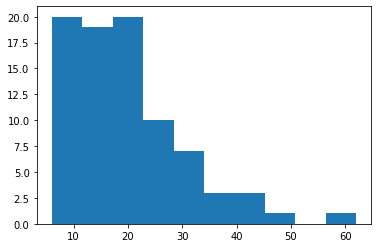
결과를 보면 10자~20자인 comment가 가장 많네요. 즉, 비교적 간단하게 단문으로 쓴 의견이 대다수입니다.
포스팅이 길어진 관계로, 다음 포스팅에선 주어진 텍스트 데이터를 활용해 형태소 분석을 하는 방법을 알아봅니다. :)
'Data Science > Analysis Study' 카테고리의 다른 글
| 파이썬 자연어 처리(NLP) - 문장 수치화하기(One-hot Encoding) / 파이썬 데이터 분석 실무 테크닉 100 (1) | 2022.05.18 |
|---|---|
| 파이썬 자연어 처리(NLP) - konlpy를 활용한 형태소 분석 / 파이썬 데이터 분석 실무 테크닉 100 (0) | 2022.05.17 |
| Python OpenCV (5) - HOG 노이즈 제거하기 (이동평균 이용) (0) | 2022.05.14 |
| Python OpenCV (4) - 동영상에서 사람 얼굴 인식하기, 타임랩스 만들기 (0) | 2022.05.14 |
| Python OpenCV (3) - 이미지에서 사람 얼굴 & 방향 인식하기 (python dlib, 안면 인식 기술) (1) | 2022.05.13 |



