
Yours Ever, Data Chronicles
[시각화] 파이썬 EDA에 꼭 필요한 시각화 그래프 (2) 범주형 데이터 본문
저번 포스팅에 이어 범주형 데이터를 시각화할 때 주로 사용되는 그래프를 정리한다.
✔Table of Contents
3. 범주형 데이터 시각화
저번 포스팅과 마찬가지로 tips 데이터셋을 사용하였다.
tips.head(3)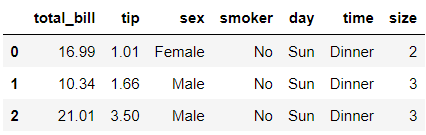
3-1. 범주형 변수 1개 시각화
- 카운트플롯: sns.countplot()
- x: category / y: 각 category별 개수
- 파이 그래프: pie(x, labels)
- x: category별 비율
1) 카운트플롯(countplot): category별 개수 확인
주로 범주형 변수의 분포를 파악할 때 사용한다.
형태는 sns.countplot(x or y, data)
예를 들어, day 변수에 대해 어떤 값을 몇 개나 갖고 있는지를 살펴보자.
sns.countplot(x = 'day', data = tips)
그래프 bar의 위치를 거꾸로 하고 싶다면 x를 y로 바꿔준다.
# bar의 위치 반대로
sns.countplot(y = 'day', data = tips)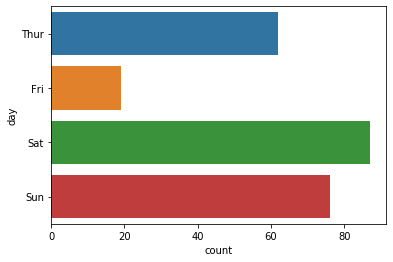
2) 파이 그래프: 범주형 데이터의 비율 구하기
Pie chart는 비율값과 이에 해당하는 레이블(label) 값이 주어지면 파이 모양으로 그려지는 형태이다.
형식은 plt.pie(x, labels, autopct)
- x: 비율 (리스트로 받음)
- labels: 범주형 데이터의 레이블 (리스트로 받음)
- autopct: 비율을 숫자로 표현 시 형식 설정
예를 들어 tips 데이터에서 남녀 비율을 구한다고 하자.
먼저 비율과 레이블 값을 리스트로 만들어야 한다.
# 여성, 남성 비율을 구해보자.
pd.DataFrame(tips['sex'].value_counts()/tips['sex'].count())
위 데이터프레임을 가공하여 비율과 레이블 리스트로 뽑아낸다.
new = pd.DataFrame(tips['sex'].value_counts()/tips['sex'].count())
new.reset_index(inplace = True)
new
파이 그래프를 그리면,
# 위 리스트를 갖고 파이 그래프를 그리기
plt.pie(x = list(new['sex']),
labels = list(new['index']),
autopct = '%.2f%%')
plt.show()
참고로 autopct의 형식은 소수점 2자리수까지 '%'를 붙여 반환한다는 의미이다.
만일 소수점 한자리수까지 반환하고자 한다면 '%.1f%%'로 쓰면 된다.
3-2. 범주형 변수 2개 이상 시각화(변수 간 관계 확인)
범주형 변수와 수치형 변수를 모두 input으로 받아 그래프로 그린다.
- 막대그래프: sns.barplot()
- x: category / y: numerical 평균
- 포인트플롯: sns.pointplot()
- x: category / y: numerical 평균
- 박스플롯: sns.boxplot()
- x: category / y: numerical 분포
- 바이올린플롯: sns.violinplot()
- x: category / y: numerical 분포 & 양상
다시 tips 데이터셋에 대해 그래프를 그려보자.
1) Barplot (막대그래프)
x축엔 범주형 데이터를, y축엔 범주값에 따른 데이터의 평균값이 구해지는 막대그래프이다.
형태는 sns.barplot(x, y, data, estimator)
예를 들어, 성별 팁(tip)의 평균치가 어떻게 되는지 궁금하다고 할 때 막대그래프로 표현하면 다음과 같다.
# 성별 tip의 평균값
sns.barplot(x = 'sex', y = 'tip', data = tips)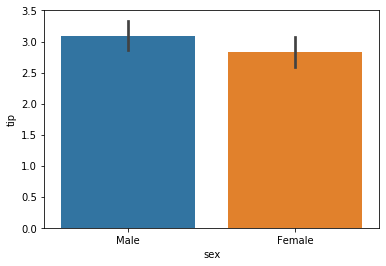
꼭 평균값으로만 계산되는 것은 아니다!
estimator 옵션에 원하는 지표를 넣어보자. 예를 들어, tip의 중위값이 궁금하다면?
# 성별 tip의 중위값
sns.barplot(x = 'sex', y = 'tip', data = tips, estimator = np.median)
이렇게 결과가 달라짐을 알 수 있다.(y축 값 확인)
참고로, bar 그래프의 위치를 거꾸로 놓고 싶다면 x와 y 위치를 바꾸면 된다.
## 그래프 가로로 그리기 -> x, y 위치 변경
# 성별 tip의 평균값
sns.barplot(y = 'sex', x = 'tip', data = tips)
2) Pointplot
포인트플롯은 barplot과 같은 기능이다. 똑같이 x축엔 범주형 데이터를, y축엔 범주에 따른 수치형 데이터의 평균값이 나온다.
다만 다른 점은 barplot은 Bar 모양으로 나오지만,
pointplot은 평균값이 점으로 찍히고 category별 값이 선으로 연결된다는 것이다.
형태는 sns.pointplot(x, y, data, estimator)
예를 들어 요일(day)별 total_bill의 평균값을 포인트플롯으로 그려보자.
# 요일(day)별 total_bill의 평균값
sns.pointplot(x = 'day', y = 'total_bill', data = tips)
마찬가지로 pointplot도 estimator를 이용해 꼭 평균값이 아닌 다른 지표를 활용할 수 있다.
(참고: 각 점 위아래에 길게 그려진 선은 신뢰구간이다)
예시로, 요일별 total_bill의 최댓값을 그려보자.
# 요일별 total_bill의 최댓값
sns.pointplot(x = 'day', y = 'total_bill', data = tips, estimator = np.max)
3) Boxplot
앞의 두 그래프(barplot, pointplot)은 y축이 전부 "평균값"을 보여주는 반면,
boxplot은 y축이 "분포"를 보여준다.
즉, x축에 범주형 데이터를, y축엔 범주에 따른 수치형 데이터의 분포 값이 나오게 된다.
형태는 sns.barplot(x, y, data)
식사시간(time)별 total_bill의 분포를 그려보자.
# 식사 시간(time)별 total_bill의 분포
sns.boxplot(x = 'time', y = 'total_bill', data = tips)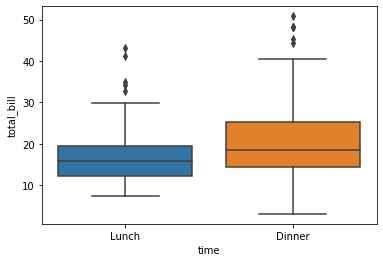
앞의 수치형 데이터에서도 boxplot이 나왔었는데,
이렇게 범주형 데이터와 수치형 데이터 둘의 관계를 확인할 때에도 boxplot이 쓰인다.
분포를 확인해보면, Lunch일 때와 Dinner일 때 total_bill(지불금액)의 중위값은 Dinner가 좀 더 높으며,
박스 크기가 Lunch가 좀 더 작으므로 Lunch 데이터가 중위수 근처에 몰린 데이터임을 알 수 있다.
마찬가지로 x, y의 위치를 바꾸면 그래프가 눕혀져서 그려진다.
# 그래프 눕히기 -> x, y 위치 변경
sns.boxplot(y = 'time', x = 'total_bill', data = tips)
4) Violinplot: Boxplot + kdeplot
boxplot은 분포를 확인하기에 좋지만 단점이 있다.
바로 "분산"이 어떤지 확인하기에 모호하다는 점이다.
이러한 분산 확인에 좋은 것이 바로 바이올린플롯이며, boxplot과 같지만 커널밀도함수 모양을 갖고 있는 그래프이다.
형태는 sns.violinplot(x, y, hue(범주형), data, split = False)
# time별 total_bill 분포
sns.violinplot(x= 'time', y = 'total_bill', data= tips)
앞서 time과 total_bill의 boxplot을 그렸었는데, 이번엔 violinplot으로 그려보았다.
참고로 바이올린플롯의 까만색 직사각형 모양이 Q1~Q3를 나타낸다. (가운데 흰색 점이 Q2=중위수)
그려진 바이올린플롯을 보면 분포를 좀 더 직관적으로 파악할 수 있다.
가장 중위수에 값이 몰린 것은 Lunch일 때라는 것을 한눈에 볼 수 있다.(가운데 쪽으로 볼록하게 튀어나왔으니까)
바이올린플롯의 또다른 좋은 점은 hue 옵션을 통해 분포를 나누어 볼 수 있다는 점이다.
성별에 따른 time별 total_bill의 분포를 뽑아보자.
# time별 total bill 분포 - 성별에 따라 다르게
sns.violinplot(x= 'time', y = 'total_bill', hue = 'sex', data = tips)
split = False가 디폴트이므로 True로 바꿔주면 그래프 모양이 달라진다.
#split 버전
sns.violinplot(x= 'time', y = 'total_bill', hue = 'sex', data = tips, split = True)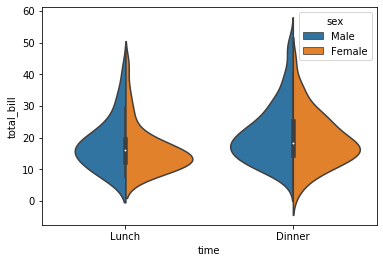
바로 이런 식으로, 성별에 따른 분포가 더 확연하게 보인다.
예를 들어 Lunch의 경우, 남성의 total_bill보다 여성의 total_bill이 더 중위수에 몰려 있는 분포임을 알 수 있다(그쪽으로 볼록 튀어나와 있으므로)
즉, 남성의 지불금액은 편차가 있는 데 비해, 여성의 지불금액은 좀 더 몰려 있다고 해석할 수 있다.
이렇게 하여 시각화 1편, 2편에서는 각각 수치형(numerical) 데이터를 갖고 시각화하는 방법, 그리고 범주형(categorical) 데이터를 갖고 시각화하는 방법을 알아보았다.
알아두면 EDA를 할 때 반드시 유용할 것이다. 정말 자주 쓰이는 그래프들만 정리했으니, 꼭 기억해두자!
다음 포스팅에서는 그래프를 그릴 때 하나가 아니라 여러 개를 동시에 그리는 경우가 많은데, plt.subplots를 활용해 쉽게 여러 그래프를 동시에 그리는 방법을 알아보자.
'Skillset > Python' 카테고리의 다른 글
| [pandas] pd.melt, pd.pivot_table을 활용해 데이터프레임 가공하기 (2) | 2022.06.17 |
|---|---|
| [시각화] 파이썬 EDA에 꼭 필요한 시각화 그래프 (3) plt.subplots 사용하기 (0) | 2022.06.16 |
| [시각화] 파이썬 EDA에 꼭 필요한 시각화 그래프 (1) 수치형 데이터 (0) | 2022.06.15 |
| python dlib 설치하기 - anaconda dlib install error (0) | 2022.04.23 |
| python cv2 AttributeError: 'Nonetype' object has no attribute 'shape' 해결법 (2) | 2022.04.22 |



