
Yours Ever, Data Chronicles
SQL CASE WHEN 구문 사용법 - 예제로 알아보기 본문
오늘은 SQL에서 매우 자주 쓰이는 CASE WHEN 구문에 대해 포스팅합니다.
CASE WHEN 구문은 SELECT절에 쓰이며, 대표적으로 2가지의 쓰임새가 있는데요!
1) 새로운 열을 생성하는 경우
SELECT CASE WHEN 기존 열 = 조건 THEN '값 1'
WHEN 기존 열 = 조건2 THEN '값 2'
....
(ELSE '값 N') END AS 새로운 열
2) 열을 집계하는 경우 (집계함수와 함께 사용) : 집계 열에 집계함수를 적용
SELECT 집계함수((DISTINCT) CASE WHEN 기존 열 = 조건 THEN 집계 열 (ELSE 값) END) AS 새로운 열
자주 사용하므로 반드시 알아야 하는 구문입니다. 바로 예제로 알아보겠습니다!
✔Table of Contents
예제 1.
1) 새로운 열 생성: 고객 세그먼트 나누기
EDU 데이터베이스의 [MEMBER] 라는 테이블을 활용합니다. 이 테이블은 이렇게 생겼습니다.
USE EDU
SELECT *
FROM [MEMBER]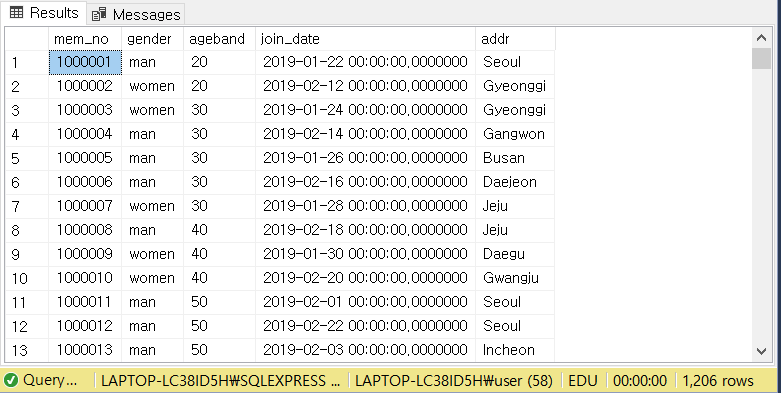
[MEMBER] 테이블은 회원정보 테이블이며, mem_no를 PK(Primary Key)로 가지며 이 열은 중복이 없습니다.
여기서 주의깊게 볼 것은 바로 ageband인데요,
고객의 연령대를 20대, 30대, .. 이런 식으로 나눠 놓았습니다.
ageband를 조금 더 단순화하여 고객을 나누는 고객 세그멘테이션(segmentation)을 진행해보려 합니다.
Q. ageband 값이 20~30이면 '2030', 40~50이면 '4050', 나머지는 'other'의 값을 갖는 새로운 열 [ageband_seg]를 만드시오.
이렇게 새로운 열을 만들 때 잘 활용할 수 있는 것이 CASE WHEN 입니다.
CASE WHEN을 사용하게 되면 기존에 있는 열의 조건에 따른 새로운 값을 갖는 새로운 열이 만들어지게 됩니다. 위 케이스의 경우엔 밑의 그림처럼 만들어진다고 보면 됩니다.

이제 CASE WHEN을 사용하여 위의 문제를 풀어봅시다.
SELECT *,
CASE WHEN ageband BETWEEN 20 AND 30 THEN '2030'
WHEN ageband BETWEEN 40 AND 50 THEN '4050'
ELSE 'other' END AS ageband_seg
FROM [MEMBER]
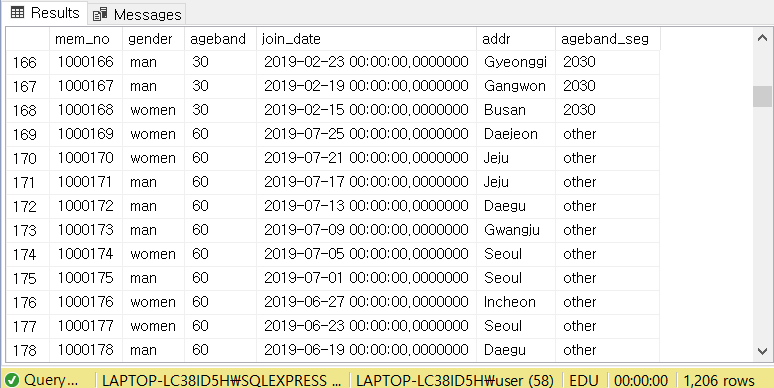
우리가 원하는 대로 결과가 잘 나왔음을 알 수 있습니다.
ELSE를 쓰지 않는 경우
참고로 ELSE는 꼭 쓸 필요가 없이 생략해도 상관없습니다.
위 경우 2030이나 4050이 아니면 전부 'other' 처리를 해주었는데, ELSE를 빼고 쓰면 전부 NULL 처리가 됩니다.
-- NOT USING "ELSE" -> it becomes 'NULL'
SELECT *,
CASE WHEN ageband BETWEEN 20 AND 30 THEN '2030'
WHEN ageband BETWEEN 40 AND 50 THEN '4050'
END AS ageband_seg
FROM [MEMBER]
2) 열 집계: 연도별 회원 수 계산
CASE WHEN의 두번째 쓰임새는 열을 집계하는 용도입니다.
예를 들어, 위의 [MEMBER] 테이블에서 성별 및 연령대별 회원수를 카운트한다면 어떻게 할까요?
SELECT gender, ageband, COUNT(mem_no) AS mem_cnt
FROM [MEMBER]
GROUP BY gender, ageband
ORDER BY 1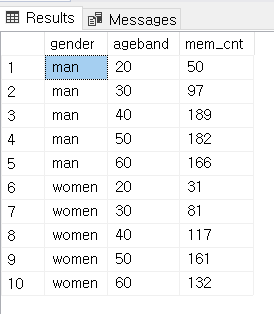
맞습니다. 잘 아시다시피, 간단히 GROUP BY를 통해 결과를 얻어낼 수 있죠.
하지만, "성별 및 연령대별로 카운트하되, join_date의 연도별로 나누어 회원 수를 카운트하시오." 라는 질문이라면 어떨까요?
여기서는 'gender(성별)', 'ageband(연령대)', 그리고 '2018년 가입자', '2019년 가입자' 이렇게 4개의 열이 만들어져야 한다면요?
이럴 때 GROUP BY를 대신하여 쉽게 집계할 수 있는 것이 CASE WHEN 입니다.
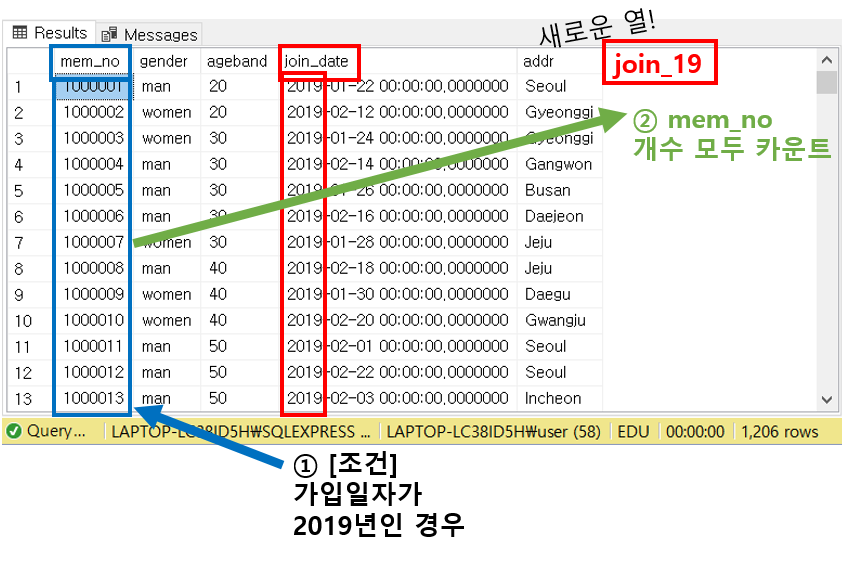
이런 식으로 2019년 가입자를 뜻하는 새로운 열 'join_19'는, join_date(가입일자)의 연도가 2019일 때의 mem_no의 개수를 센 값으로 들어옵니다.
물론 앞에 gender, ageband로 GROUP BY가 되어있다면 앞단에서 이게 먼저 그룹화되어 계산되겠죠!
SELECT gender, ageband,
COUNT(CASE WHEN YEAR(join_date) = 2018 THEN mem_no END) AS join_18,
COUNT(CASE WHEN YEAR(join_date) = 2019 THEN mem_no END) AS join_19
FROM [MEMBER]
GROUP BY gender, ageband
ORDER BY 1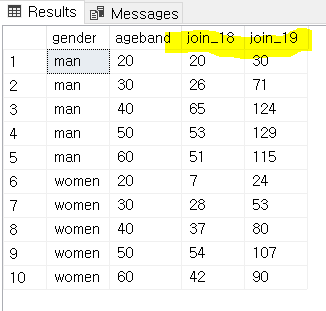
결과는 이렇게 기존의 mem_cnt로 계산된 것이, 2018년 가입자(join_18) / 2019년 가입자(join_19)로 나누어 집계됩니다! 정말 편리하죠?
예제 2.
1) 새로운 열 생성: 구매전환 여부 열 만들기
이번엔 새로운 테이블 [CAR_MART]를 가져와서 CASE WHEN을 활용해봅니다.
SELECT * FROM [CAR_MART]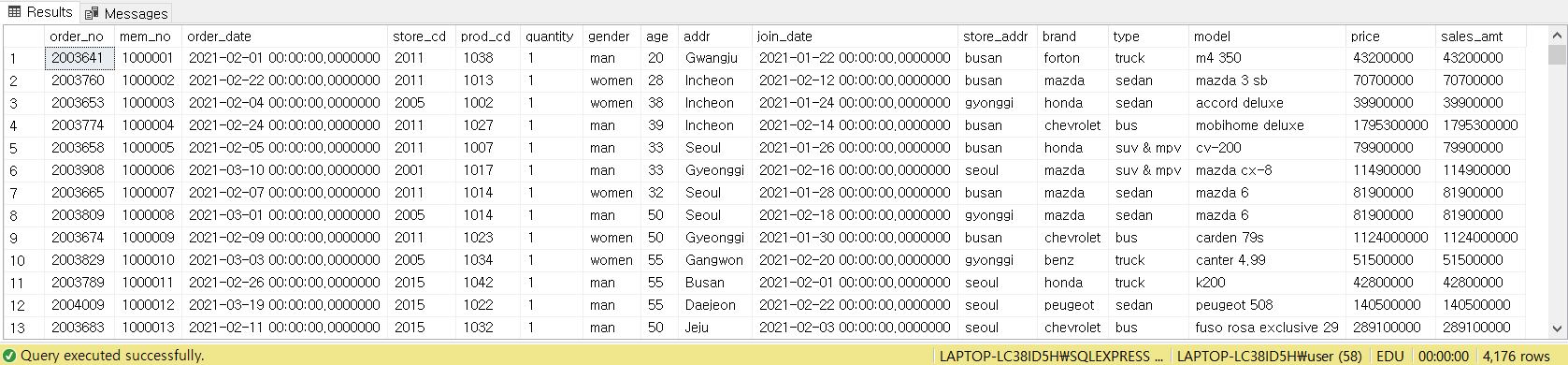
이 데이터는 자동차 구매에 관한 데이터이며, 주문한 내역에 고객과 상품코드, 상점코드 등으로 무엇을 구매했는지 알 수 있습니다.
여기서는 구매전환율을 구해보겠습니다.
이를 위해, 2020년에 구매한 고객이 2021년에도 구매한 경우 Y, 아니면 N을 표시하는 'retention' 열을 생성합니다.
먼저 이 데이터에서 2020년에 구매한 고객(mem_no)을 밑바탕으로 깔고, 그 옆에 2021년에 구매한 고객을 LEFT JOIN시키겠습니다. 왜냐하면 2020년을 기준으로, 21년에 구매했다면 값이 있을 것이고, 21년에 구매하지 않았다면 NULL로 조인될 테니까요.
SELECT *
FROM (SELECT DISTINCT mem_no FROM [CAR_MART] WHERE YEAR(order_date) = 2020) A
LEFT JOIN (SELECT DISTINCT mem_no FROM [CAR_MART] WHERE YEAR(order_date) = 2021) B
ON A.mem_no = B.mem_no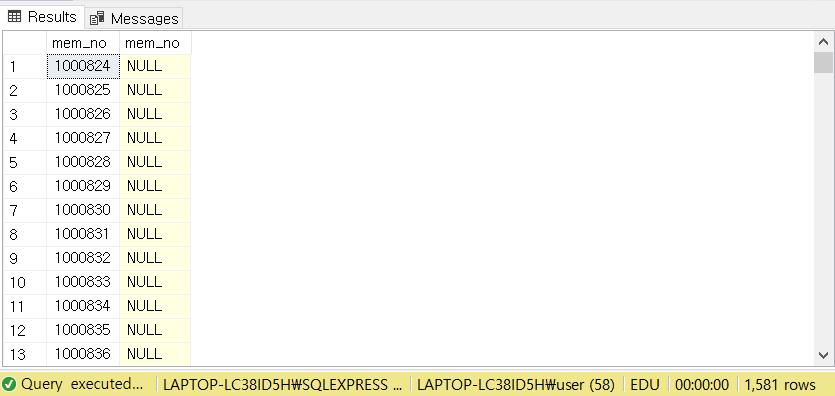
위와 같은 결과가 나옵니다. (참고로 [CAR_MART] 테이블은 mem_no가 여러번 구매할 경우 중복으로 찍히기 때문에 DISTINCT를 써서 집계합니다.)
결과를 좀 더 가공합니다. NULL로 나온거라면 전환이 안 된것이고(N), 값이 있으면 재구매를 한 것(Y)이겠죠?
이를 활용해 CASE WHEN 구문을 써줍니다.
SELECT A.mem_no AS mem_20, B.mem_no AS mem_21,
CASE WHEN B.mem_no IS NOT NULL THEN 'Y'
ELSE 'N' END AS retention
INTO #RETENTION_BASE
FROM (SELECT DISTINCT mem_no FROM [CAR_MART] WHERE YEAR(order_date) = 2020) A
LEFT JOIN (SELECT DISTINCT mem_no FROM [CAR_MART] WHERE YEAR(order_date) = 2021) B
ON A.mem_no = B.mem_no
SELECT * FROM #RETENTION_BASE
결과를 #RETENTION_BASE 라는 임시 세션 테이블에 저장하여 불러왔습니다.
테이블에 저장한 이유는 뒤의 연산(구매전환율 계산)을 하기 위함입니다. 아무튼, 전환여부를 알 수 있는 retention 열이 잘 만들어졌습니다.
2) 열 집계: 구매전환율 계산
이번에는 위의 #RETENTION_BASE를 활용해 구매전환율을 계산해봅니다.
계산은 간단합니다. 'retention' 열의 전체 개수에서 'Y'의 개수의 비율을 구하면 그것이 구매 전환율이겠죠?
먼저, 간단하게 GROUP BY를 활용하여 계산하면 이렇게 됩니다.
SELECT retention, COUNT(retention) AS re_cnt
FROM #RETENTION_BASE
GROUP BY retention
WITH ROLLUP
ORDER BY 1 DESC
구매전환이 된 것은 117개, 전체는 1,581개군요.
앞서 배운 그룹함수 GROUPING과 CASE WHEN을 사용하면, 'NULL' 값을 'total'로도 바꿀 수 있습니다.
SELECT CASE WHEN GROUPING(retention) = 1 THEN 'total' ELSE retention END AS 현황,
COUNT(retention) AS re_cnt
FROM #RETENTION_BASE
GROUP BY retention
WITH ROLLUP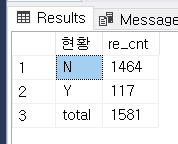
GROUP BY를 사용하여 전환된 것과 아닌 것의 개수를 셌다면, 이번엔 CASE WHEN 만 사용해서 집계를 해봅시다.
COUNT 집계함수를 활용해 retention이 'Y'인 것만 셉니다.
-- 또는 CASE WHEN을 사용하면
SELECT COUNT(*) AS total,
COUNT(CASE WHEN retention = 'Y' THEN retention END) AS re_y
FROM #RETENTION_BASE
또한 COUNT가 아니라 SUM 함수를 사용할 수도 있습니다.
조건에 retention이 'Y'이면 1로 두고 1을 전부 더하는 것입니다.
SELECT COUNT(*) AS total,
SUM(CASE WHEN retention = 'Y' THEN 1 ELSE 0 END) AS re_y
FROM #RETENTION_BASE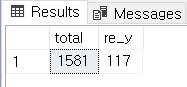
결과는 같습니다.
(번외편) SQL 상에서 전환 "비율"까지 구할 수 있을까?
그럼요! 하지만 집계함수 COUNT를 사용하면 안되고, SUM일 때만 가능합니다. (아마 MS-SQL이라서 그런 것 같습니다.. 빅쿼리에선 잘됩니다)
또한 COUNT(*) 를 분모에 사용할 때 형식을 FLOAT로 변경해주지 않으면 결과가 0으로 나오니 주의하세요!!
-- COUNT가 안먹기 때문에 SUM으로 바꿔서 써줘야 한다
SELECT ROUND((SUM(CASE WHEN retention = 'Y' THEN 1 ELSE 0 END)/ CAST(COUNT(*) AS FLOAT))*100, 2)
FROM #RETENTION_BASE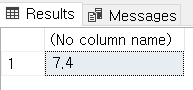
위와 같이 retention이 'Y'인 것의 비율은 약 7.4%입니다.
예전에 포스팅한 적 있었던 CONCAT과 CAST 함수도 함께 활용하면 SQL 상에서 7.4%로 나타낼 수 있습니다.
SELECT CONCAT(CAST(ROUND((SUM(CASE WHEN retention = 'Y' THEN 1 ELSE 0 END)/ CAST(COUNT(*) AS FLOAT))*100, 2) AS VARCHAR), '%')
FROM #RETENTION_BASE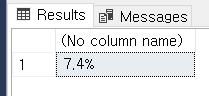
'Skillset > SQL' 카테고리의 다른 글
| SQL N번째 순위 추출하기(2번째로 큰 값, 상위 N개, 하위 N개 구하기) (1) | 2022.06.14 |
|---|---|
| [MS-SQL] 항목별 비율값 집계하기 (CAST, ROUND, CASE WHEN 구문) (0) | 2022.06.13 |
| SQL 효율화 및 자동화 명령어 - VIEW & PROCEDURE (2) | 2022.06.04 |
| SQL 집합 연산자 - UNION, UNION ALL, INTERSECT, EXCEPT (0) | 2022.06.03 |
| SQL 윈도우 함수 예제 - 순위함수(RANK), 누적 집계함수 (0) | 2022.06.02 |



