[pandas] pd.melt, pd.pivot_table을 활용해 데이터프레임 가공하기
오늘은 파이썬에서 데이터프레임(dataframe)을 가공하는 유용한 메서드인 pd.melt, pd.pivot_table에 대해 알아보자.
참고로 데이터셋&주피터 노트북 코드는 이 깃허브에 공유해두었습니다 :)
GitHub - suy379/python_for_DA: Python for Data Analysis (데이터 분석을 위한 중요한 파이썬 모음)
Python for Data Analysis (데이터 분석을 위한 중요한 파이썬 모음). Contribute to suy379/python_for_DA development by creating an account on GitHub.
github.com
✔Table of Contents
1. pd.melt
pd.melt(dataframe, id_vars, value_vars, var_name, value_name)
melt는 단어 그대로 '녹인다' 는 뜻이다. 즉, 데이터프레임 내의 데이터를 몰드에 녹여 새로운 데이터프레임의 형태로 가공한다고 보면 된다.
이 함수는 열이 길게 늘어져 있는 '넓은 데이터'에 특히 활용도가 높으며, 이러한 데이터에 melt 함수를 사용하면 여러 개의 열을 하나의 열 안에 다수의 행으로 넣어 가공된다.
(참고: id_vars, value_vars에 따라 value 값을 집계함수로 집계하는 기능은 X)
- id_vars: 위치를 유지할 열 이름(범주형)
- value_vars: 가공할 열 이름(범주형)
- 참고로 id_vars에 지정한 열 외에 나머지 열을 모두 가공할 것이라면 따로 지정할 필요 없음
- var_name: 가공되어 새로 만들어지는 열의 이름을 지정
- 선택사항. 지정하지 않으면 디폴트로 열 이름은 'variable'
- value_name: 가공할 열에 해당하는 수치형 데이터값(value)의 열 이름 지정
- 선택사항. 지정하지 않으면 디폴트로 열 이름은 'value'
바로 예제로 알아보자.
import pandas as pd
import seaborn as sns
# 데이터셋 따로 필요 (깃허브에서 다운)
pew = pd.read_csv('pew.csv')
pew.head()
religion 열은 종교이며, 그 오른쪽에 [<$10k부터 ~ Don't know/refused 열] 까지는 소득수준에 대해서이다.
즉, 각 종교 및 소득수준에 해당하는 사람들의 수를 카운트한 데이터이다.
여기서 소득수준에 대한 열이 너무 많다. 이렇게 열이 길게 늘어진 경우를 '넓은 데이터' 라고 하며,
이 10개의 열을 하나의 열로 넣어보자. 이 때 사용하는 것이 pd.melt
# religion 열은 그대로 / 나머지 소득수준 열은 'income' 이라는 하나의 열에 모두 집어넣기
pd.melt(pew, id_vars = 'religion',
var_name = 'income',
value_name = 'cnt')
길게 늘어져있던 10개의 열이 'income' 이라는 하나의 열에 들어왔다.
또한 각 종교와 소득수준에 해당하는 사람 수는 'cnt' 라는 열로 만들어졌다.
2. pd.pivot_table
pd.pivot_table(dataframe, index, columns, values, aggfunc)
pivot_table 함수는 정말 정말 많이 쓰이는 함수로 데이터 분석을 할 때 반드시 알아두어야 하는 함수이다.
index, columns로 지정한 값은 각각 행 인덱스, 열 인덱스가 된다.
앞에서 pd.melt는 id_vas, value_vars에 따라 values 값을 집계하는 기능이 없다고 했는데,
pd.pivot_table은 index, columns에 따라 values 값을 집계할 수 있다.
바로 aggfunc 옵션에 원하는 집계함수를 설정해주면 된다. (예를 들어, '평균', '합계', '중위수' 같은)
- index: 행 인덱스(범주형)
- columns: 열 인덱스(범주형)
- values: 피벗 대상 열 이름 (수치형)
- aggfunc: values를 집계할 때 사용할 집계함수 지정
- 평균은 'mean', 중위수는 'median', 합계는 'sum' 지정 (디폴트는 mean)
- 기본으로 제공하는 집계함수가 아닌 경우 넘파이(numpy)를 통해 지정 가능
- values로 지정할 열이 여러 개고, 각각에 다른 집계함수를 쓰고자 한다면 딕셔너리 형태로 넣기
여기서는 seaborn에서 제공하는 기본 데이터 'diamonds'를 사용하였다.
# seaborn에서 제공하는 데이터 사용
dia = sns.load_dataset('diamonds')
dia.head()
Q1. 다이아몬드의 cut과 color 상태에 따른 가격(price)의 평균을 구하시오.
dia_pivot1 = pd.pivot_table(dia, index = 'cut',
columns = 'color',
values = 'price')
dia_pivot1
행인덱스로는 cut, 열인덱스로는 color가 지정되었으며, 이 값에 따른 price(가격)의 평균값이 집계되었다.
aggfunc에 함수를 지정하지 않아도 디폴트가 평균(mean) 이므로 잘 집계되었다.
[참고] 피벗테이블의 좋은 점은 이렇게 만든 피벗테이블로 바로 히트맵을 만들 수도 있다!
sns.heatmap(dia_pivot1)
해석해보자면, 색이 옅어질수록 평균가격이 높다는 뜻이다.(우측의 colorbar 참고)
즉 cut 상태가 Premium일수록, color가 I, J에 가까울수록 가격이 높아진다.
Q2. 다이아몬드의 cut, color를 행인덱스 / clearity를 열인덱스로 하여 중위가격을 구하시오.
import numpy as np
dia_pivot2 = pd.pivot_table(dia, index = ['cut', 'color'],
columns = 'clarity',
values = 'price',
aggfunc = np.median)
dia_pivot2
이런 식으로 행인덱스나 열인덱스에 2개 이상의 변수를 지정하는 것도 가능하다.
이렇게 피벗테이블을 만들면 자동으로 행/열 인덱스가 설정된다고 하였다. 인덱스를 삭제하려면 reset_index를 사용한다.
dia_pivot2.reset_index(inplace = True)
dia_pivot2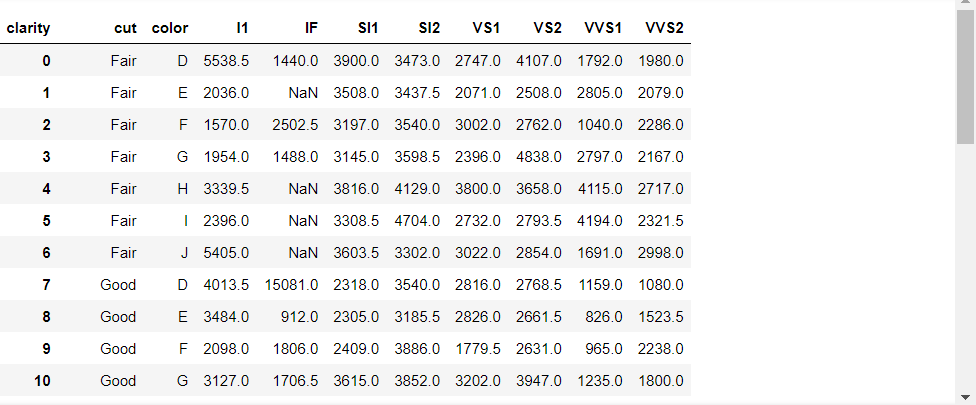
위의 결과를 보니, clarity의 값으로 여러 열이 만들어졌다. (다시 '넓은 데이터'가 되었다)
앞에서 배운 pd.melt를 활용해 데이터프레임을 가공하면
# 만들어진 것을 보니 다시 열이 길어진 '넓은 데이터'가 되었다. 열 'clarity'로 다시 만들기!
pd.melt(dia_pivot2, id_vars = ['cut', 'color'],
var_name = 'clarity',
value_name = 'med_value')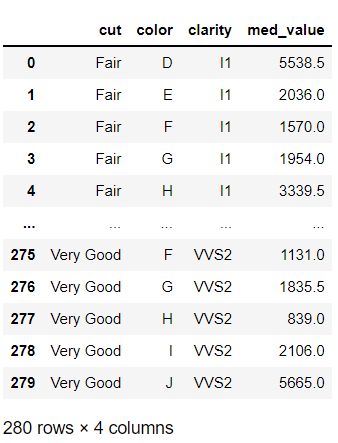
Q3. 다이아몬드의 cut, color에 따라, 가격(price)은 중위수 & 무게(carat)는 합계로 따로 집계하시오.
pd.pivot_table(dia, index = 'cut',
columns = 'color',
values = ['price', 'carat'],
aggfunc = {'price': 'median',
'carat': 'sum'})
이렇게 values에 지정한 열들에 각각 따로 집계함수를 지정하고 싶은 경우에는,
aggfunc 옵션에 딕셔너리로 각 변수별 어떤 집계함수를 사용할지를 지정해주면 된다!